 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Unsupervised Prompt Learning for Classification with Black-box Language Models
Oct 04, 2024
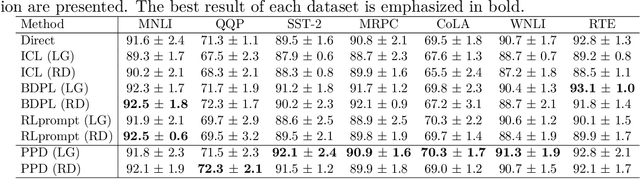


Large language models (LLMs) have achieved impressive success in text-formatted learning problems, and most popular LLMs have been deployed in a black-box fashion. Meanwhile, fine-tuning is usually necessary for a specific downstream task to obtain better performance, and this functionality is provided by the owners of the black-box LLMs. To fine-tune a black-box LLM, labeled data are always required to adjust the model parameters. However, in many real-world applications, LLMs can label textual datasets with even better quality than skilled human annotators, motivating us to explore the possibility of fine-tuning black-box LLMs with unlabeled data. In this paper, we propose unsupervised prompt learning for classification with black-box LLMs, where the learning parameters are the prompt itself and the pseudo labels of unlabeled data. Specifically, the prompt is modeled as a sequence of discrete tokens, and every token has its own to-be-learned categorical distribution. On the other hand, for learning the pseudo labels, we are the first to consider the in-context learning (ICL) capabilities of LLMs: we first identify reliable pseudo-labeled data using the LLM, and then assign pseudo labels to other unlabeled data based on the prompt, allowing the pseudo-labeled data to serve as in-context demonstrations alongside the prompt. Those in-context demonstrations matter: previously, they are involved when the prompt is used for prediction while they are not involved when the prompt is trained; thus, taking them into account during training makes the prompt-learning and prompt-using stages more consistent. Experiments on benchmark datasets show the effectiveness of our proposed algorithm. After unsupervised prompt learning, we can use the pseudo-labeled dataset for further fine-tuning by the owners of the black-box LLMs.
TransVCL: Attention-enhanced Video Copy Localization Network with Flexible Supervision
Nov 24, 2022



Video copy localization aims to precisely localize all the copied segments within a pair of untrimmed videos in video retrieval applications. Previous methods typically start from frame-to-frame similarity matrix generated by cosine similarity between frame-level features of the input video pair, and then detect and refine the boundaries of copied segments on similarity matrix under temporal constraints. In this paper, we propose TransVCL: an attention-enhanced video copy localization network, which is optimized directly from initial frame-level features and trained end-to-end with three main components: a customized Transformer for feature enhancement, a correlation and softmax layer for similarity matrix generation, and a temporal alignment module for copied segments localization. In contrast to previous methods demanding the handcrafted similarity matrix, TransVCL incorporates long-range temporal information between feature sequence pair using self- and cross- attention layers. With the joint design and optimization of three components, the similarity matrix can be learned to present more discriminative copied patterns, leading to significant improvements over previous methods on segment-level labeled datasets (VCSL and VCDB). Besides the state-of-the-art performance in fully supervised setting, the attention architecture facilitates TransVCL to further exploit unlabeled or simply video-level labeled data. Additional experiments of supplementing video-level labeled datasets including SVD and FIVR reveal the high flexibility of TransVCL from full supervision to semi-supervision (with or without video-level annotation). Code is publicly available at https://github.com/transvcl/TransVCL.
A Method to Judge the Style of Classical Poetry Based on Pre-trained Model
Nov 09, 2022



One of the important topics in the research field of Chinese classical poetry is to analyze the poetic style. By examining the relevant works of previous dynasties, researchers judge a poetic style mostly by their subjective feelings, and refer to the previous evaluations that have become a certain conclusion. Although this judgment method is often effective, there may be some errors. This paper builds the most perfect data set of Chinese classical poetry at present, trains a BART-poem pre -trained model on this data set, and puts forward a generally applicable poetry style judgment method based on this BART-poem model, innovatively introduces in-depth learning into the field of computational stylistics, and provides a new research method for the study of classical poetry. This paper attempts to use this method to solve the problem of poetry style identification in the Tang and Song Dynasties, and takes the poetry schools that are considered to have a relatively clear and consistent poetic style, such as the Hongzheng Qizi and Jiajing Qizi, Jiangxi poetic school and Tongguang poetic school, as the research object, and takes the poems of their representative poets for testing. Experiments show that the judgment results of the tested poetry work made by the model are basically consistent with the conclusions given by critics of previous dynasties, verify some avant-garde judgments of Mr. Qian Zhongshu, and better solve the task of poetry style recognition in the Tang and Song dynasties.
CAEN: A Hierarchically Attentive Evolution Network for Item-Attribute-Change-Aware Recommendation in the Growing E-commerce Environment
Aug 29, 2022


