 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Learning of New Diseases through Knowledge-Enhanced Initialization for Federated Adapter Tuning
Aug 14, 2025

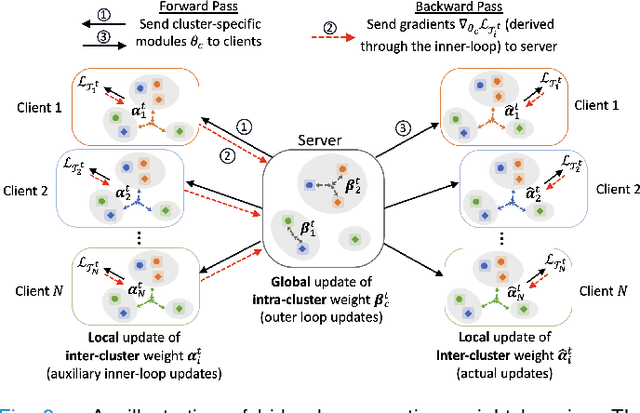
In healthcare, federated learning (FL) is a widely adopted framework that enables privacy-preserving collaboration among medical institutions. With large foundation models (FMs) demonstrating impressive capabilities, using FMs in FL through cost-efficient adapter tuning has become a popular approach. Given the rapidly evolving healthcare environment, it is crucial for individual clients to quickly adapt to new tasks or diseases by tuning adapters while drawing upon past experiences. In this work, we introduce Federated Knowledge-Enhanced Initialization (FedKEI), a novel framework that leverages cross-client and cross-task transfer from past knowledge to generate informed initializations for learning new tasks with adapters. FedKEI begins with a global clustering process at the server to generalize knowledge across tasks, followed by the optimization of aggregation weights across clusters (inter-cluster weights) and within each cluster (intra-cluster weights) to personalize knowledge transfer for each new task. To facilitate more effective learning of the inter- and intra-cluster weights, we adopt a bi-level optimization scheme that collaboratively learns the global intra-cluster weights across clients and optimizes the local inter-cluster weights toward each client's task objective. Extensive experiments on three benchmark datasets of different modalities, including dermatology, chest X-rays, and retinal OCT, demonstrate FedKEI's advantage in adapting to new diseases compared to state-of-the-art methods.
Comparing Uncertainty Measurement and Mitigation Methods for Large Language Models: A Systematic Review
Apr 25, 2025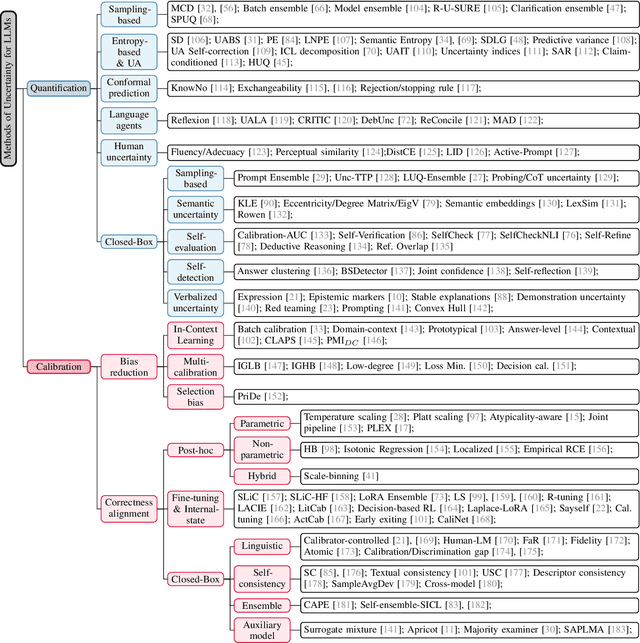
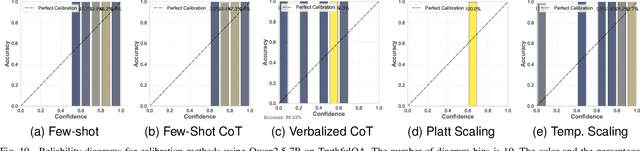
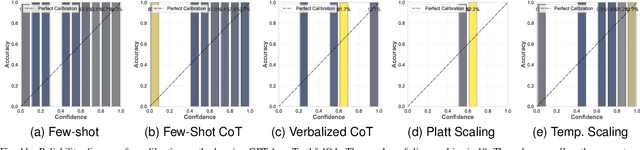
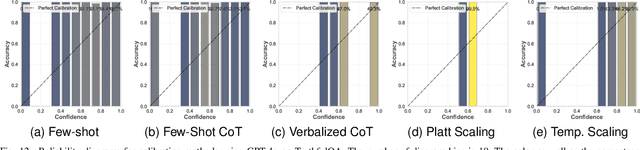
Large Language Models (LLMs) have been transformative across many domains. However, hallucination -- confidently outputting incorrect information -- remains one of the leading challenges for LLMs. This raises the question of how to accurately assess and quantify the uncertainty of LLMs. Extensive literature on traditional models has explored Uncertainty Quantification (UQ) to measure uncertainty and employed calibration techniques to address the misalignment between