 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTracing Copied Pixels and Regularizing Patch Affinity in Copy Detection
Feb 19, 2026Image Copy Detection (ICD) aims to identify manipulated content between image pairs through robust feature representation learning. While self-supervised learning (SSL) has advanced ICD systems, existing view-level contrastive methods struggle with sophisticated edits due to insufficient fine-grained correspondence learning. We address this limitation by exploiting the inherent geometric traceability in edited content through two key innovations. First, we propose PixTrace - a pixel coordinate tracking module that maintains explicit spatial mappings across editing transformations. Second, we introduce CopyNCE, a geometrically-guided contrastive loss that regularizes patch affinity using overlap ratios derived from PixTrace's verified mappings. Our method bridges pixel-level traceability with patch-level similarity learning, suppressing supervision noise in SSL training. Extensive experiments demonstrate not only state-of-the-art performance (88.7% uAP / 83.9% RP90 for matcher, 72.6% uAP / 68.4% RP90 for descriptor on DISC21 dataset) but also better interpretability over existing methods.
TransVCL: Attention-enhanced Video Copy Localization Network with Flexible Supervision
Nov 24, 2022



Video copy localization aims to precisely localize all the copied segments within a pair of untrimmed videos in video retrieval applications. Previous methods typically start from frame-to-frame similarity matrix generated by cosine similarity between frame-level features of the input video pair, and then detect and refine the boundaries of copied segments on similarity matrix under temporal constraints. In this paper, we propose TransVCL: an attention-enhanced video copy localization network, which is optimized directly from initial frame-level features and trained end-to-end with three main components: a customized Transformer for feature enhancement, a correlation and softmax layer for similarity matrix generation, and a temporal alignment module for copied segments localization. In contrast to previous methods demanding the handcrafted similarity matrix, TransVCL incorporates long-range temporal information between feature sequence pair using self- and cross- attention layers. With the joint design and optimization of three components, the similarity matrix can be learned to present more discriminative copied patterns, leading to significant improvements over previous methods on segment-level labeled datasets (VCSL and VCDB). Besides the state-of-the-art performance in fully supervised setting, the attention architecture facilitates TransVCL to further exploit unlabeled or simply video-level labeled data. Additional experiments of supplementing video-level labeled datasets including SVD and FIVR reveal the high flexibility of TransVCL from full supervision to semi-supervision (with or without video-level annotation). Code is publicly available at https://github.com/transvcl/TransVCL.
Entity-Graph Enhanced Cross-Modal Pretraining for Instance-level Product Retrieval
Jun 17, 2022

