 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMing-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025



We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
M2-Encoder: Advancing Bilingual Image-Text Understanding by Large-scale Efficient Pretraining
Feb 04, 2024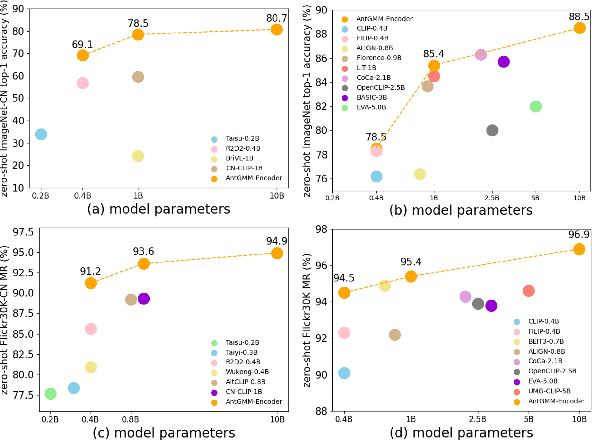
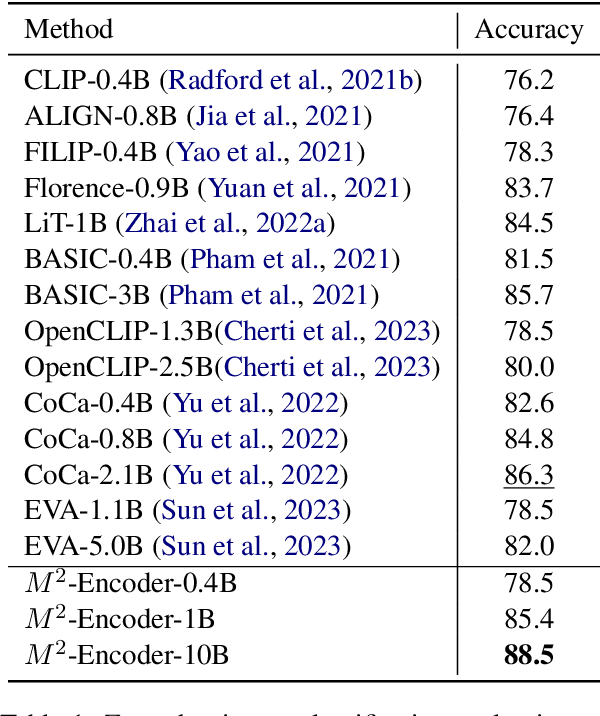
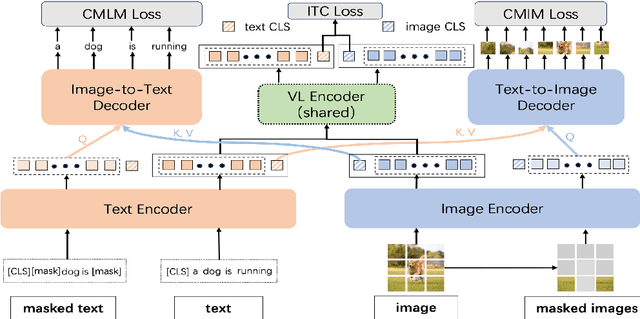
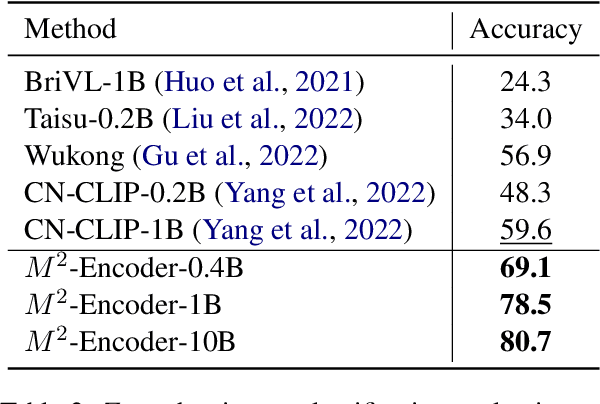
Vision-language foundation models like CLIP have revolutionized the field of artificial intelligence. Nevertheless, VLM models supporting multi-language, e.g., in both Chinese and English, have lagged due to the relative scarcity of large-scale pretraining datasets. Toward this end, we introduce a comprehensive bilingual (Chinese-English) dataset BM-6B with over 6 billion image-text pairs, aimed at enhancing multimodal foundation models to well understand images in both languages. To handle such a scale of dataset, we propose a novel grouped aggregation approach for image-text contrastive loss computation, which reduces the communication overhead and GPU memory demands significantly, facilitating a 60% increase in training speed. We pretrain a series of bilingual image-text foundation models with an enhanced fine-grained understanding ability on BM-6B, the resulting models, dubbed as $M^2$-Encoders (pronounced "M-Square"), set new benchmarks in both languages for multimodal retrieval and classification tasks. Notably, Our largest $M^2$-Encoder-10B model has achieved top-1 accuracies of 88.5% on ImageNet and 80.7% on ImageNet-CN under a zero-shot classification setting, surpassing previously reported SoTA methods by 2.2% and 21.1%, respectively. The $M^2$-Encoder series represents one of the most comprehensive bilingual image-text foundation models to date, so we are making it available to the research community for further exploration and development.
