 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Generative Recommender Tokenizer: Recsys-Native Encoding and Semantic Quantization Beyond LLMs
Feb 02, 2026Semantic ID (SID)-based recommendation is a promising paradigm for scaling sequential recommender systems, but existing methods largely follow a semantic-centric pipeline: item embeddings are learned from foundation models and discretized using generic quantization schemes. This design is misaligned with generative recommendation objectives: semantic embeddings are weakly coupled with collaborative prediction, and generic quantization is inefficient at reducing sequential uncertainty for autoregressive modeling. To address these, we propose ReSID, a recommendation-native, principled SID framework that rethinks representation learning and quantization from the perspective of information preservation and sequential predictability, without relying on LLMs. ReSID consists of two components: (i) Field-Aware Masked Auto-Encoding (FAMAE), which learns predictive-sufficient item representations from structured features, and (ii) Globally Aligned Orthogonal Quantization (GAOQ), which produces compact and predictable SID sequences by jointly reducing semantic ambiguity and prefix-conditional uncertainty. Theoretical analysis and extensive experiments across ten datasets show the effectiveness of ReSID. ReSID consistently outperforms strong sequential and SID-based generative baselines by an average of over 10%, while reducing tokenization cost by up to 122x. Code is available at https://github.com/FuCongResearchSquad/ReSID.
Orchestrating Tokens and Sequences: Dynamic Hybrid Policy Optimization for RLVR
Jan 09, 2026Reinforcement Learning with Verifiable Rewards (RLVR) offers a promising framework for optimizing large language models in reasoning tasks. However, existing RLVR algorithms focus on different granularities, and each has complementary strengths and limitations. Group Relative Policy Optimization (GRPO) updates the policy with token-level importance ratios, which preserves fine-grained credit assignment but often suffers from high variance and instability. In contrast, Group Sequence Policy Optimization (GSPO) applies single sequence-level importance ratios across all tokens in a response that better matches sequence-level rewards, but sacrifices token-wise credit assignment. In this paper, we propose Dynamic Hybrid Policy Optimization (DHPO) to bridge GRPO and GSPO within a single clipped surrogate objective. DHPO combines token-level and sequence-level importance ratios using weighting mechanisms. We explore two variants of the mixing mechanism, including an averaged mixing and an entropy-guided mixing. To further stabilize training, we employ a branch-specific clipping strategy that constrains token-level and sequence-level ratios within separate trust regions before mixing, preventing outliers in either branch from dominating the update. Across seven challenging mathematical reasoning benchmarks, experiments on both dense and MoE models from the Qwen3 series show that DHPO consistently outperforms GRPO and GSPO. We will release our code upon acceptance of this paper.
Reveal Hidden Pitfalls and Navigate Next Generation of Vector Similarity Search from Task-Centric Views
Dec 15, 2025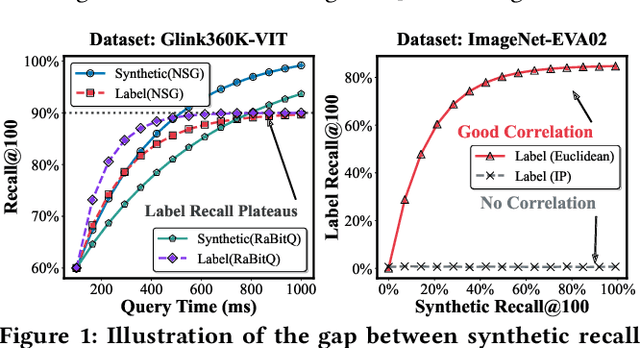

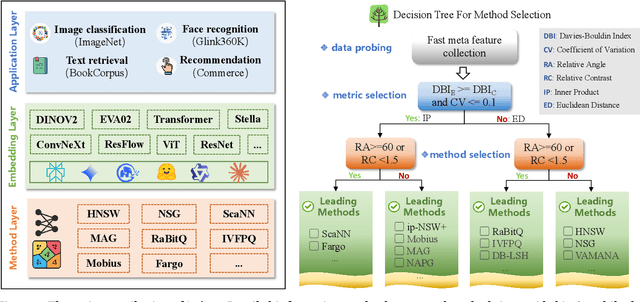
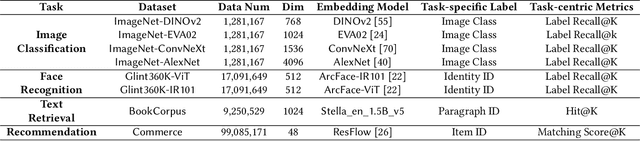