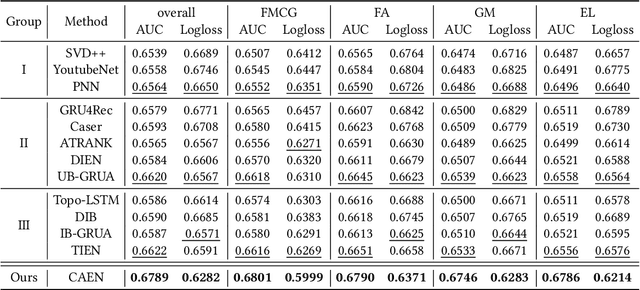
Traditional recommendation systems mainly focus on modeling user interests. However, the dynamics of recommended items caused by attribute modifications (e.g. changes in prices) are also of great importance in real systems, especially in the fast-growing e-commerce environment, which may cause the users' demands to emerge, shift and disappear. Recent studies that make efforts on dynamic item representations treat the item attributes as side information but ignore its temporal dependency, or model the item evolution with a sequence of related users but do not consider item attributes. In this paper, we propose Core Attribute Evolution Network (CAEN), which partitions the user sequence according to the attribute value and thus models the item evolution over attribute dynamics with these users. Under this framework, we further devise a hierarchical attention mechanism that applies attribute-aware attention for user aggregation under each attribute, as well as personalized attention for activating similar users in assessing the matching degree between target user and item. Results from the extensive experiments over actual e-commerce datasets show that our approach outperforms the state-of-art methods and achieves significant improvements on the items with rapid changes over attributes, therefore helping the item recommendation to adapt to the growth of the e-commerce platform.
Hybrid Interest Modeling for Long-tailed Users
Dec 29, 2020

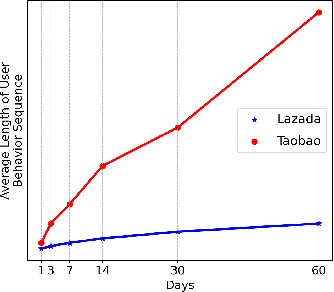
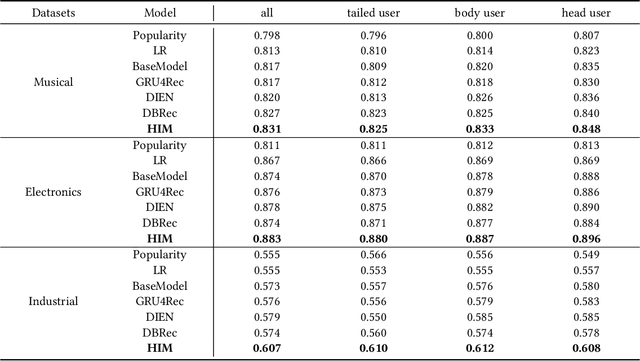
User behavior modeling is a key technique for recommender systems. However, most methods focus on head users with large-scale interactions and hence suffer from data sparsity issues. Several solutions integrate side information such as demographic features and product reviews, another is to transfer knowledge from other rich data sources. We argue that current methods are limited by the strict privacy policy and have low scalability in real-world applications and few works consider the behavioral characteristics behind long-tailed users. In this work, we propose the Hybrid Interest Modeling (HIM) network to hybrid both personalized interest and semi-personalized interest in learning long-tailed users' preferences in the recommendation. To achieve this, we first design the User Behavior Pyramid (UBP) module to capture the fine-grained personalized interest of high confidence from sparse even noisy positive feedbacks. Moreover, the individual interaction is too sparse and not enough for modeling user interest adequately, we design the User Behavior Clustering (UBC) module to learn latent user interest groups with self-supervised learning mechanism novelly, which capture coarse-grained semi-personalized interest from group-item interaction data. Extensive experiments on both public and industrial datasets verify the superiority of HIM compared with the state-of-the-art baselines.
An Accurate Model for Predicting the Effect of Context in Word Similarity Based on Bert
May 05, 2020

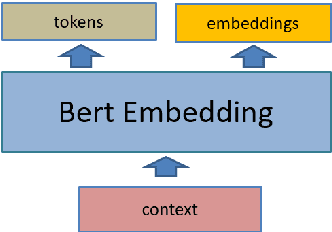
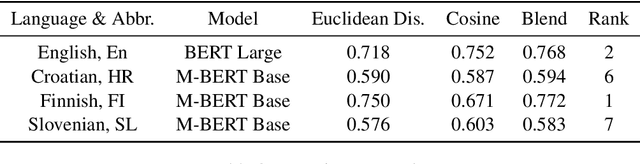
Natural Language Processing (NLP) has been widely used in the semantic analysis in recent years. Our paper mainly discusses a methodology to analyze the effect that context has on human perception of similar words, which is the third task of SemEval 2020. We apply several methods in calculating the distance between two embedding vector generated by Bidirectional Encoder Representation from Transformer (BERT). Our team will_go won the 1st place in Finnish language track of subtask1, the second place in English track of subtask1.