 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrderChain: A General Prompting Paradigm to Improve Ordinal Understanding Ability of MLLM
Apr 07, 2025Despite the remarkable progress of multimodal large language models (MLLMs), they continue to face challenges in achieving competitive performance on ordinal regression (OR; a.k.a. ordinal classification). To address this issue, this paper presents OrderChain, a novel and general prompting paradigm that improves the ordinal understanding ability of MLLMs by specificity and commonality modeling. Specifically, our OrderChain consists of a set of task-aware prompts to facilitate the specificity modeling of diverse OR tasks and a new range optimization Chain-of-Thought (RO-CoT), which learns a commonality way of thinking about OR tasks by uniformly decomposing them into multiple small-range optimization subtasks. Further, we propose a category recursive division (CRD) method to generate instruction candidate category prompts to support RO-CoT automatic optimization. Comprehensive experiments show that a Large Language and Vision Assistant (LLaVA) model with our OrderChain improves baseline LLaVA significantly on diverse OR datasets, e.g., from 47.5% to 93.2% accuracy on the Adience dataset for age estimation, and from 30.0% to 85.7% accuracy on the Diabetic Retinopathy dataset. Notably, LLaVA with our OrderChain also remarkably outperforms state-of-the-art methods by 27% on accuracy and 0.24 on MAE on the Adience dataset. To our best knowledge, our OrderChain is the first work that augments MLLMs for OR tasks, and the effectiveness is witnessed across a spectrum of OR datasets.
A Survey on Ordinal Regression: Applications, Advances and Prospects
Mar 02, 2025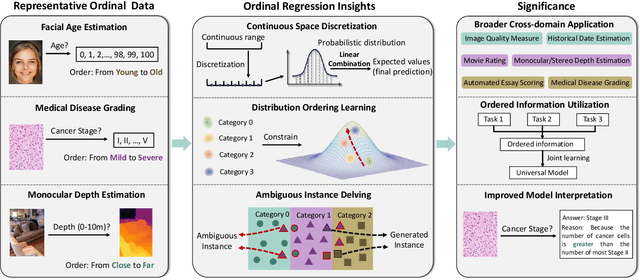
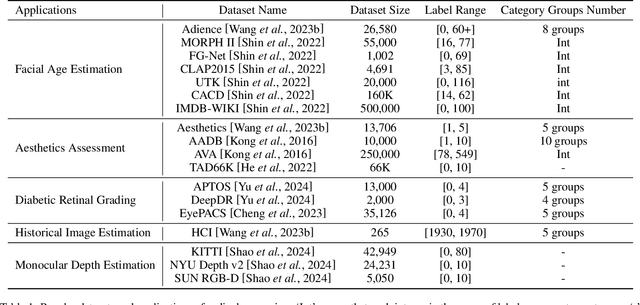
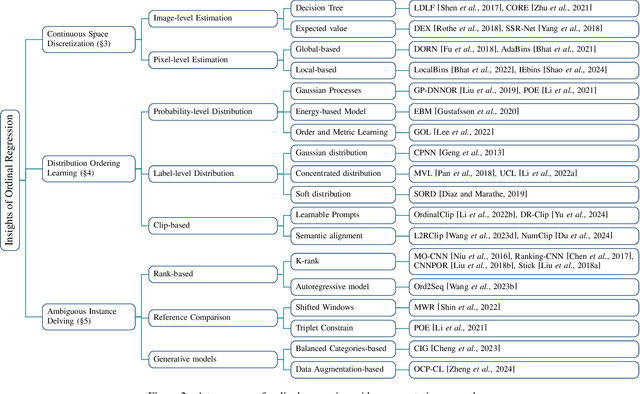
Ordinal regression refers to classifying object instances into ordinal categories. Ordinal regression is crucial for applications in various areas like facial age estimation, image aesthetics assessment, and even cancer staging, due to its capability to utilize ordered information effectively. More importantly, it also enhances model interpretation by considering category order, aiding the understanding of data trends and causal relationships. Despite significant recent progress, challenges remain, and further investigation of ordinal regression techniques and applications is essential to guide future research. In this survey, we present a comprehensive examination of advances and applications of ordinal regression. By introducing a systematic taxonomy, we meticulously classify the pertinent techniques and applications into three well-defined categories based on different strategies and objectives: Continuous Space Discretization, Distribution Ordering Learning, and Ambiguous Instance Delving. This categorization enables a structured exploration of diverse insights in ordinal regression problems, providing a framework for a more comprehensive understanding and evaluation of this field and its related applications. To our best knowledge, this is the first systematic survey of ordinal regression, which lays a foundation for future research in this fundamental and generic domain.