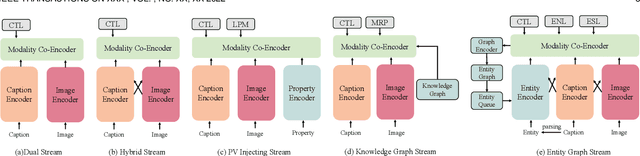
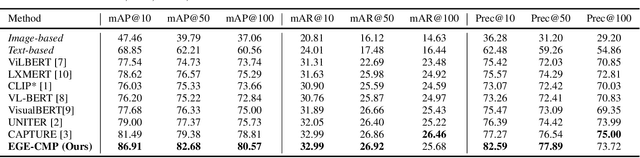
Our goal in this research is to study a more realistic environment in which we can conduct weakly-supervised multi-modal instance-level product retrieval for fine-grained product categories. We first contribute the Product1M datasets, and define two real practical instance-level retrieval tasks to enable the evaluations on the price comparison and personalized recommendations. For both instance-level tasks, how to accurately pinpoint the product target mentioned in the visual-linguistic data and effectively decrease the influence of irrelevant contents is quite challenging. To address this, we exploit to train a more effective cross-modal pertaining model which is adaptively capable of incorporating key concept information from the multi-modal data, by using an entity graph whose node and edge respectively denote the entity and the similarity relation between entities. Specifically, a novel Entity-Graph Enhanced Cross-Modal Pretraining (EGE-CMP) model is proposed for instance-level commodity retrieval, that explicitly injects entity knowledge in both node-based and subgraph-based ways into the multi-modal networks via a self-supervised hybrid-stream transformer, which could reduce the confusion between different object contents, thereby effectively guiding the network to focus on entities with real semantic. Experimental results well verify the efficacy and generalizability of our EGE-CMP, outperforming several SOTA cross-modal baselines like CLIP, UNITER and CAPTURE.
Bridging the Gap between Reality and Ideality of Entity Matching: A Revisiting and Benchmark Re-Construction
May 12, 2022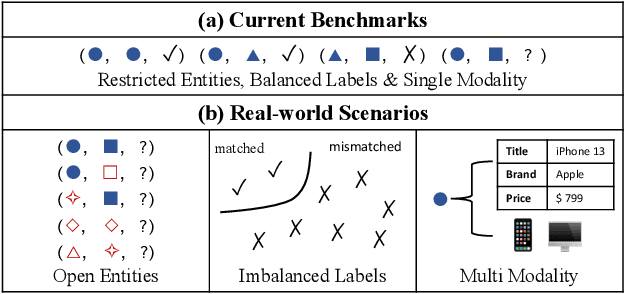
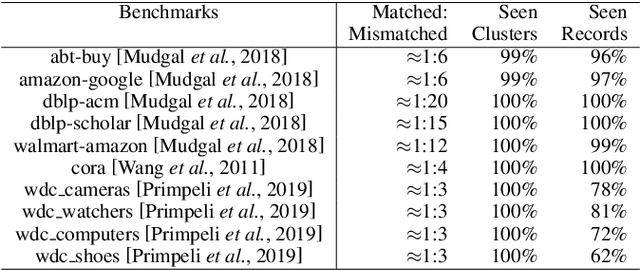
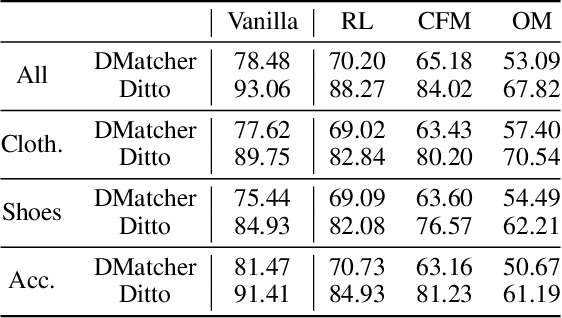

Entity matching (EM) is the most critical step for entity resolution (ER). While current deep learningbased methods achieve very impressive performance on standard EM benchmarks, their realworld application performance is much frustrating. In this paper, we highlight that such the gap between reality and ideality stems from the unreasonable benchmark construction process, which is inconsistent with the nature of entity matching and therefore leads to biased evaluations of current EM approaches. To this end, we build a new EM corpus and re-construct EM benchmarks to challenge critical assumptions implicit in the previous benchmark construction process by step-wisely changing the restricted entities, balanced labels, and single-modal records in previous benchmarks into open entities, imbalanced labels, and multimodal records in an open environment. Experimental results demonstrate that the assumptions made in the previous benchmark construction process are not coincidental with the open environment, which conceal the main challenges of the task and therefore significantly overestimate the current progress of entity matching. The constructed benchmarks and code are publicly released
M5Product: A Multi-modal Pretraining Benchmark for E-commercial Product Downstream Tasks
Sep 09, 2021