Vector Similarity Search (VSS) in high-dimensional spaces is rapidly emerging as core functionality in next-generation database systems for numerous data-intensive services -- from embedding lookups in large language models (LLMs), to semantic information retrieval and recommendation engines. Current benchmarks, however, evaluate VSS primarily on the recall-latency trade-off against a ground truth defined solely by distance metrics, neglecting how retrieval quality ultimately impacts downstream tasks. This disconnect can mislead both academic research and industrial practice. We present Iceberg, a holistic benchmark suite for end-to-end evaluation of VSS methods in realistic application contexts. From a task-centric view, Iceberg uncovers the Information Loss Funnel, which identifies three principal sources of end-to-end performance degradation: (1) Embedding Loss during feature extraction; (2) Metric Misuse, where distances poorly reflect task relevance; (3) Data Distribution Sensitivity, highlighting index robustness across skews and modalities. For a more comprehensive assessment, Iceberg spans eight diverse datasets across key domains such as image classification, face recognition, text retrieval, and recommendation systems. Each dataset, ranging from 1M to 100M vectors, includes rich, task-specific labels and evaluation metrics, enabling assessment of retrieval algorithms within the full application pipeline rather than in isolation. Iceberg benchmarks 13 state-of-the-art VSS methods and re-ranks them based on application-level metrics, revealing substantial deviations from traditional rankings derived purely from recall-latency evaluations. Building on these insights, we define a set of task-centric meta-features and derive an interpretable decision tree to guide practitioners in selecting and tuning VSS methods for their specific workloads.
Each Prompt Matters: Scaling Reinforcement Learning Without Wasting Rollouts on Hundred-Billion-Scale MoE
Dec 08, 2025We present CompassMax-V3-Thinking, a hundred-billion-scale MoE reasoning model trained with a new RL framework built on one principle: each prompt must matter. Scaling RL to this size exposes critical inefficiencies-zero-variance prompts that waste rollouts, unstable importance sampling over long horizons, advantage inversion from standard reward models, and systemic bottlenecks in rollout processing. To overcome these challenges, we introduce several unified innovations: (1) Multi-Stage Zero-Variance Elimination, which filters out non-informative prompts and stabilizes group-based policy optimization (e.g. GRPO) by removing wasted rollouts; (2) ESPO, an entropy-adaptive optimization method that balances token-level and sequence-level importance sampling to maintain stable learning dynamics; (3) a Router Replay strategy that aligns training-time MoE router decisions with inference-time behavior to mitigate train-infer discrepancies, coupled with a reward model adjustment to prevent advantage inversion; (4) a high-throughput RL system with FP8-precision rollouts, overlapped reward computation, and length-aware scheduling to eliminate performance bottlenecks. Together, these contributions form a cohesive pipeline that makes RL on hundred-billion-scale MoE models stable and efficient. The resulting model delivers strong performance across both internal and public evaluations.