Scalable Autoregressive Monocular Depth Estimation
Nov 18, 2024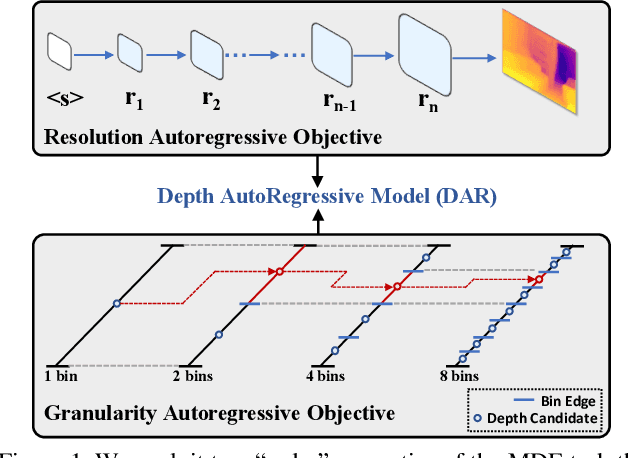
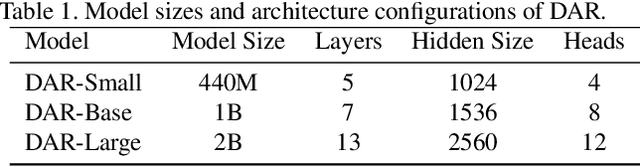
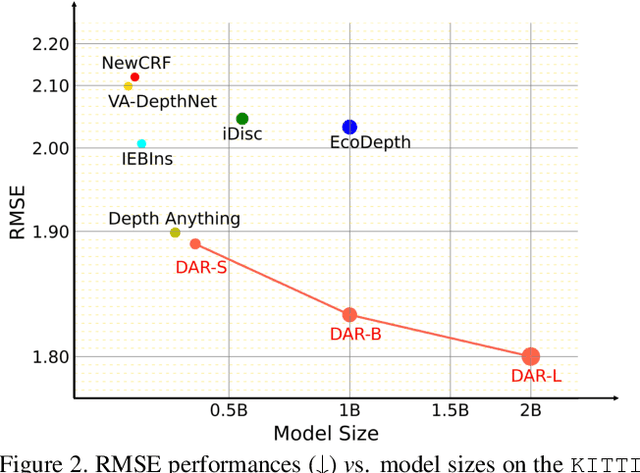
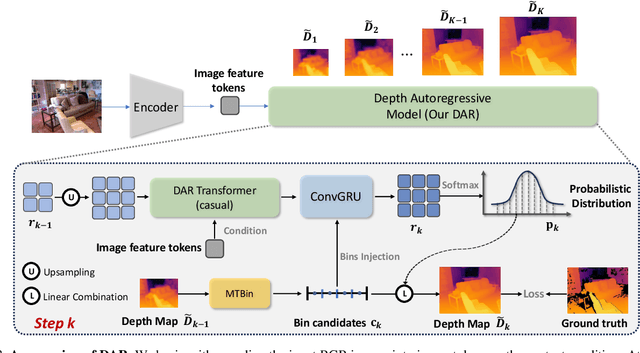
This paper proposes a new autoregressive model as an effective and scalable monocular depth estimator. Our idea is simple: We tackle the monocular depth estimation (MDE) task with an autoregressive prediction paradigm, based on two core designs. First, our depth autoregressive model (DAR) treats the depth map of different resolutions as a set of tokens, and conducts the low-to-high resolution autoregressive objective with a patch-wise casual mask. Second, our DAR recursively discretizes the entire depth range into more compact intervals, and attains the coarse-to-fine granularity autoregressive objective in an ordinal-regression manner. By coupling these two autoregressive objectives, our DAR establishes new state-of-the-art (SOTA) on KITTI and NYU Depth v2 by clear margins. Further, our scalable approach allows us to scale the model up to 2.0B and achieve the best RMSE of 1.799 on the KITTI dataset (5% improvement) compared to 1.896 by the current SOTA (Depth Anything). DAR further showcases zero-shot generalization ability on unseen datasets. These results suggest that DAR yields superior performance with an autoregressive prediction paradigm, providing a promising approach to equip modern autoregressive large models (e.g., GPT-4o) with depth estimation capabilities.