uncertainty and accuracy. While some of these methods have been adapted for LLMs, the literature lacks an in-depth analysis of their effectiveness and does not offer a comprehensive benchmark to enable insightful comparison among existing solutions. In this work, we fill this gap via a systematic survey of representative prior works on UQ and calibration for LLMs and introduce a rigorous benchmark. Using two widely used reliability datasets, we empirically evaluate six related methods, which justify the significant findings of our review. Finally, we provide outlooks for key future directions and outline open challenges. To the best of our knowledge, this survey is the first dedicated study to review the calibration methods and relevant metrics for LLMs.
AiRacleX: Automated Detection of Price Oracle Manipulations via LLM-Driven Knowledge Mining and Prompt Generation
Feb 10, 2025



Decentralized finance applications depend on accurate price oracles to ensure secure transactions, yet these oracles are highly vulnerable to manipulation, enabling attackers to exploit smart contract vulnerabilities for unfair asset valuation and financial gain. Detecting such manipulations traditionally relies on the manual effort of experienced experts, presenting significant challenges. In this paper, we propose a novel LLM-driven framework that automates the detection of price oracle manipulations by leveraging the complementary strengths of different LLM models. Our approach begins with domain-specific knowledge extraction, where an LLM model synthesizes precise insights about price oracle vulnerabilities from top-tier academic papers, eliminating the need for profound expertise from developers or auditors. This knowledge forms the foundation for a second LLM model to generate structured, context-aware chain of thought prompts, which guide a third LLM model in accurately identifying manipulation patterns in smart contracts. We validate the framework effectiveness through experiments on 60 known vulnerabilities from 46 real-world DeFi attacks or projects spanning 2021 to 2023. The best performing combination of LLMs (Haiku-Haiku-4o-mini) identified by AiRacleX demonstrate a 2.58-times improvement in recall (0.667 vs 0.259) compared to the state-of-the-art tool GPTScan, while maintaining comparable precision. Furthermore, our framework demonstrates the feasibility of replacing commercial models with open-source alternatives, enhancing privacy and security for developers.
