 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval
Sep 20, 2023With the explosive growth of web videos in recent years, large-scale Content-Based Video Retrieval (CBVR) becomes increasingly essential in video filtering, recommendation, and copyright protection. Segment-level CBVR (S-CBVR) locates the start and end time of similar segments in finer granularity, which is beneficial for user browsing efficiency and infringement detection especially in long video scenarios. The challenge of S-CBVR task is how to achieve high temporal alignment accuracy with efficient computation and low storage consumption. In this paper, we propose a Segment Similarity and Alignment Network (SSAN) in dealing with the challenge which is firstly trained end-to-end in S-CBVR. SSAN is based on two newly proposed modules in video retrieval: (1) An efficient Self-supervised Keyframe Extraction (SKE) module to reduce redundant frame features, (2) A robust Similarity Pattern Detection (SPD) module for temporal alignment. In comparison with uniform frame extraction, SKE not only saves feature storage and search time, but also introduces comparable accuracy and limited extra computation time. In terms of temporal alignment, SPD localizes similar segments with higher accuracy and efficiency than existing deep learning methods. Furthermore, we jointly train SSAN with SKE and SPD and achieve an end-to-end improvement. Meanwhile, the two key modules SKE and SPD can also be effectively inserted into other video retrieval pipelines and gain considerable performance improvements. Experimental results on public datasets show that SSAN can obtain higher alignment accuracy while saving storage and online query computational cost compared to existing methods.
A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
Mar 05, 2022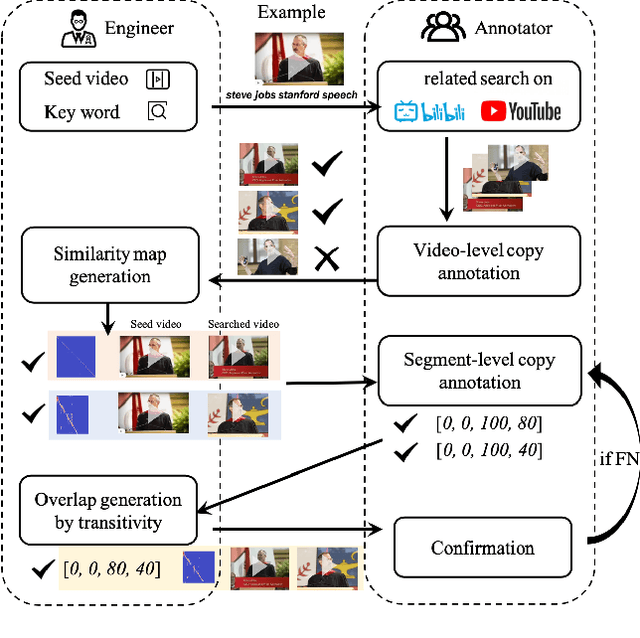
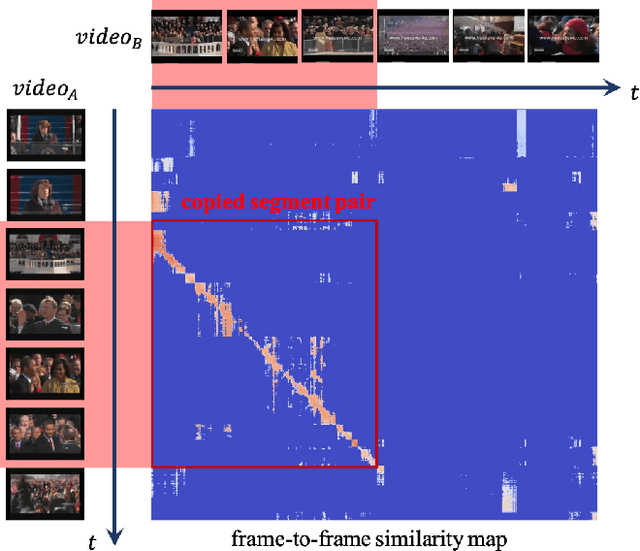
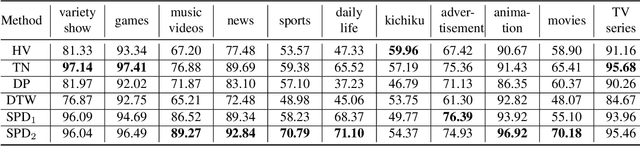
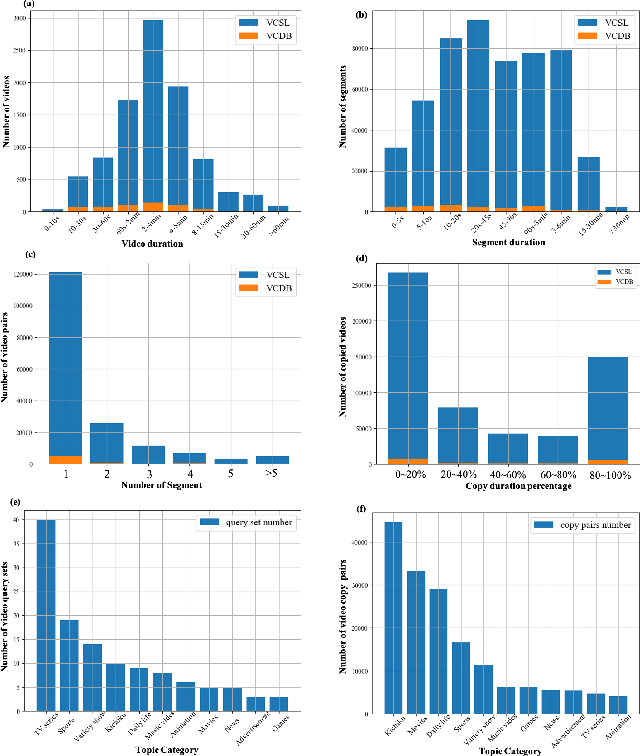
In this paper, we introduce VCSL (Video Copy Segment Localization), a new comprehensive segment-level annotated video copy dataset. Compared with existing copy detection datasets restricted by either video-level annotation or small-scale, VCSL not only has two orders of magnitude more segment-level labelled data, with 160k realistic video copy pairs containing more than 280k localized copied segment pairs, but also covers a variety of video categories and a wide range of video duration. All the copied segments inside each collected video pair are manually extracted and accompanied by precisely annotated starting and ending timestamps. Alongside the dataset, we also propose a novel evaluation protocol that better measures the prediction accuracy of copy overlapping segments between a video pair and shows improved adaptability in different scenarios. By benchmarking several baseline and state-of-the-art segment-level video copy detection methods with the proposed dataset and evaluation metric, we provide a comprehensive analysis that uncovers the strengths and weaknesses of current approaches, hoping to open up promising directions for future works. The VCSL dataset, metric and benchmark codes are all publicly available at https://github.com/alipay/VCSL.