Towards Reliable Evaluation of Large Language Models for Multilingual and Multimodal E-Commerce Applications
Oct 23, 2025Large Language Models (LLMs) excel on general-purpose NLP benchmarks, yet their capabilities in specialized domains remain underexplored. In e-commerce, existing evaluations-such as EcomInstruct, ChineseEcomQA, eCeLLM, and Shopping MMLU-suffer from limited task diversity (e.g., lacking product guidance and after-sales issues), limited task modalities (e.g., absence of multimodal data), synthetic or curated data, and a narrow focus on English and Chinese, leaving practitioners without reliable tools to assess models on complex, real-world shopping scenarios. We introduce EcomEval, a comprehensive multilingual and multimodal benchmark for evaluating LLMs in e-commerce. EcomEval covers six categories and 37 tasks (including 8 multimodal tasks), sourced primarily from authentic customer queries and transaction logs, reflecting the noisy and heterogeneous nature of real business interactions. To ensure both quality and scalability of reference answers, we adopt a semi-automatic pipeline in which large models draft candidate responses subsequently reviewed and modified by over 50 expert annotators with strong e-commerce and multilingual expertise. We define difficulty levels for each question and task category by averaging evaluation scores across models with different sizes and capabilities, enabling challenge-oriented and fine-grained assessment. EcomEval also spans seven languages-including five low-resource Southeast Asian languages-offering a multilingual perspective absent from prior work.
Compass-Thinker-7B Technical Report
Aug 12, 2025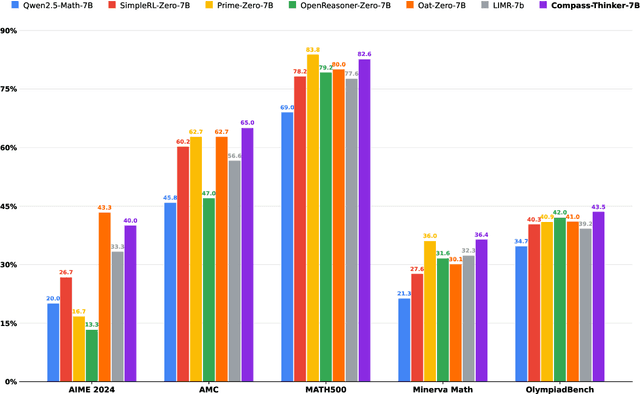

Recent R1-Zero-like research further demonstrates that reasoning extension has given large language models (LLMs) unprecedented reasoning capabilities, and Reinforcement Learning is the core technology to elicit its complex reasoning. However, conducting RL experiments directly on hyperscale models involves high computational costs and resource demands, posing significant risks. We propose the Compass-Thinker-7B model, which aims to explore the potential of Reinforcement Learning with less computational resources and costs, and provides insights for further research into RL recipes for larger models. Compass-Thinker-7B is trained from an open source model through a specially designed Reinforcement Learning Pipeline. we curate a dataset of 30k verifiable mathematics problems for the Reinforcement Learning Pipeline. By configuring data and training settings with different difficulty distributions for different stages, the potential of the model is gradually released and the training efficiency is improved. Extensive evaluations show that Compass-Thinker-7B possesses exceptional reasoning potential, and achieves superior performance on mathematics compared to the same-sized RL model.Especially in the challenging AIME2024 evaluation, Compass-Thinker-7B achieves 40% accuracy.
Embed Progressive Implicit Preference in Unified Space for Deep Collaborative Filtering
May 28, 2025Embedding-based collaborative filtering, often coupled with nearest neighbor search, is widely deployed in large-scale recommender systems for personalized content selection. Modern systems leverage multiple implicit feedback signals (e.g., clicks, add to cart, purchases) to model user preferences comprehensively. However, prevailing approaches adopt a feedback-wise modeling paradigm, which (1) fails to capture the structured progression of user engagement entailed among different feedback and (2) embeds feedback-specific information into disjoint spaces, making representations incommensurable, increasing system complexity, and leading to suboptimal retrieval performance. A promising alternative is Ordinal Logistic Regression (OLR), which explicitly models discrete ordered relations. However, existing OLR-based recommendation models mainly focus on explicit feedback (e.g., movie ratings) and struggle with implicit, correlated feedback, where ordering is vague and non-linear. Moreover, standard OLR lacks flexibility in handling feedback-dependent covariates, resulting in suboptimal performance in real-world systems. To address these limitations, we propose Generalized Neural Ordinal Logistic Regression (GNOLR), which encodes multiple feature-feedback dependencies into a unified, structured embedding space and enforces feedback-specific dependency learning through a nested optimization framework. Thus, GNOLR enhances predictive accuracy, captures the progression of user engagement, and simplifies the retrieval process. We establish a theoretical comparison with existing paradigms, demonstrating how GNOLR avoids disjoint spaces while maintaining effectiveness. Extensive experiments on ten real-world datasets show that GNOLR significantly outperforms state-of-the-art methods in efficiency and adaptability.