SyCoCa: Symmetrizing Contrastive Captioners with Attentive Masking for Multimodal Alignment
Jan 04, 2024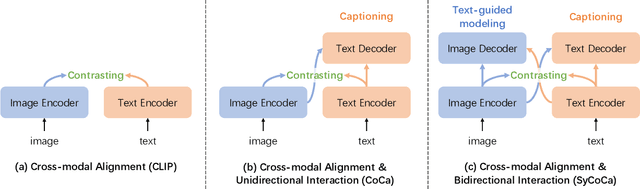
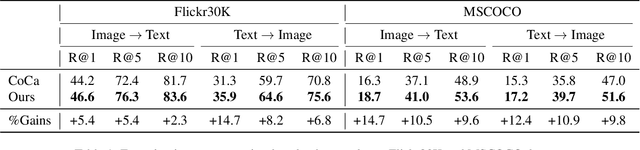
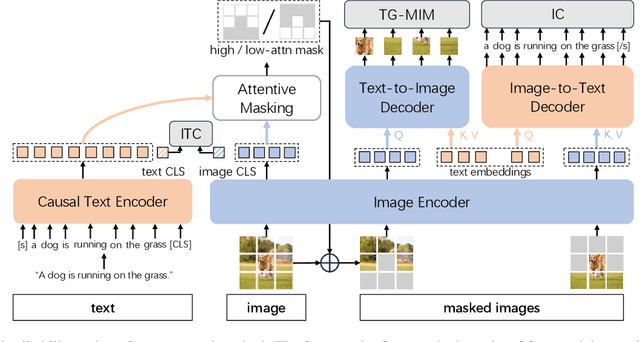

Multimodal alignment between language and vision is the fundamental topic in current vision-language model research. Contrastive Captioners (CoCa), as a representative method, integrates Contrastive Language-Image Pretraining (CLIP) and Image Caption (IC) into a unified framework, resulting in impressive results. CLIP imposes a bidirectional constraints on global representation of entire images and sentences. Although IC conducts an unidirectional image-to-text generation on local representation, it lacks any constraint on local text-to-image reconstruction, which limits the ability to understand images at a fine-grained level when aligned with texts. To achieve multimodal alignment from both global and local perspectives, this paper proposes Symmetrizing Contrastive Captioners (SyCoCa), which introduces bidirectional interactions on images and texts across the global and local representation levels. Specifically, we expand a Text-Guided Masked Image Modeling (TG-MIM) head based on ITC and IC heads. The improved SyCoCa can further leverage textual cues to reconstruct contextual images and visual cues to predict textual contents. When implementing bidirectional local interactions, the local contents of images tend to be cluttered or unrelated to their textual descriptions. Thus, we employ an attentive masking strategy to select effective image patches for interaction. Extensive experiments on five vision-language tasks, including image-text retrieval, image-captioning, visual question answering, and zero-shot/finetuned image classification, validate the effectiveness of our proposed method.