TokenPacker: Efficient Visual Projector for Multimodal LLM
Jul 02, 2024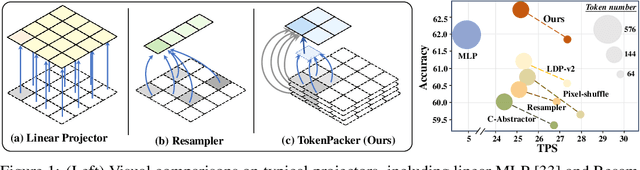
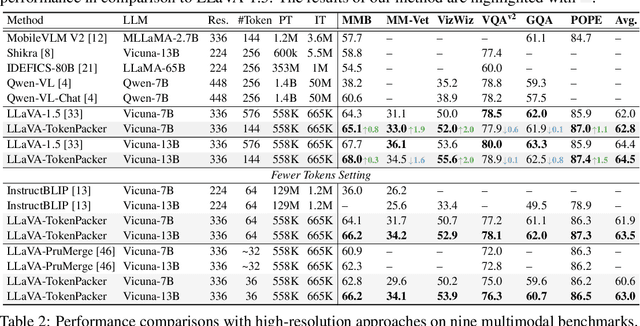
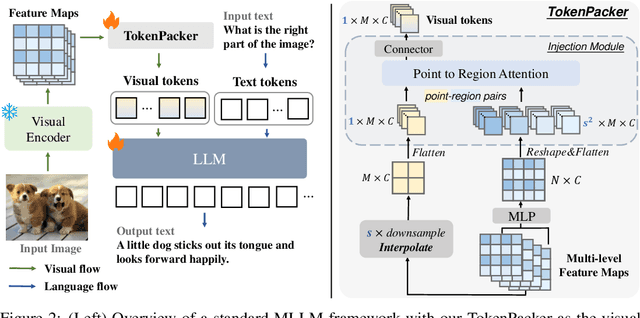
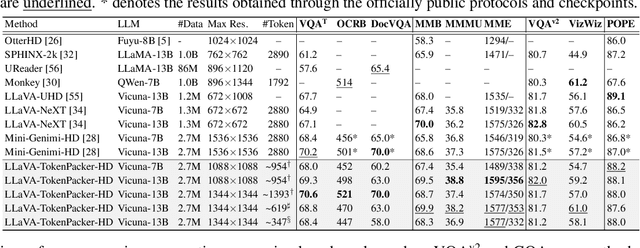
The visual projector serves as an essential bridge between the visual encoder and the Large Language Model (LLM) in a Multimodal LLM (MLLM). Typically, MLLMs adopt a simple MLP to preserve all visual contexts via one-to-one transformation. However, the visual tokens are redundant and can be considerably increased when dealing with high-resolution images, impairing the efficiency of MLLMs significantly. Some recent works have introduced resampler or abstractor to reduce the number of resulting visual tokens. Unfortunately, they fail to capture finer details and undermine the visual reasoning capabilities of MLLMs. In this work, we propose a novel visual projector, which adopts a coarse-to-fine scheme to inject the enriched characteristics to generate the condensed visual tokens. In specific, we first interpolate the visual features as a low-resolution point query, providing the overall visual representation as the foundation. Then, we introduce a region-to-point injection module that utilizes high-resolution, multi-level region-based cues as fine-grained reference keys and values, allowing them to be fully absorbed within the corresponding local context region. This step effectively updates the coarse point query, transforming it into an enriched one for the subsequent LLM reasoning. Extensive experiments demonstrate that our approach compresses the visual tokens by 75%~89%, while achieves comparable or even better performance across diverse benchmarks with significantly higher efficiency. The source codes can be found at https://github.com/CircleRadon/TokenPacker.
Query-Based Knowledge Sharing for Open-Vocabulary Multi-Label Classification
Jan 02, 2024Identifying labels that did not appear during training, known as multi-label zero-shot learning, is a non-trivial task in computer vision. To this end, recent studies have attempted to explore the multi-modal knowledge of vision-language pre-training (VLP) models by knowledge distillation, allowing to recognize unseen labels in an open-vocabulary manner. However, experimental evidence shows that knowledge distillation is suboptimal and provides limited performance gain in unseen label prediction. In this paper, a novel query-based knowledge sharing paradigm is proposed to explore the multi-modal knowledge from the pretrained VLP model for open-vocabulary multi-label classification. Specifically, a set of learnable label-agnostic query tokens is trained to extract critical vision knowledge from the input image, and further shared across all labels, allowing them to select tokens of interest as visual clues for recognition. Besides, we propose an effective prompt pool for robust label embedding, and reformulate the standard ranking learning into a form of classification to allow the magnitude of feature vectors for matching, which both significantly benefit label recognition. Experimental results show that our framework significantly outperforms state-of-the-art methods on zero-shot task by 5.9% and 4.5% in mAP on the NUS-WIDE and Open Images, respectively.