Optimal Transport-Based Token Weighting scheme for Enhanced Preference Optimization
May 24, 2025Direct Preference Optimization (DPO) has emerged as a promising framework for aligning Large Language Models (LLMs) with human preferences by directly optimizing the log-likelihood difference between chosen and rejected responses. However, existing methods assign equal importance to all tokens in the response, while humans focus on more meaningful parts. This leads to suboptimal preference optimization, as irrelevant or noisy tokens disproportionately influence DPO loss. To address this limitation, we propose \textbf{O}ptimal \textbf{T}ransport-based token weighting scheme for enhancing direct \textbf{P}reference \textbf{O}ptimization (OTPO). By emphasizing semantically meaningful token pairs and de-emphasizing less relevant ones, our method introduces a context-aware token weighting scheme that yields a more contrastive reward difference estimate. This adaptive weighting enhances reward stability, improves interpretability, and ensures that preference optimization focuses on meaningful differences between responses. Extensive experiments have validated OTPO's effectiveness in improving instruction-following ability across various settings\footnote{Code is available at https://github.com/Mimasss2/OTPO.}.
Stitching Inner Product and Euclidean Metrics for Topology-aware Maximum Inner Product Search
Apr 21, 2025Maximum Inner Product Search (MIPS) is a fundamental challenge in machine learning and information retrieval, particularly in high-dimensional data applications. Existing approaches to MIPS either rely solely on Inner Product (IP) similarity, which faces issues with local optima and redundant computations, or reduce the MIPS problem to the Nearest Neighbor Search under the Euclidean metric via space projection, leading to topology destruction and information loss. Despite the divergence of the two paradigms, we argue that there is no inherent binary opposition between IP and Euclidean metrics. By stitching IP and Euclidean in the design of indexing and search algorithms, we can significantly enhance MIPS performance. Specifically, this paper explores the theoretical and empirical connections between these two metrics from the MIPS perspective. Our investigation, grounded in graph-based search, reveals that different indexing and search strategies offer distinct advantages for MIPS, depending on the underlying data topology. Building on these insights, we introduce a novel graph-based index called Metric-Amphibious Graph (MAG) and a corresponding search algorithm, Adaptive Navigation with Metric Switch (ANMS). To facilitate parameter tuning for optimal performance, we identify three statistical indicators that capture essential data topology properties and correlate strongly with parameter tuning. Extensive experiments on 12 real-world datasets demonstrate that MAG outperforms existing state-of-the-art methods, achieving up to 4x search speedup while maintaining adaptability and scalability.
Establishing Reliability Metrics for Reward Models in Large Language Models
Apr 21, 2025The reward model (RM) that represents human preferences plays a crucial role in optimizing the outputs of large language models (LLMs), e.g., through reinforcement learning from human feedback (RLHF) or rejection sampling. However, a long challenge for RM is its uncertain reliability, i.e., LLM outputs with higher rewards may not align with actual human preferences. Currently, there is a lack of a convincing metric to quantify the reliability of RMs. To bridge this gap, we propose the \textit{\underline{R}eliable at \underline{$\eta$}} (RETA) metric, which directly measures the reliability of an RM by evaluating the average quality (scored by an oracle) of the top $\eta$ quantile responses assessed by an RM. On top of RETA, we present an integrated benchmarking pipeline that allows anyone to evaluate their own RM without incurring additional Oracle labeling costs. Extensive experimental studies demonstrate the superior stability of RETA metric, providing solid evaluations of the reliability of various publicly available and proprietary RMs. When dealing with an unreliable RM, we can use the RETA metric to identify the optimal quantile from which to select the responses.