Text as Image: Learning Transferable Adapter for Multi-Label Classification
Dec 07, 2023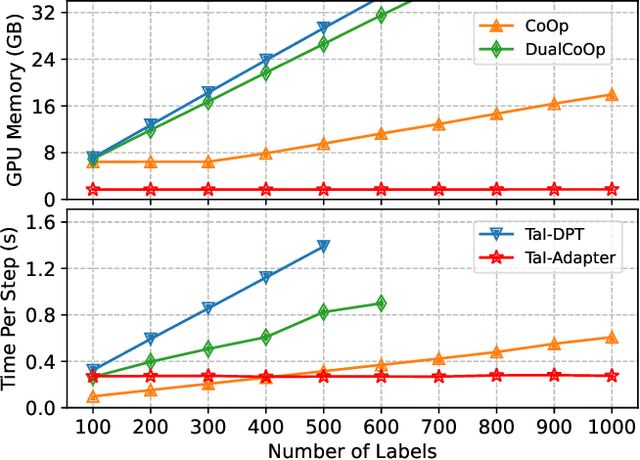



Pre-trained vision-language models have notably accelerated progress of open-world concept recognition. Their impressive zero-shot ability has recently been transferred to multi-label image classification via prompt tuning, enabling to discover novel labels in an open-vocabulary manner. However, this paradigm suffers from non-trivial training costs, and becomes computationally prohibitive for a large number of candidate labels. To address this issue, we note that vision-language pre-training aligns images and texts in a unified embedding space, making it potential for an adapter network to identify labels in visual modality while be trained in text modality. To enhance such cross-modal transfer ability, a simple yet effective method termed random perturbation is proposed, which enables the adapter to search for potential visual embeddings by perturbing text embeddings with noise during training, resulting in better performance in visual modality. Furthermore, we introduce an effective approach to employ large language models for multi-label instruction-following text generation. In this way, a fully automated pipeline for visual label recognition is developed without relying on any manual data. Extensive experiments on public benchmarks show the superiority of our method in various multi-label classification tasks.
Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval
Sep 20, 2023With the explosive growth of web videos in recent years, large-scale Content-Based Video Retrieval (CBVR) becomes increasingly essential in video filtering, recommendation, and copyright protection. Segment-level CBVR (S-CBVR) locates the start and end time of similar segments in finer granularity, which is beneficial for user browsing efficiency and infringement detection especially in long video scenarios. The challenge of S-CBVR task is how to achieve high temporal alignment accuracy with efficient computation and low storage consumption. In this paper, we propose a Segment Similarity and Alignment Network (SSAN) in dealing with the challenge which is firstly trained end-to-end in S-CBVR. SSAN is based on two newly proposed modules in video retrieval: (1) An efficient Self-supervised Keyframe Extraction (SKE) module to reduce redundant frame features, (2) A robust Similarity Pattern Detection (SPD) module for temporal alignment. In comparison with uniform frame extraction, SKE not only saves feature storage and search time, but also introduces comparable accuracy and limited extra computation time. In terms of temporal alignment, SPD localizes similar segments with higher accuracy and efficiency than existing deep learning methods. Furthermore, we jointly train SSAN with SKE and SPD and achieve an end-to-end improvement. Meanwhile, the two key modules SKE and SPD can also be effectively inserted into other video retrieval pipelines and gain considerable performance improvements. Experimental results on public datasets show that SSAN can obtain higher alignment accuracy while saving storage and online query computational cost compared to existing methods.
Boundary-aware Backward-Compatible Representation via Adversarial Learning in Image Retrieval
May 04, 2023Image retrieval plays an important role in the Internet world. Usually, the core parts of mainstream visual retrieval systems include an online service of the embedding model and a large-scale vector database. For traditional model upgrades, the old model will not be replaced by the new one until the embeddings of all the images in the database are re-computed by the new model, which takes days or weeks for a large amount of data. Recently, backward-compatible training (BCT) enables the new model to be immediately deployed online by making the new embeddings directly comparable to the old ones. For BCT, improving the compatibility of two models with less negative impact on retrieval performance is the key challenge. In this paper, we introduce AdvBCT, an Adversarial Backward-Compatible Training method with an elastic boundary constraint that takes both compatibility and discrimination into consideration. We first employ adversarial learning to minimize the distribution disparity between embeddings of the new model and the old model. Meanwhile, we add an elastic boundary constraint during training to improve compatibility and discrimination efficiently. Extensive experiments on GLDv2, Revisited Oxford (ROxford), and Revisited Paris (RParis) demonstrate that our method outperforms other BCT methods on both compatibility and discrimination. The implementation of AdvBCT will be publicly available at https://github.com/Ashespt/AdvBCT.
