 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeconstructing the Failure of Ideal Noise Correction: A Three-Pillar Diagnosis
Mar 13, 2026Statistically consistent methods based on the noise transition matrix ($T$) offer a theoretically grounded solution to Learning with Noisy Labels (LNL), with guarantees of convergence to the optimal clean-data classifier. In practice, however, these methods are often outperformed by empirical approaches such as sample selection, and this gap is usually attributed to the difficulty of accurately estimating $T$. The common assumption is that, given a perfect $T$, noise-correction methods would recover their theoretical advantage. In this work, we put this longstanding hypothesis to a decisive test. We conduct experiments under idealized conditions, providing correction methods with a perfect, oracle transition matrix. Even under these ideal conditions, we observe that these methods still suffer from performance collapse during training. This compellingly demonstrates that the failure is not fundamentally a $T$-estimation problem, but stems from a more deeply rooted flaw. To explain this behaviour, we provide a unified analysis that links three levels: macroscopic convergence states, microscopic optimisation dynamics, and information-theoretic limits on what can be learned from noisy labels. Together, these results give a formal account of why ideal noise correction fails and offer concrete guidance for designing more reliable methods for learning with noisy labels.
OA-NBV: Occlusion-Aware Next-Best-View Planning for Human-Centered Active Perception on Mobile Robots
Mar 10, 2026We naturally step sideways or lean to see around the obstacle when our view is blocked, and recover a more informative observation. Enabling robots to make the same kind of viewpoint choice is critical for human-centered operations, including search, triage, and disaster response, where cluttered environments and partial visibility frequently degrade downstream perception. However, many Next-Best-View (NBV) methods primarily optimize generic exploration or long-horizon coverage, and do not explicitly target the immediate goal of obtaining a single usable observation of a partially occluded person under real motion constraints. We present Occlusion-Aware Next-Best-View Planning for Human-Centered Active Perception on Mobile Robots (OA-NBV), an occlusion-aware NBV pipeline that autonomously selects the next traversable viewpoint to obtain a more complete view of an occluded human. OA-NBV integrates perception and motion planning by scoring candidate viewpoints using a target-centric visibility model that accounts for occlusion, target scale, and target completeness, while restricting candidates to feasible robot poses. OA-NBV achieves over 90% success rate in both simulation and real-world trials, while baseline NBV methods degrade sharply under occlusion. Beyond success rate, OA-NBV improves observation quality: compared to the strongest baseline, it increases normalized target area by at least 81% and keypoint visibility by at least 58% across settings, making it a drop-in view-selection module for diverse human-centered downstream tasks.
D^3ETOR: Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing for Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jan 06, 2026Weakly-Supervised Camouflaged Object Detection (WSCOD) aims to locate and segment objects that are visually concealed within their surrounding scenes, relying solely on sparse supervision such as scribble annotations. Despite recent progress, existing WSCOD methods still lag far behind fully supervised ones due to two major limitations: (1) the pseudo masks generated by general-purpose segmentation models (e.g., SAM) and filtered via rules are often unreliable, as these models lack the task-specific semantic understanding required for effective pseudo labeling in COD; and (2) the neglect of inherent annotation bias in scribbles, which hinders the model from capturing the global structure of camouflaged objects. To overcome these challenges, we propose ${D}^{3}$ETOR, a two-stage WSCOD framework consisting of Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing. In the first stage, we introduce an adaptive entropy-driven point sampling method and a multi-agent debate mechanism to enhance the capability of SAM for COD, improving the interpretability and precision of pseudo masks. In the second stage, we design FADeNet, which progressively fuses multi-level frequency-aware features to balance global semantic understanding with local detail modeling, while dynamically reweighting supervision strength across regions to alleviate scribble bias. By jointly exploiting the supervision signals from both the pseudo masks and scribble semantics, ${D}^{3}$ETOR significantly narrows the gap between weakly and fully supervised COD, achieving state-of-the-art performance on multiple benchmarks.
