 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Factor Augmented Neural Lasso for Heterogeneous Environments
Apr 14, 2026Fine-tuning is a widely used strategy for adapting pre-trained models to new tasks, yet its methodology and theoretical properties in high-dimensional nonparametric settings with variable selection have not yet been developed. This paper introduces the fine-tuning factor augmented neural Lasso (FAN-Lasso), a transfer learning framework for high-dimensional nonparametric regression with variable selection that simultaneously handles covariate and posterior shifts. We use a low-rank factor structure to manage high-dimensional dependent covariates and propose a novel residual fine-tuning decomposition in which the target function is expressed as a transformation of a frozen source function and other variables to achieve transfer learning and nonparametric variable selection. This augmented feature from the source predictor allows for the transfer of knowledge to the target domain and reduces model complexity there. We derive minimax-optimal excess risk bounds for the fine-tuning FAN-Lasso, characterizing the precise conditions, in terms of relative sample sizes and function complexities, under which fine-tuning yields statistical acceleration over single-task learning. The proposed framework also provides a theoretical perspective on parameter-efficient fine-tuning methods. Extensive numerical experiments across diverse covariate- and posterior-shift scenarios demonstrate that the fine-tuning FAN-Lasso consistently outperforms standard baselines and achieves near-oracle performance even under severe target sample size constraints, empirically validating the derived rates.
Optimal Demixing of Nonparametric Densities
Mar 29, 2026Motivated by applications in statistics and machine learning, we consider a problem of unmixing convex combinations of nonparametric densities. Suppose we observe $n$ groups of samples, where the $i$th group consists of $N_i$ independent samples from a $d$-variate density $f_i(x)=\sum_{k=1}^K π_i(k)g_k(x)$. Here, each $g_k(x)$ is a nonparametric density, and each $π_i$ is a $K$-dimensional mixed membership vector. We aim to estimate $g_1(x), \ldots,g_K(x)$. This problem generalizes topic modeling from discrete to continuous variables and finds its applications in LLMs with word embeddings. In this paper, we propose an estimator for the above problem, which modifies the classical kernel density estimator by assigning group-specific weights that are computed by topic modeling on histogram vectors and de-biased by U-statistics. For any $β>0$, assuming that each $g_k(x)$ is in the Nikol'ski class with a smooth parameter $β$, we show that the sum of integrated squared errors of the constructed estimators has a convergence rate that depends on $n$, $K$, $d$, and the per-group sample size $N$. We also provide a matching lower bound, which suggests that our estimator is rate-optimal.
How to Find Fantastic Papers: Self-Rankings as a Powerful Predictor of Scientific Impact Beyond Peer Review
Oct 02, 2025Peer review in academic research aims not only to ensure factual correctness but also to identify work of high scientific potential that can shape future research directions. This task is especially critical in fast-moving fields such as artificial intelligence (AI), yet it has become increasingly difficult given the rapid growth of submissions. In this paper, we investigate an underexplored measure for identifying high-impact research: authors' own rankings of their multiple submissions to the same AI conference. Grounded in game-theoretic reasoning, we hypothesize that self-rankings are informative because authors possess unique understanding of their work's conceptual depth and long-term promise. To test this hypothesis, we conducted a large-scale experiment at a leading AI conference, where 1,342 researchers self-ranked their 2,592 submissions by perceived quality. Tracking outcomes over more than a year, we found that papers ranked highest by their authors received twice as many citations as their lowest-ranked counterparts; self-rankings were especially effective at identifying highly cited papers (those with over 150 citations). Moreover, we showed that self-rankings outperformed peer review scores in predicting future citation counts. Our results remained robust after accounting for confounders such as preprint posting time and self-citations. Together, these findings demonstrate that authors' self-rankings provide a reliable and valuable complement to peer review for identifying and elevating high-impact research in AI.