DC-Former: Diverse and Compact Transformer for Person Re-Identification
Feb 28, 2023In person re-identification (re-ID) task, it is still challenging to learn discriminative representation by deep learning, due to limited data. Generally speaking, the model will get better performance when increasing the amount of data. The addition of similar classes strengthens the ability of the classifier to identify similar identities, thereby improving the discrimination of representation. In this paper, we propose a Diverse and Compact Transformer (DC-Former) that can achieve a similar effect by splitting embedding space into multiple diverse and compact subspaces. Compact embedding subspace helps model learn more robust and discriminative embedding to identify similar classes. And the fusion of these diverse embeddings containing more fine-grained information can further improve the effect of re-ID. Specifically, multiple class tokens are used in vision transformer to represent multiple embedding spaces. Then, a self-diverse constraint (SDC) is applied to these spaces to push them away from each other, which makes each embedding space diverse and compact. Further, a dynamic weight controller(DWC) is further designed for balancing the relative importance among them during training. The experimental results of our method are promising, which surpass previous state-of-the-art methods on several commonly used person re-ID benchmarks.
Solutions for Fine-grained and Long-tailed Snake Species Recognition in SnakeCLEF 2022
Jul 04, 2022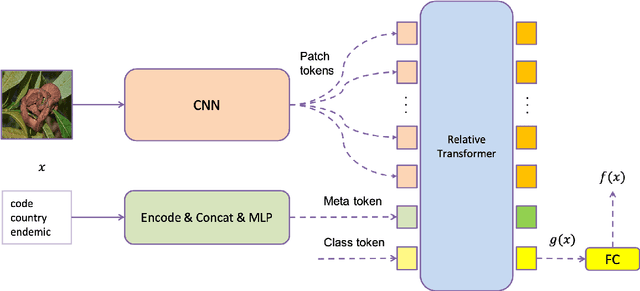
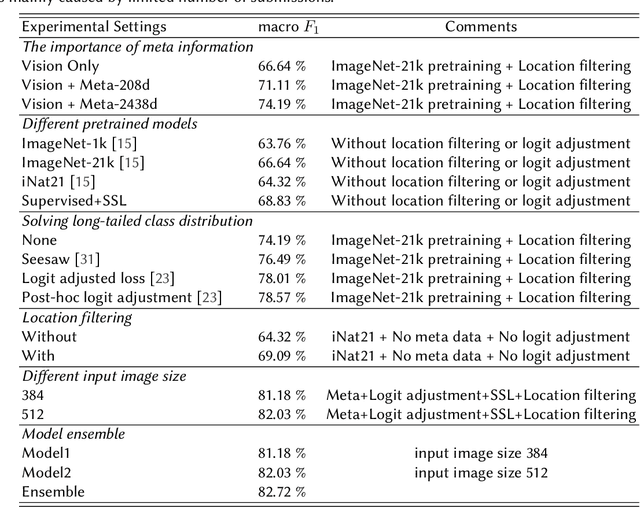

Automatic snake species recognition is important because it has vast potential to help lower deaths and disabilities caused by snakebites. We introduce our solution in SnakeCLEF 2022 for fine-grained snake species recognition on a heavy long-tailed class distribution. First, a network architecture is designed to extract and fuse features from multiple modalities, i.e. photograph from visual modality and geographic locality information from language modality. Then, logit adjustment based methods are studied to relieve the impact caused by the severe class imbalance. Next, a combination of supervised and self-supervised learning method is proposed to make full use of the dataset, including both labeled training data and unlabeled testing data. Finally, post processing strategies, such as multi-scale and multi-crop test-time-augmentation, location filtering and model ensemble, are employed for better performance. With an ensemble of several different models, a private score 82.65%, ranking the 3rd, is achieved on the final leaderboard.
