 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
Jan 28, 2026"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.
Federated Balanced Learning
Jan 20, 2026Federated learning is a paradigm of joint learning in which clients collaborate by sharing model parameters instead of data. However, in the non-iid setting, the global model experiences client drift, which can seriously affect the final performance of the model. Previous methods tend to correct the global model that has already deviated based on the loss function or gradient, overlooking the impact of the client samples. In this paper, we rethink the role of the client side and propose Federated Balanced Learning, i.e., FBL, to prevent this issue from the beginning through sample balance on the client side. Technically, FBL allows unbalanced data on the client side to achieve sample balance through knowledge filling and knowledge sampling using edge-side generation models, under the limitation of a fixed number of data samples on clients. Furthermore, we design a Knowledge Alignment Strategy to bridge the gap between synthetic and real data, and a Knowledge Drop Strategy to regularize our method. Meanwhile, we scale our method to real and complex scenarios, allowing different clients to adopt various methods, and extend our framework to further improve performance. Numerous experiments show that our method outperforms state-of-the-art baselines. The code is released upon acceptance.
Behavior Modeling Space Reconstruction for E-Commerce Search
Jan 30, 2025



Delivering superior search services is crucial for enhancing customer experience and driving revenue growth. Conventionally, search systems model user behaviors by combining user preference and query item relevance statically, often through a fixed logical 'and' relationship. This paper reexamines existing approaches through a unified lens using both causal graphs and Venn diagrams, uncovering two prevalent yet significant issues: entangled preference and relevance effects, and a collapsed modeling space. To surmount these challenges, our research introduces a novel framework, DRP, which enhances search accuracy through two components to reconstruct the behavior modeling space. Specifically, we implement preference editing to proactively remove the relevance effect from preference predictions, yielding untainted user preferences. Additionally, we employ adaptive fusion, which dynamically adjusts fusion criteria to align with the varying patterns of relevance and preference, facilitating more nuanced and tailored behavior predictions within the reconstructed modeling space. Empirical validation on two public datasets and a proprietary search dataset underscores the superiority of our proposed methodology, demonstrating marked improvements in performance over existing approaches.
AskChart: Universal Chart Understanding through Textual Enhancement
Dec 26, 2024Chart understanding tasks such as ChartQA and Chart-to-Text involve automatically extracting and interpreting key information from charts, enabling users to query or convert visual data into structured formats. State-of-the-art approaches primarily focus on visual cues from chart images, failing to explicitly incorporate rich textual information (e.g., data labels and axis labels) embedded within the charts. This textual information is vital for intuitive human comprehension and interpretation of charts. Moreover, existing models are often large and computationally intensive, limiting their practical applicability. In this paper, we introduce AskChart, a universal model that explicitly integrates both textual and visual cues from charts using a Mixture of Experts (MoE) architecture. AskChart facilitates the learning of enhanced visual-textual representations of charts for effectively handling multiple chart understanding tasks, while maintaining a smaller model size. To capture the synergy between visual and textual modalities, we curate a large-scale dataset named ChartBank with about 7.5M data samples, which helps align textual and visual information and facilitates the extraction of visual entities and text. To effectively train AskChart, we design a three-stage training strategy to align visual and textual modalities for learning robust visual-textual representations and optimizing the learning of the MoE layer. Extensive experiments across five datasets demonstrate the significant performance gains of AskChart in four chart understanding tasks. Remarkably, AskChart with 4.6B parameters outperforms state-of-the-art models with 13B parameters by 68.3% in Open-ended ChartQA and 49.2% in Chart-to-Text tasks, while achieving comparable performance in ChartQA and Chart-to-Table tasks.
Learning Segment Similarity and Alignment in Large-Scale Content Based Video Retrieval
Sep 20, 2023With the explosive growth of web videos in recent years, large-scale Content-Based Video Retrieval (CBVR) becomes increasingly essential in video filtering, recommendation, and copyright protection. Segment-level CBVR (S-CBVR) locates the start and end time of similar segments in finer granularity, which is beneficial for user browsing efficiency and infringement detection especially in long video scenarios. The challenge of S-CBVR task is how to achieve high temporal alignment accuracy with efficient computation and low storage consumption. In this paper, we propose a Segment Similarity and Alignment Network (SSAN) in dealing with the challenge which is firstly trained end-to-end in S-CBVR. SSAN is based on two newly proposed modules in video retrieval: (1) An efficient Self-supervised Keyframe Extraction (SKE) module to reduce redundant frame features, (2) A robust Similarity Pattern Detection (SPD) module for temporal alignment. In comparison with uniform frame extraction, SKE not only saves feature storage and search time, but also introduces comparable accuracy and limited extra computation time. In terms of temporal alignment, SPD localizes similar segments with higher accuracy and efficiency than existing deep learning methods. Furthermore, we jointly train SSAN with SKE and SPD and achieve an end-to-end improvement. Meanwhile, the two key modules SKE and SPD can also be effectively inserted into other video retrieval pipelines and gain considerable performance improvements. Experimental results on public datasets show that SSAN can obtain higher alignment accuracy while saving storage and online query computational cost compared to existing methods.