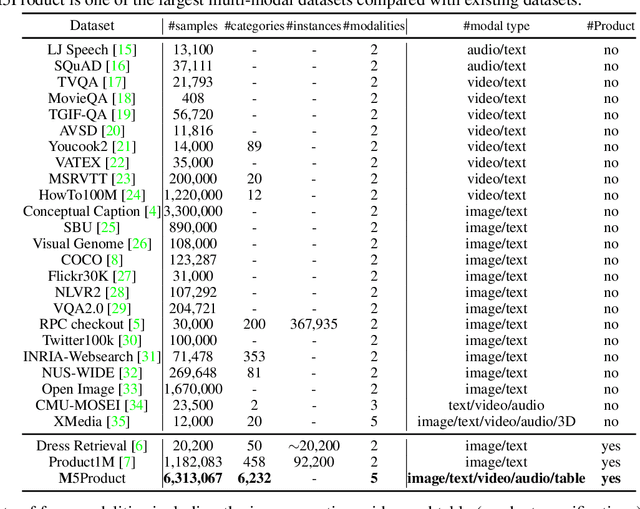

In this paper, we aim to advance the research of multi-modal pre-training on E-commerce and subsequently contribute a large-scale dataset, named M5Product, which consists of over 6 million multimodal pairs, covering more than 6,000 categories and 5,000 attributes. Generally, existing multi-modal datasets are either limited in scale or modality diversity. Differently, our M5Product is featured from the following aspects. First, the M5Product dataset is 500 times larger than the public multimodal dataset with the same number of modalities and nearly twice larger compared with the largest available text-image cross-modal dataset. Second, the dataset contains rich information of multiple modalities including image, text, table, video and audio, in which each modality can capture different views of semantic information (e.g. category, attributes, affordance, brand, preference) and complements the other. Third, to better accommodate with real-world problems, a few portion of M5Product contains incomplete modality pairs and noises while having the long-tailed distribution, which aligns well with real-world scenarios. Finally, we provide a baseline model M5-MMT that makes the first attempt to integrate the different modality configuration into an unified model for feature fusion to address the great challenge for semantic alignment. We also evaluate various multi-model pre-training state-of-the-arts for benchmarking their capabilities in learning from unlabeled data under the different number of modalities on the M5Product dataset. We conduct extensive experiments on four downstream tasks and provide some interesting findings on these modalities. Our dataset and related code are available at https://xiaodongsuper.github.io/M5Product_dataset.
Product1M: Towards Weakly Supervised Instance-Level Product Retrieval via Cross-modal Pretraining
Aug 09, 2021
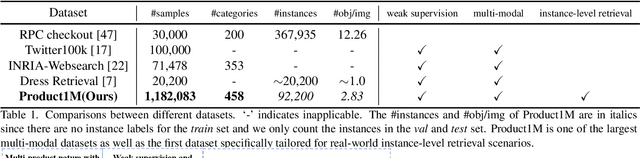
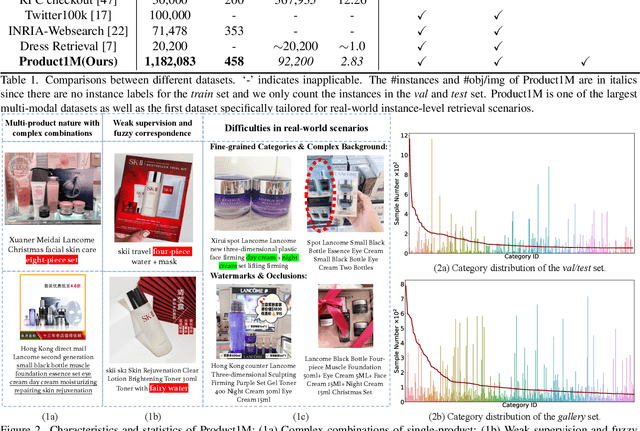
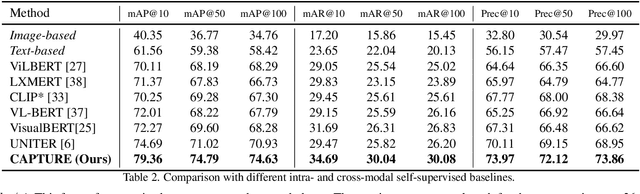
Nowadays, customer's demands for E-commerce are more diversified, which introduces more complications to the product retrieval industry. Previous methods are either subject to single-modal input or perform supervised image-level product retrieval, thus fail to accommodate real-life scenarios where enormous weakly annotated multi-modal data are present. In this paper, we investigate a more realistic setting that aims to perform weakly-supervised multi-modal instance-level product retrieval among fine-grained product categories. To promote the study of this challenging task, we contribute Product1M, one of the largest multi-modal cosmetic datasets for real-world instance-level retrieval. Notably, Product1M contains over 1 million image-caption pairs and consists of two sample types, i.e., single-product and multi-product samples, which encompass a wide variety of cosmetics brands. In addition to the great diversity, Product1M enjoys several appealing characteristics including fine-grained categories, complex combinations, and fuzzy correspondence that well mimic the real-world scenes. Moreover, we propose a novel model named Cross-modal contrAstive Product Transformer for instance-level prodUct REtrieval (CAPTURE), that excels in capturing the potential synergy between multi-modal inputs via a hybrid-stream transformer in a self-supervised manner.CAPTURE generates discriminative instance features via masked multi-modal learning as well as cross-modal contrastive pretraining and it outperforms several SOTA cross-modal baselines. Extensive ablation studies well demonstrate the effectiveness and the generalization capacity of our model. Dataset and codes are available at https: //github.com/zhanxlin/Product1M.