${D}^{3}${ETOR}: ${D}$ebate-Enhanced Pseudo Labeling and Frequency-Aware Progressive ${D}$ebiasing for Weakly-Supervised Camouflaged Object ${D}$etection with Scribble Annotations
Dec 23, 2025Weakly-Supervised Camouflaged Object Detection (WSCOD) aims to locate and segment objects that are visually concealed within their surrounding scenes, relying solely on sparse supervision such as scribble annotations. Despite recent progress, existing WSCOD methods still lag far behind fully supervised ones due to two major limitations: (1) the pseudo masks generated by general-purpose segmentation models (e.g., SAM) and filtered via rules are often unreliable, as these models lack the task-specific semantic understanding required for effective pseudo labeling in COD; and (2) the neglect of inherent annotation bias in scribbles, which hinders the model from capturing the global structure of camouflaged objects. To overcome these challenges, we propose ${D}^{3}$ETOR, a two-stage WSCOD framework consisting of Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing. In the first stage, we introduce an adaptive entropy-driven point sampling method and a multi-agent debate mechanism to enhance the capability of SAM for COD, improving the interpretability and precision of pseudo masks. In the second stage, we design FADeNet, which progressively fuses multi-level frequency-aware features to balance global semantic understanding with local detail modeling, while dynamically reweighting supervision strength across regions to alleviate scribble bias. By jointly exploiting the supervision signals from both the pseudo masks and scribble semantics, ${D}^{3}$ETOR significantly narrows the gap between weakly and fully supervised COD, achieving state-of-the-art performance on multiple benchmarks.
Frontier LLMs Still Struggle with Simple Reasoning Tasks
Jul 09, 2025
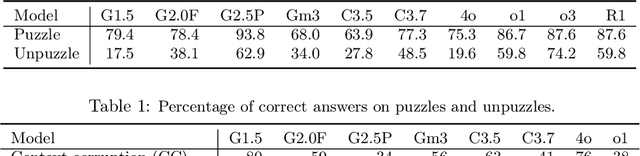
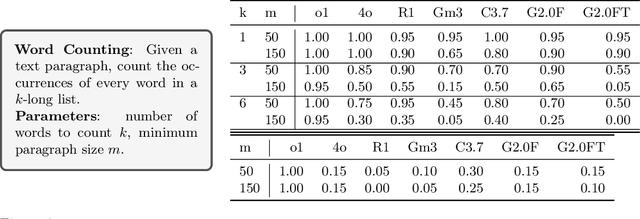
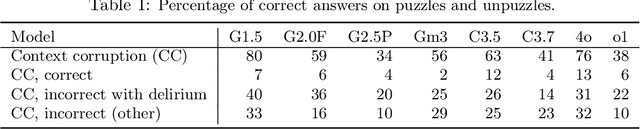
While state-of-the-art large language models (LLMs) demonstrate advanced reasoning capabilities-achieving remarkable performance on challenging competitive math and coding benchmarks-they also frequently fail on tasks that are easy for humans. This work studies the performance of frontier LLMs on a broad set of such "easy" reasoning problems. By extending previous work in the literature, we create a suite of procedurally generated simple reasoning tasks, including counting, first-order logic, proof trees, and travel planning, with changeable parameters (such as document length. or the number of variables in a math problem) that can arbitrarily increase the amount of computation required to produce the answer while preserving the fundamental difficulty. While previous work showed that traditional, non-thinking models can be made to fail on such problems, we demonstrate that even state-of-the-art thinking models consistently fail on such problems and for similar reasons (e.g. statistical shortcuts, errors in intermediate steps, and difficulties in processing long contexts). To further understand the behavior of the models, we introduce the unpuzzles dataset, a different "easy" benchmark consisting of trivialized versions of well-known math and logic puzzles. Interestingly, while modern LLMs excel at solving the original puzzles, they tend to fail on the trivialized versions, exhibiting several systematic failure patterns related to memorizing the originals. We show that this happens even if the models are otherwise able to solve problems with different descriptions but requiring the same logic. Our results highlight that out-of-distribution generalization is still problematic for frontier language models and the new generation of thinking models, even for simple reasoning tasks, and making tasks easier does not necessarily imply improved performance.
Principled Out-of-Distribution Generalization via Simplicity
May 28, 2025Modern foundation models exhibit remarkable out-of-distribution (OOD) generalization, solving tasks far beyond the support of their training data. However, the theoretical principles underpinning this phenomenon remain elusive. This paper investigates this problem by examining the compositional generalization abilities of diffusion models in image generation. Our analysis reveals that while neural network architectures are expressive enough to represent a wide range of models -- including many with undesirable behavior on OOD inputs -- the true, generalizable model that aligns with human expectations typically corresponds to the simplest among those consistent with the training data. Motivated by this observation, we develop a theoretical framework for OOD generalization via simplicity, quantified using a predefined simplicity metric. We analyze two key regimes: (1) the constant-gap setting, where the true model is strictly simpler than all spurious alternatives by a fixed gap, and (2) the vanishing-gap setting, where the fixed gap is replaced by a smoothness condition ensuring that models close in simplicity to the true model yield similar predictions. For both regimes, we study the regularized maximum likelihood estimator and establish the first sharp sample complexity guarantees for learning the true, generalizable, simple model.