Boundary-aware Backward-Compatible Representation via Adversarial Learning in Image Retrieval
May 04, 2023Image retrieval plays an important role in the Internet world. Usually, the core parts of mainstream visual retrieval systems include an online service of the embedding model and a large-scale vector database. For traditional model upgrades, the old model will not be replaced by the new one until the embeddings of all the images in the database are re-computed by the new model, which takes days or weeks for a large amount of data. Recently, backward-compatible training (BCT) enables the new model to be immediately deployed online by making the new embeddings directly comparable to the old ones. For BCT, improving the compatibility of two models with less negative impact on retrieval performance is the key challenge. In this paper, we introduce AdvBCT, an Adversarial Backward-Compatible Training method with an elastic boundary constraint that takes both compatibility and discrimination into consideration. We first employ adversarial learning to minimize the distribution disparity between embeddings of the new model and the old model. Meanwhile, we add an elastic boundary constraint during training to improve compatibility and discrimination efficiently. Extensive experiments on GLDv2, Revisited Oxford (ROxford), and Revisited Paris (RParis) demonstrate that our method outperforms other BCT methods on both compatibility and discrimination. The implementation of AdvBCT will be publicly available at https://github.com/Ashespt/AdvBCT.
TransVCL: Attention-enhanced Video Copy Localization Network with Flexible Supervision
Nov 24, 2022



Video copy localization aims to precisely localize all the copied segments within a pair of untrimmed videos in video retrieval applications. Previous methods typically start from frame-to-frame similarity matrix generated by cosine similarity between frame-level features of the input video pair, and then detect and refine the boundaries of copied segments on similarity matrix under temporal constraints. In this paper, we propose TransVCL: an attention-enhanced video copy localization network, which is optimized directly from initial frame-level features and trained end-to-end with three main components: a customized Transformer for feature enhancement, a correlation and softmax layer for similarity matrix generation, and a temporal alignment module for copied segments localization. In contrast to previous methods demanding the handcrafted similarity matrix, TransVCL incorporates long-range temporal information between feature sequence pair using self- and cross- attention layers. With the joint design and optimization of three components, the similarity matrix can be learned to present more discriminative copied patterns, leading to significant improvements over previous methods on segment-level labeled datasets (VCSL and VCDB). Besides the state-of-the-art performance in fully supervised setting, the attention architecture facilitates TransVCL to further exploit unlabeled or simply video-level labeled data. Additional experiments of supplementing video-level labeled datasets including SVD and FIVR reveal the high flexibility of TransVCL from full supervision to semi-supervision (with or without video-level annotation). Code is publicly available at https://github.com/transvcl/TransVCL.