Factor Informed Double Deep Learning For Average Treatment Effect Estimation
Aug 23, 2025We investigate the problem of estimating the average treatment effect (ATE) under a very general setup where the covariates can be high-dimensional, highly correlated, and can have sparse nonlinear effects on the propensity and outcome models. We present the use of a Double Deep Learning strategy for estimation, which involves combining recently developed factor-augmented deep learning-based estimators, FAST-NN, for both the response functions and propensity scores to achieve our goal. By using FAST-NN, our method can select variables that contribute to propensity and outcome models in a completely nonparametric and algorithmic manner and adaptively learn low-dimensional function structures through neural networks. Our proposed novel estimator, FIDDLE (Factor Informed Double Deep Learning Estimator), estimates ATE based on the framework of augmented inverse propensity weighting AIPW with the FAST-NN-based response and propensity estimates. FIDDLE consistently estimates ATE even under model misspecification and is flexible to also allow for low-dimensional covariates. Our method achieves semiparametric efficiency under a very flexible family of propensity and outcome models. We present extensive numerical studies on synthetic and real datasets to support our theoretical guarantees and establish the advantages of our methods over other traditional choices, especially when the data dimension is large.
Covariates-Adjusted Mixed-Membership Estimation: A Novel Network Model with Optimal Guarantees
Feb 10, 2025



This paper addresses the problem of mixed-membership estimation in networks, where the goal is to efficiently estimate the latent mixed-membership structure from the observed network. Recognizing the widespread availability and valuable information carried by node covariates, we propose a novel network model that incorporates both community information, as represented by the Degree-Corrected Mixed Membership (DCMM) model, and node covariate similarities to determine connections. We investigate the regularized maximum likelihood estimation (MLE) for this model and demonstrate that our approach achieves optimal estimation accuracy for both the similarity matrix and the mixed-membership, in terms of both the Frobenius norm and the entrywise loss. Since directly analyzing the original convex optimization problem is intractable, we employ nonconvex optimization to facilitate the analysis. A key contribution of our work is identifying a crucial assumption that bridges the gap between convex and nonconvex solutions, enabling the transfer of statistical guarantees from the nonconvex approach to its convex counterpart. Importantly, our analysis extends beyond the MLE loss and the mean squared error (MSE) used in matrix completion problems, generalizing to all the convex loss functions. Consequently, our analysis techniques extend to a broader set of applications, including ranking problems based on pairwise comparisons. Finally, simulation experiments validate our theoretical findings, and real-world data analyses confirm the practical relevance of our model.
Transformers versus the EM Algorithm in Multi-class Clustering
Feb 09, 2025LLMs demonstrate significant inference capacities in complicated machine learning tasks, using the Transformer model as its backbone. Motivated by the limited understanding of such models on the unsupervised learning problems, we study the learning guarantees of Transformers in performing multi-class clustering of the Gaussian Mixture Models. We develop a theory drawing strong connections between the Softmax Attention layers and the workflow of the EM algorithm on clustering the mixture of Gaussians. Our theory provides approximation bounds for the Expectation and Maximization steps by proving the universal approximation abilities of multivariate mappings by Softmax functions. In addition to the approximation guarantees, we also show that with a sufficient number of pre-training samples and an initialization, Transformers can achieve the minimax optimal rate for the problem considered. Our extensive simulations empirically verified our theory by revealing the strong learning capacities of Transformers even beyond the assumptions in the theory, shedding light on the powerful inference capacities of LLMs.
Transformers and Their Roles as Time Series Foundation Models
Feb 05, 2025



We give a comprehensive analysis of transformers as time series foundation models, focusing on their approximation and generalization capabilities. First, we demonstrate that there exist transformers that fit an autoregressive model on input univariate time series via gradient descent. We then analyze MOIRAI, a multivariate time series foundation model capable of handling an arbitrary number of covariates. We prove that it is capable of automatically fitting autoregressive models with an arbitrary number of covariates, offering insights into its design and empirical success. For generalization, we establish bounds for pretraining when the data satisfies Dobrushin's condition. Experiments support our theoretical findings, highlighting the efficacy of transformers as time series foundation models.