Osprey: Pixel Understanding with Visual Instruction Tuning
Dec 25, 2023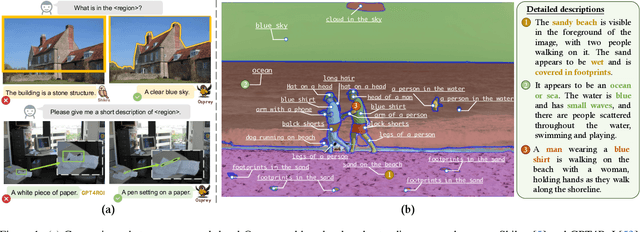



Multimodal large language models (MLLMs) have recently achieved impressive general-purpose vision-language capabilities through visual instruction tuning. However, current MLLMs primarily focus on image-level or box-level understanding, falling short of achieving fine-grained vision-language alignment at the pixel level. Besides, the lack of mask-based instruction data limits their advancements. In this paper, we propose Osprey, a mask-text instruction tuning approach, to extend MLLMs by incorporating fine-grained mask regions into language instruction, aiming at achieving pixel-wise visual understanding. To achieve this goal, we first meticulously curate a mask-based region-text dataset with 724K samples, and then design a vision-language model by injecting pixel-level representation into LLM. Especially, Osprey adopts a convolutional CLIP backbone as the vision encoder and employs a mask-aware visual extractor to extract precise visual mask features from high resolution input. Experimental results demonstrate Osprey's superiority in various region understanding tasks, showcasing its new capability for pixel-level instruction tuning. In particular, Osprey can be integrated with Segment Anything Model (SAM) seamlessly to obtain multi-granularity semantics. The source code, dataset and demo can be found at https://github.com/CircleRadon/Osprey.
Text as Image: Learning Transferable Adapter for Multi-Label Classification
Dec 07, 2023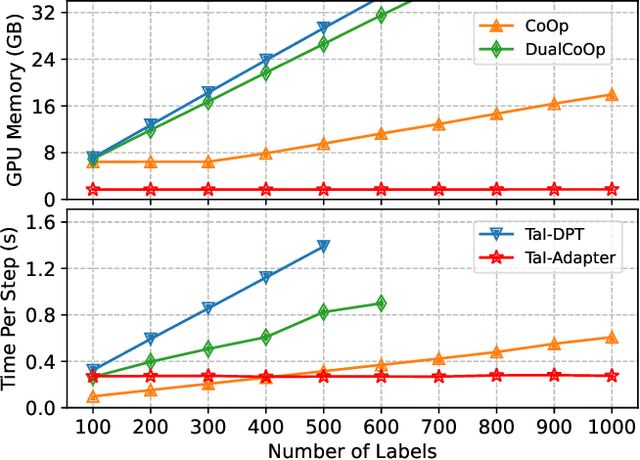



Pre-trained vision-language models have notably accelerated progress of open-world concept recognition. Their impressive zero-shot ability has recently been transferred to multi-label image classification via prompt tuning, enabling to discover novel labels in an open-vocabulary manner. However, this paradigm suffers from non-trivial training costs, and becomes computationally prohibitive for a large number of candidate labels. To address this issue, we note that vision-language pre-training aligns images and texts in a unified embedding space, making it potential for an adapter network to identify labels in visual modality while be trained in text modality. To enhance such cross-modal transfer ability, a simple yet effective method termed random perturbation is proposed, which enables the adapter to search for potential visual embeddings by perturbing text embeddings with noise during training, resulting in better performance in visual modality. Furthermore, we introduce an effective approach to employ large language models for multi-label instruction-following text generation. In this way, a fully automated pipeline for visual label recognition is developed without relying on any manual data. Extensive experiments on public benchmarks show the superiority of our method in various multi-label classification tasks.
Label-efficient Segmentation via Affinity Propagation
Oct 17, 2023



Weakly-supervised segmentation with label-efficient sparse annotations has attracted increasing research attention to reduce the cost of laborious pixel-wise labeling process, while the pairwise affinity modeling techniques play an essential role in this task. Most of the existing approaches focus on using the local appearance kernel to model the neighboring pairwise potentials. However, such a local operation fails to capture the long-range dependencies and ignores the topology of objects. In this work, we formulate the affinity modeling as an affinity propagation process, and propose a local and a global pairwise affinity terms to generate accurate soft pseudo labels. An efficient algorithm is also developed to reduce significantly the computational cost. The proposed approach can be conveniently plugged into existing segmentation networks. Experiments on three typical label-efficient segmentation tasks, i.e. box-supervised instance segmentation, point/scribble-supervised semantic segmentation and CLIP-guided semantic segmentation, demonstrate the superior performance of the proposed approach.