A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
Mar 05, 2022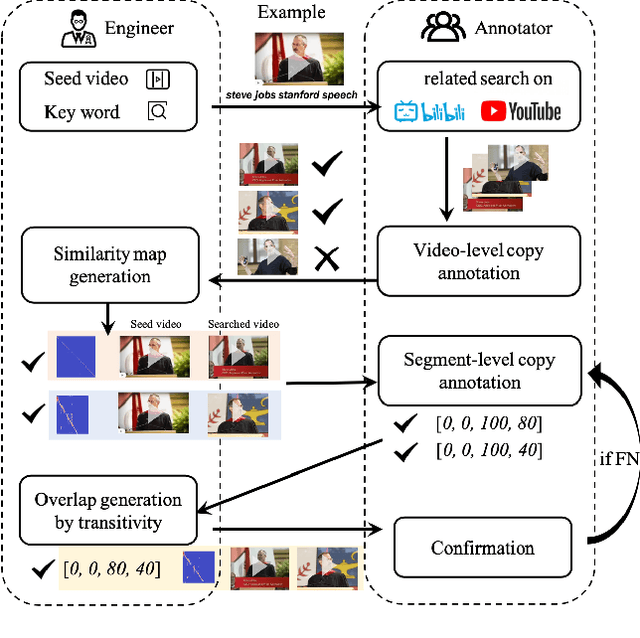
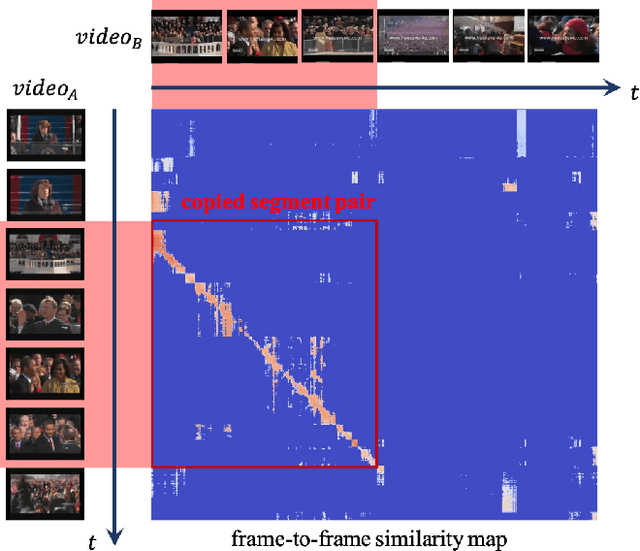
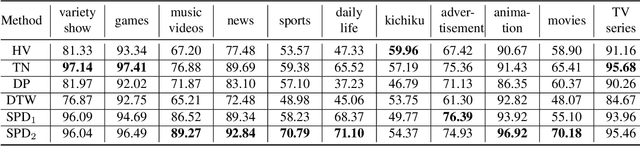
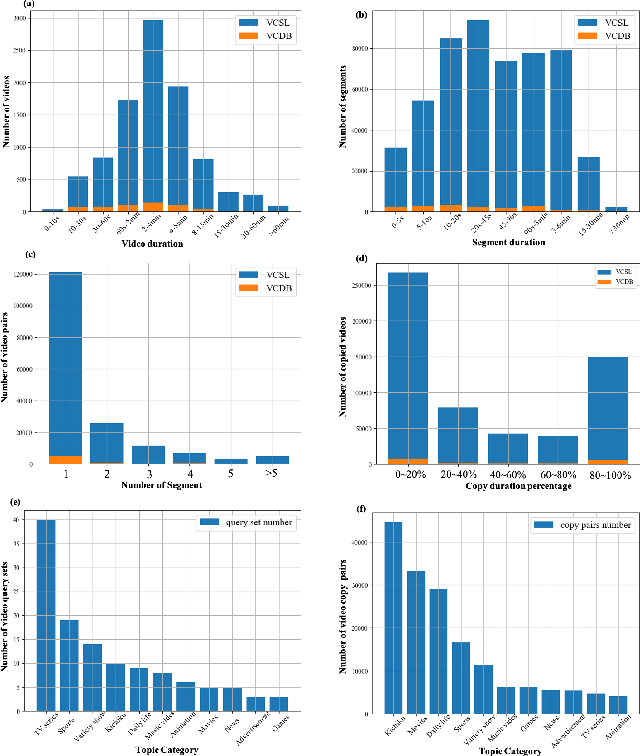
In this paper, we introduce VCSL (Video Copy Segment Localization), a new comprehensive segment-level annotated video copy dataset. Compared with existing copy detection datasets restricted by either video-level annotation or small-scale, VCSL not only has two orders of magnitude more segment-level labelled data, with 160k realistic video copy pairs containing more than 280k localized copied segment pairs, but also covers a variety of video categories and a wide range of video duration. All the copied segments inside each collected video pair are manually extracted and accompanied by precisely annotated starting and ending timestamps. Alongside the dataset, we also propose a novel evaluation protocol that better measures the prediction accuracy of copy overlapping segments between a video pair and shows improved adaptability in different scenarios. By benchmarking several baseline and state-of-the-art segment-level video copy detection methods with the proposed dataset and evaluation metric, we provide a comprehensive