 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Learning of New Diseases through Knowledge-Enhanced Initialization for Federated Adapter Tuning
Aug 14, 2025

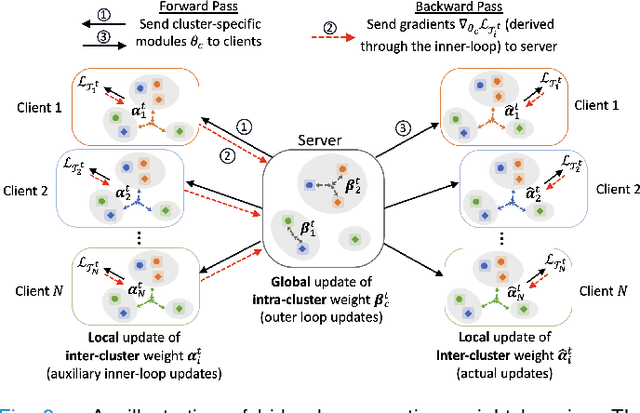
In healthcare, federated learning (FL) is a widely adopted framework that enables privacy-preserving collaboration among medical institutions. With large foundation models (FMs) demonstrating impressive capabilities, using FMs in FL through cost-efficient adapter tuning has become a popular approach. Given the rapidly evolving healthcare environment, it is crucial for individual clients to quickly adapt to new tasks or diseases by tuning adapters while drawing upon past experiences. In this work, we introduce Federated Knowledge-Enhanced Initialization (FedKEI), a novel framework that leverages cross-client and cross-task transfer from past knowledge to generate informed initializations for learning new tasks with adapters. FedKEI begins with a global clustering process at the server to generalize knowledge across tasks, followed by the optimization of aggregation weights across clusters (inter-cluster weights) and within each cluster (intra-cluster weights) to personalize knowledge transfer for each new task. To facilitate more effective learning of the inter- and intra-cluster weights, we adopt a bi-level optimization scheme that collaboratively learns the global intra-cluster weights across clients and optimizes the local inter-cluster weights toward each client's task objective. Extensive experiments on three benchmark datasets of different modalities, including dermatology, chest X-rays, and retinal OCT, demonstrate FedKEI's advantage in adapting to new diseases compared to state-of-the-art methods.
Look Back for More: Harnessing Historical Sequential Updates for Personalized Federated Adapter Tuning
Jan 03, 2025



Personalized federated learning (PFL) studies effective model personalization to address the data heterogeneity issue among clients in traditional federated learning (FL). Existing PFL approaches mainly generate personalized models by relying solely on the clients' latest updated models while ignoring their previous updates, which may result in suboptimal personalized model learning. To bridge this gap, we propose a novel framework termed pFedSeq, designed for personalizing adapters to fine-tune a foundation model in FL. In pFedSeq, the server maintains and trains a sequential learner, which processes a sequence of past adapter updates from clients and generates calibrations for personalized adapters. To effectively capture the cross-client and cross-step relations hidden in previous updates and generate high-performing personalized adapters, pFedSeq adopts the powerful selective state space model (SSM) as the architecture of sequential learner. Through extensive experiments on four public benchmark datasets, we demonstrate the superiority of pFedSeq over state-of-the-art PFL methods.
Learning Gradient-based Mixup towards Flatter Minima for Domain Generalization
Sep 29, 2022
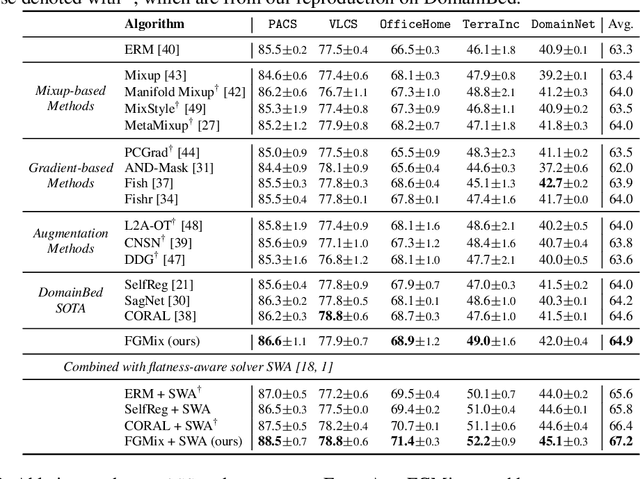