A Large-scale Comprehensive Dataset and Copy-overlap Aware Evaluation Protocol for Segment-level Video Copy Detection
Mar 05, 2022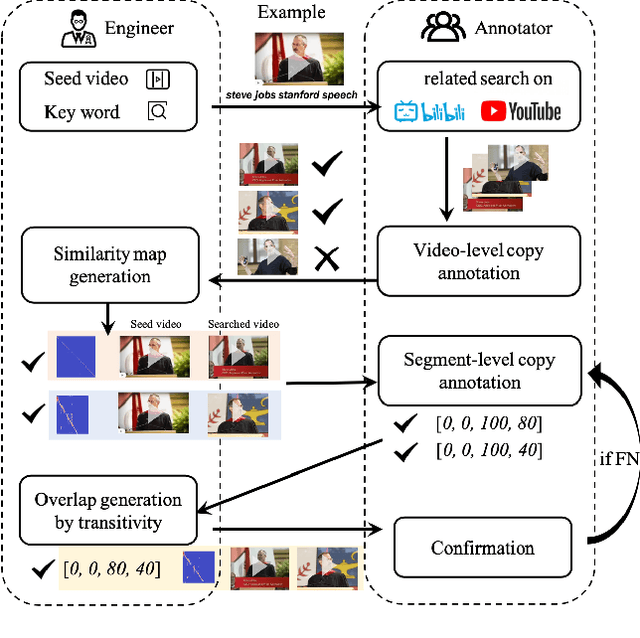
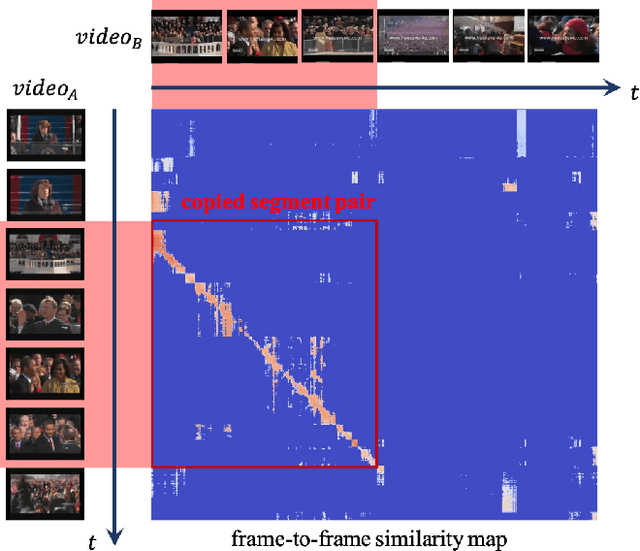
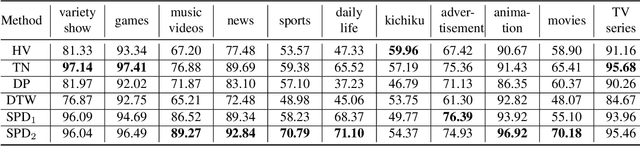
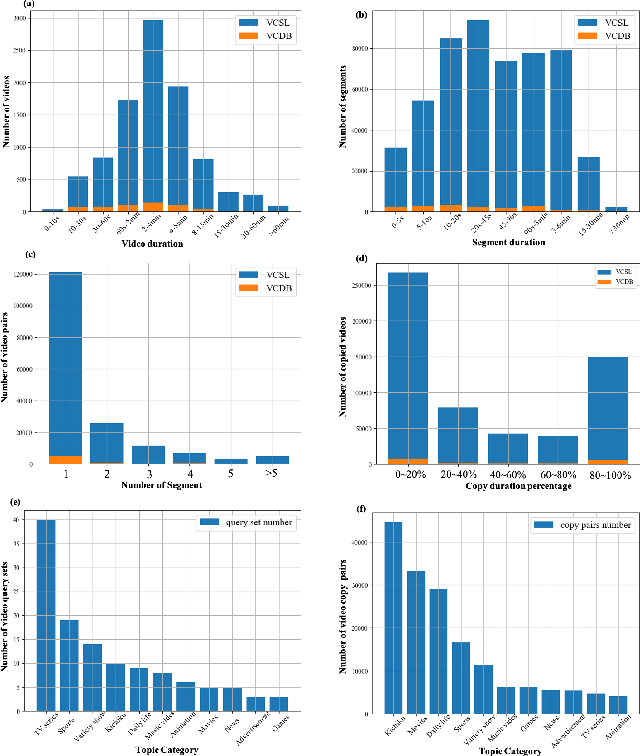
In this paper, we introduce VCSL (Video Copy Segment Localization), a new comprehensive segment-level annotated video copy dataset. Compared with existing copy detection datasets restricted by either video-level annotation or small-scale, VCSL not only has two orders of magnitude more segment-level labelled data, with 160k realistic video copy pairs containing more than 280k localized copied segment pairs, but also covers a variety of video categories and a wide range of video duration. All the copied segments inside each collected video pair are manually extracted and accompanied by precisely annotated starting and ending timestamps. Alongside the dataset, we also propose a novel evaluation protocol that better measures the prediction accuracy of copy overlapping segments between a video pair and shows improved adaptability in different scenarios. By benchmarking several baseline and state-of-the-art segment-level video copy detection methods with the proposed dataset and evaluation metric, we provide a comprehensive analysis that uncovers the strengths and weaknesses of current approaches, hoping to open up promising directions for future works. The VCSL dataset, metric and benchmark codes are all publicly available at https://github.com/alipay/VCSL.