Fundamental Computational Limits in Pursuing Invariant Causal Prediction and Invariance-Guided Regularization
Jan 29, 2025



Pursuing invariant prediction from heterogeneous environments opens the door to learning causality in a purely data-driven way and has several applications in causal discovery and robust transfer learning. However, existing methods such as ICP [Peters et al., 2016] and EILLS [Fan et al., 2024] that can attain sample-efficient estimation are based on exponential time algorithms. In this paper, we show that such a problem is intrinsically hard in computation: the decision problem, testing whether a non-trivial prediction-invariant solution exists across two environments, is NP-hard even for the linear causal relationship. In the world where P$\neq$NP, our results imply that the estimation error rate can be arbitrarily slow using any computationally efficient algorithm. This suggests that pursuing causality is fundamentally harder than detecting associations when no prior assumption is pre-offered. Given there is almost no hope of computational improvement under the worst case, this paper proposes a method capable of attaining both computationally and statistically efficient estimation under additional conditions. Furthermore, our estimator is a distributionally robust estimator with an ellipse-shaped uncertain set where more uncertainty is placed on spurious directions than invariant directions, resulting in a smooth interpolation between the most predictive solution and the causal solution by varying the invariance hyper-parameter. Non-asymptotic results and empirical applications support the claim.
Deep Transfer $Q$-Learning for Offline Non-Stationary Reinforcement Learning
Jan 08, 2025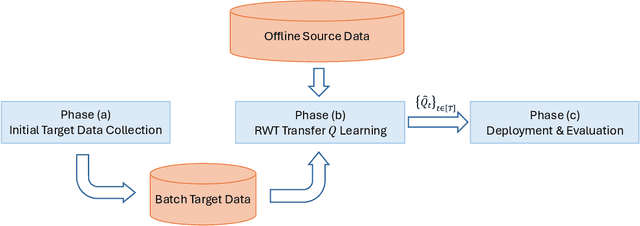

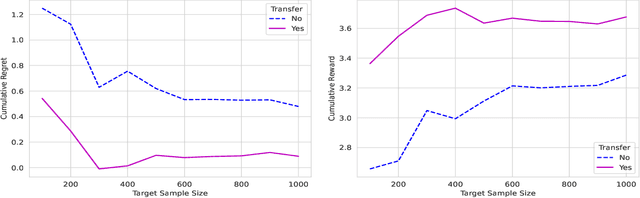
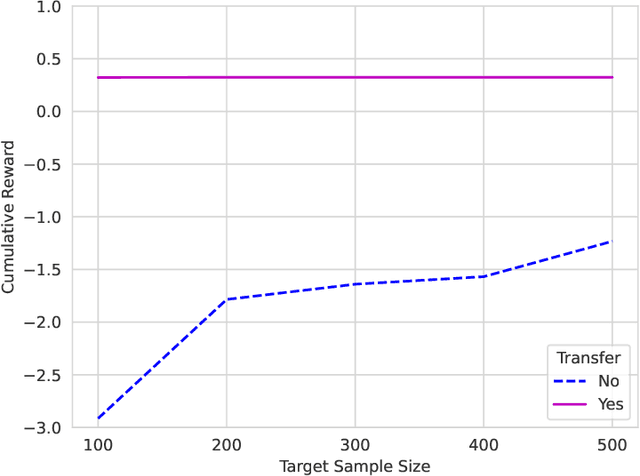
In dynamic decision-making scenarios across business and healthcare, leveraging sample trajectories from diverse populations can significantly enhance reinforcement learning (RL) performance for specific target populations, especially when sample sizes are limited. While existing transfer learning methods primarily focus on linear regression settings, they lack direct applicability to reinforcement learning algorithms. This paper pioneers the study of transfer learning for dynamic decision scenarios modeled by non-stationary finite-horizon Markov decision processes, utilizing neural networks as powerful function approximators and backward inductive learning. We demonstrate that naive sample pooling strategies, effective in regression settings, fail in Markov decision processes.To address this challenge, we introduce a novel ``re-weighted targeting procedure'' to construct ``transferable RL samples'' and propose ``transfer deep $Q^*$-learning'', enabling neural network approximation with theoretical guarantees. We assume that the reward functions are transferable and deal with both situations in which the transition densities are transferable or nontransferable. Our analytical techniques for transfer learning in neural network approximation and transition density transfers have broader implications, extending to supervised transfer learning with neural networks and domain shift scenarios. Empirical experiments on both synthetic and real datasets corroborate the advantages of our method, showcasing its potential for improving decision-making through strategically constructing transferable RL samples in non-stationary reinforcement learning contexts.
