 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne-Layer Transformer Provably Learns One-Nearest Neighbor In Context
Paper and Code
Nov 16, 2024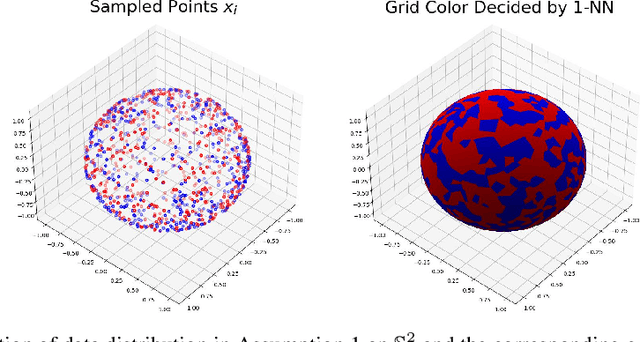
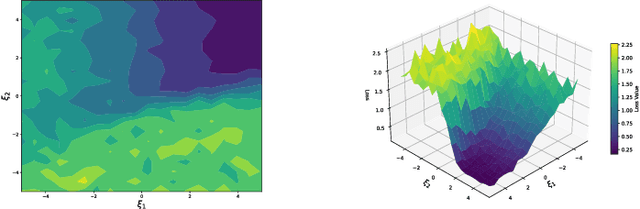
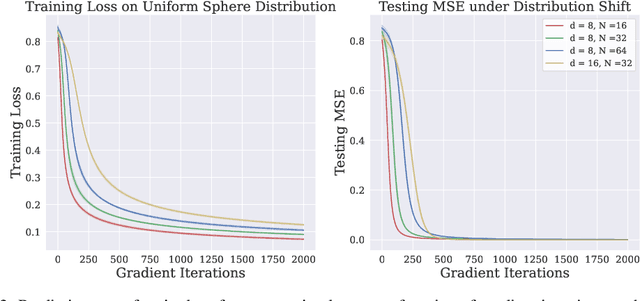
Transformers have achieved great success in recent years. Interestingly, transformers have shown particularly strong in-context learning capability -- even without fine-tuning, they are still able to solve unseen tasks well purely based on task-specific prompts. In this paper, we study the capability of one-layer transformers in learning one of the most classical nonparametric estimators, the one-nearest neighbor prediction rule. Under a theoretical framework where the prompt contains a sequence of labeled training data and unlabeled test data, we show that, although the loss function is nonconvex when trained with gradient descent, a single softmax attention layer can successfully learn to behave like a one-nearest neighbor classifier. Our result gives a concrete example of how transformers can be trained to implement nonparametric machine learning algorithms, and sheds light on the role of softmax attention in transformer models.