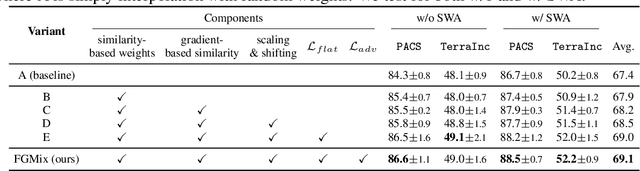
To address the distribution shifts between training and test data, domain generalization (DG) leverages multiple source domains to learn a model that generalizes well to unseen domains. However, existing DG methods generally suffer from overfitting to the source domains, partly due to the limited coverage of the expected region in feature space. Motivated by this, we propose to perform mixup with data interpolation and extrapolation to cover the potential unseen regions. To prevent the detrimental effects of unconstrained extrapolation, we carefully design a policy to generate the instance weights, named Flatness-aware Gradient-based Mixup (FGMix). The policy employs a gradient-based similarity to assign greater weights to instances that carry more invariant information, and learns the similarity function towards flatter minima for better generalization. On the DomainBed benchmark, we validate the efficacy of various designs of FGMix and demonstrate its superiority over other DG algorithms.
Learning an Adaptive Meta Model-Generator for Incrementally Updating Recommender Systems
Nov 08, 2021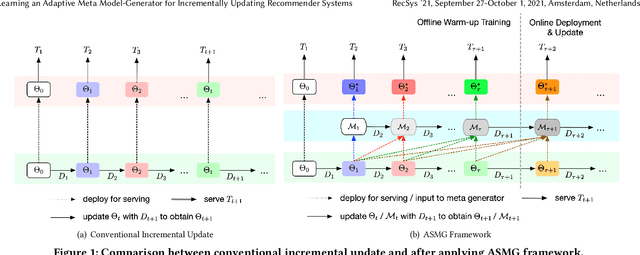
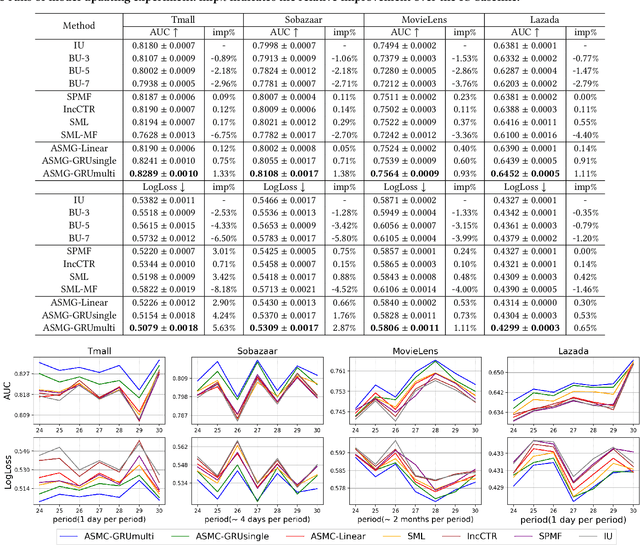
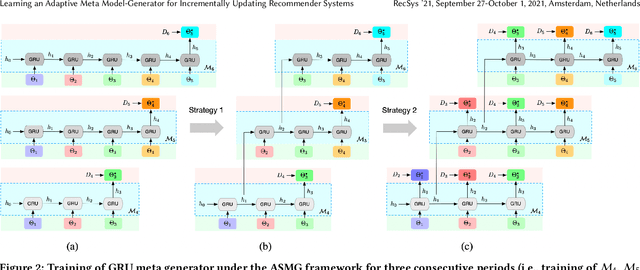
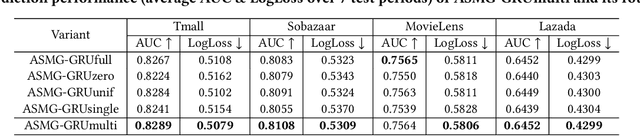
Recommender Systems (RSs) in real-world applications often deal with billions of user interactions daily. To capture the most recent trends effectively, it is common to update the model incrementally using only the newly arrived data. However, this may impede the model's ability to retain long-term information due to the potential overfitting and forgetting issues. To address this problem, we propose a novel Adaptive Sequential Model Generation (ASMG) framework, which generates a better serving model from a sequence of historical models via a meta generator. For the design of the meta generator, we propose to employ Gated Recurrent Units (GRUs) to leverage its ability to capture the long-term dependencies. We further introduce some novel strategies to apply together with the GRU meta generator, which not only improve its computational efficiency but also enable more accurate sequential modeling. By instantiating the model-agnostic framework on a general deep learning-based RS model, we demonstrate that our method achieves state-of-the-art performance on three public datasets and one industrial dataset.