Transformers Simulate MLE for Sequence Generation in Bayesian Networks
Jan 05, 2025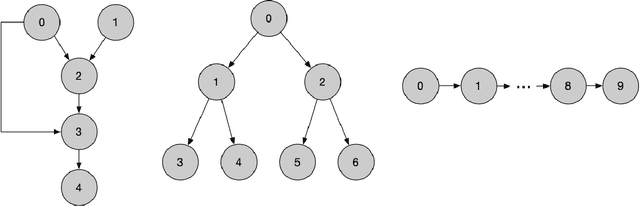

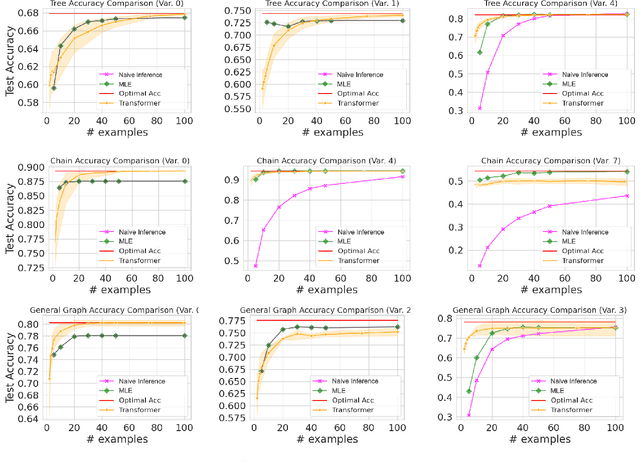
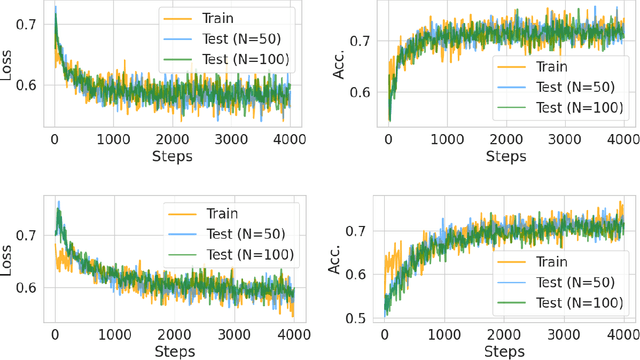
Transformers have achieved significant success in various fields, notably excelling in tasks involving sequential data like natural language processing. Despite these achievements, the theoretical understanding of transformers' capabilities remains limited. In this paper, we investigate the theoretical capabilities of transformers to autoregressively generate sequences in Bayesian networks based on in-context maximum likelihood estimation (MLE). Specifically, we consider a setting where a context is formed by a set of independent sequences generated according to a Bayesian network. We demonstrate that there exists a simple transformer model that can (i) estimate the conditional probabilities of the Bayesian network according to the context, and (ii) autoregressively generate a new sample according to the Bayesian network with estimated conditional probabilities. We further demonstrate in extensive experiments that such a transformer does not only exist in theory, but can also be effectively obtained through training. Our analysis highlights the potential of transformers to learn complex probabilistic models and contributes to a better understanding of large language models as a powerful class of sequence generators.