analysis that uncovers the strengths and weaknesses of current approaches, hoping to open up promising directions for future works. The VCSL dataset, metric and benchmark codes are all publicly available at https://github.com/alipay/VCSL.
HBReID: Harder Batch for Re-identification
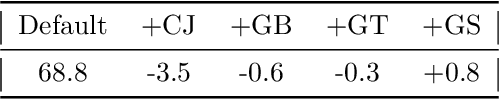
Dec 09, 2021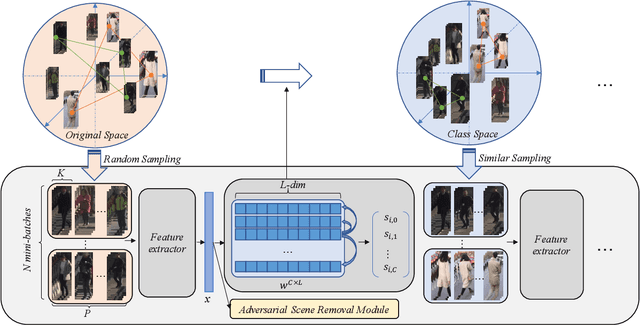

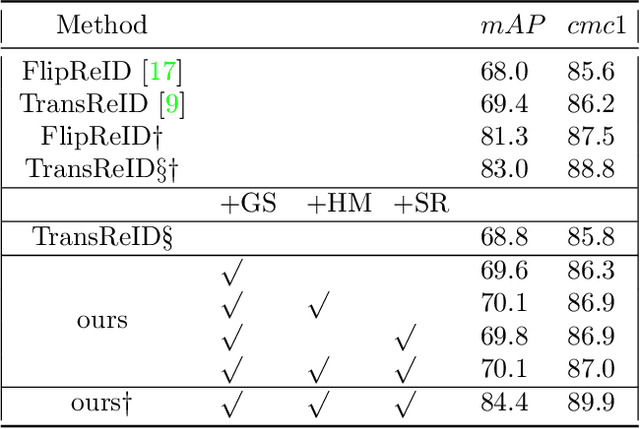
Triplet loss is a widely adopted loss function in ReID task which pulls the hardest positive pairs close and pushes the hardest negative pairs far away. However, the selected samples are not the hardest globally, but the hardest only in a mini-batch, which will affect the performance. In this report, a hard batch mining method is proposed to mine the hardest samples globally to make triplet harder. More specifically, the most similar classes are selected into a same mini-batch so that the similar classes could be pushed further away. Besides, an adversarial scene removal module composed of a scene classifier and an adversarial loss is used to learn scene invariant feature representations. Experiments are conducted on dataset MSMT17 to prove the effectiveness, and our method surpasses all of the previous methods and sets state-of-the-art result.