Towards Fluorescence-Guided Autonomous Robotic Partial Nephrectomy on Novel Tissue-Mimicking Hydrogel Phantoms
Mar 04, 2025Autonomous robotic systems hold potential for improving renal tumor resection accuracy and patient outcomes. We present a fluorescence-guided robotic system capable of planning and executing incision paths around exophytic renal tumors with a clinically relevant resection margin. Leveraging point cloud observations, the system handles irregular tumor shapes and distinguishes healthy from tumorous tissue based on near-infrared imaging, akin to indocyanine green staining in partial nephrectomy. Tissue-mimicking phantoms are crucial for the development of autonomous robotic surgical systems for interventions where acquiring ex-vivo animal tissue is infeasible, such as cancer of the kidney and renal pelvis. To this end, we propose novel hydrogel-based kidney phantoms with exophytic tumors that mimic the physical and visual behavior of tissue, and are compatible with electrosurgical instruments, a common limitation of silicone-based phantoms. In contrast to previous hydrogel phantoms, we mix the material with near-infrared dye to enable fluorescence-guided tumor segmentation. Autonomous real-world robotic experiments validate our system and phantoms, achieving an average margin accuracy of 1.44 mm in a completion time of 69 sec.
MATH-Perturb: Benchmarking LLMs' Math Reasoning Abilities against Hard Perturbations
Feb 10, 2025



Large language models have demonstrated impressive performance on challenging mathematical reasoning tasks, which has triggered the discussion of whether the performance is achieved by true reasoning capability or memorization. To investigate this question, prior work has constructed mathematical benchmarks when questions undergo simple perturbations -- modifications that still preserve the underlying reasoning patterns of the solutions. However, no work has explored hard perturbations, which fundamentally change the nature of the problem so that the original solution steps do not apply. To bridge the gap, we construct MATH-P-Simple and MATH-P-Hard via simple perturbation and hard perturbation, respectively. Each consists of 279 perturbed math problems derived from level-5 (hardest) problems in the MATH dataset (Hendrycksmath et. al., 2021). We observe significant performance drops on MATH-P-Hard across various models, including o1-mini (-16.49%) and gemini-2.0-flash-thinking (-12.9%). We also raise concerns about a novel form of memorization where models blindly apply learned problem-solving skills without assessing their applicability to modified contexts. This issue is amplified when using original problems for in-context learning. We call for research efforts to address this challenge, which is critical for developing more robust and reliable reasoning models.
Covariates-Adjusted Mixed-Membership Estimation: A Novel Network Model with Optimal Guarantees
Feb 10, 2025



This paper addresses the problem of mixed-membership estimation in networks, where the goal is to efficiently estimate the latent mixed-membership structure from the observed network. Recognizing the widespread availability and valuable information carried by node covariates, we propose a novel network model that incorporates both community information, as represented by the Degree-Corrected Mixed Membership (DCMM) model, and node covariate similarities to determine connections. We investigate the regularized maximum likelihood estimation (MLE) for this model and demonstrate that our approach achieves optimal estimation accuracy for both the similarity matrix and the mixed-membership, in terms of both the Frobenius norm and the entrywise loss. Since directly analyzing the original convex optimization problem is intractable, we employ nonconvex optimization to facilitate the analysis. A key contribution of our work is identifying a crucial assumption that bridges the gap between convex and nonconvex solutions, enabling the transfer of statistical guarantees from the nonconvex approach to its convex counterpart. Importantly, our analysis extends beyond the MLE loss and the mean squared error (MSE) used in matrix completion problems, generalizing to all the convex loss functions. Consequently, our analysis techniques extend to a broader set of applications, including ranking problems based on pairwise comparisons. Finally, simulation experiments validate our theoretical findings, and real-world data analyses confirm the practical relevance of our model.
Tracking Tumors under Deformation from Partial Point Clouds using Occupancy Networks
Nov 04, 2024



To track tumors during surgery, information from preoperative CT scans is used to determine their position. However, as the surgeon operates, the tumor may be deformed which presents a major hurdle for accurately resecting the tumor, and can lead to surgical inaccuracy, increased operation time, and excessive margins. This issue is particularly pronounced in robot-assisted partial nephrectomy (RAPN), where the kidney undergoes significant deformations during operation. Toward addressing this, we introduce a occupancy network-based method for the localization of tumors within kidney phantoms undergoing deformations at interactive speeds. We validate our method by introducing a 3D hydrogel kidney phantom embedded with exophytic and endophytic renal tumors. It closely mimics real tissue mechanics to simulate kidney deformation during in vivo surgery, providing excellent contrast and clear delineation of tumor margins to enable automatic threshold-based segmentation. Our findings indicate that the proposed method can localize tumors in moderately deforming kidneys with a margin of 6mm to 10mm, while providing essential volumetric 3D information at over 60Hz. This capability directly enables downstream tasks such as robotic resection.