Maximizing Uncertainty for Federated learning via Bayesian Optimisation-based Model Poisoning
Jan 15, 2025As we transition from Narrow Artificial Intelligence towards Artificial Super Intelligence, users are increasingly concerned about their privacy and the trustworthiness of machine learning (ML) technology. A common denominator for the metrics of trustworthiness is the quantification of uncertainty inherent in DL algorithms, and specifically in the model parameters, input data, and model predictions. One of the common approaches to address privacy-related issues in DL is to adopt distributed learning such as federated learning (FL), where private raw data is not shared among users. Despite the privacy-preserving mechanisms in FL, it still faces challenges in trustworthiness. Specifically, the malicious users, during training, can systematically create malicious model parameters to compromise the models predictive and generative capabilities, resulting in high uncertainty about their reliability. To demonstrate malicious behaviour, we propose a novel model poisoning attack method named Delphi which aims to maximise the uncertainty of the global model output. We achieve this by taking advantage of the relationship between the uncertainty and the model parameters of the first hidden layer of the local model. Delphi employs two types of optimisation , Bayesian Optimisation and Least Squares Trust Region, to search for the optimal poisoned model parameters, named as Delphi-BO and Delphi-LSTR. We quantify the uncertainty using the KL Divergence to minimise the distance of the predictive probability distribution towards an uncertain distribution of model output. Furthermore, we establish a mathematical proof for the attack effectiveness demonstrated in FL. Numerical results demonstrate that Delphi-BO induces a higher amount of uncertainty than Delphi-LSTR highlighting vulnerability of FL systems to model poisoning attacks.
Look Back for More: Harnessing Historical Sequential Updates for Personalized Federated Adapter Tuning
Jan 03, 2025



Personalized federated learning (PFL) studies effective model personalization to address the data heterogeneity issue among clients in traditional federated learning (FL). Existing PFL approaches mainly generate personalized models by relying solely on the clients' latest updated models while ignoring their previous updates, which may result in suboptimal personalized model learning. To bridge this gap, we propose a novel framework termed pFedSeq, designed for personalizing adapters to fine-tune a foundation model in FL. In pFedSeq, the server maintains and trains a sequential learner, which processes a sequence of past adapter updates from clients and generates calibrations for personalized adapters. To effectively capture the cross-client and cross-step relations hidden in previous updates and generate high-performing personalized adapters, pFedSeq adopts the powerful selective state space model (SSM) as the architecture of sequential learner. Through extensive experiments on four public benchmark datasets, we demonstrate the superiority of pFedSeq over state-of-the-art PFL methods.
Blockchain Data Analysis in the Era of Large-Language Models
Dec 09, 2024



Blockchain data analysis is essential for deriving insights, tracking transactions, identifying patterns, and ensuring the integrity and security of decentralized networks. It plays a key role in various areas, such as fraud detection, regulatory compliance, smart contract auditing, and decentralized finance (DeFi) risk management. However, existing blockchain data analysis tools face challenges, including data scarcity, the lack of generalizability, and the lack of reasoning capability. We believe large language models (LLMs) can mitigate these challenges; however, we have not seen papers discussing LLM integration in blockchain data analysis in a comprehensive and systematic way. This paper systematically explores potential techniques and design patterns in LLM-integrated blockchain data analysis. We also outline prospective research opportunities and challenges, emphasizing the need for further exploration in this promising field. This paper aims to benefit a diverse audience spanning academia, industry, and policy-making, offering valuable insights into the integration of LLMs in blockchain data analysis.
An Aggregation-Free Federated Learning for Tackling Data Heterogeneity
Apr 29, 2024The performance of Federated Learning (FL) hinges on the effectiveness of utilizing knowledge from distributed datasets. Traditional FL methods adopt an aggregate-then-adapt framework, where clients update local models based on a global model aggregated by the server from the previous training round. This process can cause client drift, especially with significant cross-client data heterogeneity, impacting model performance and convergence of the FL algorithm. To address these challenges, we introduce FedAF, a novel aggregation-free FL algorithm. In this framework, clients collaboratively learn condensed data by leveraging peer knowledge, the server subsequently trains the global model using the condensed data and soft labels received from the clients. FedAF inherently avoids the issue of client drift, enhances the quality of condensed data amid notable data heterogeneity, and improves the global model performance. Extensive numerical studies on several popular benchmark datasets show FedAF surpasses various state-of-the-art FL algorithms in handling label-skew and feature-skew data heterogeneity, leading to superior global model accuracy and faster convergence.
FedUKD: Federated UNet Model with Knowledge Distillation for Land Use Classification from Satellite and Street Views
Dec 05, 2022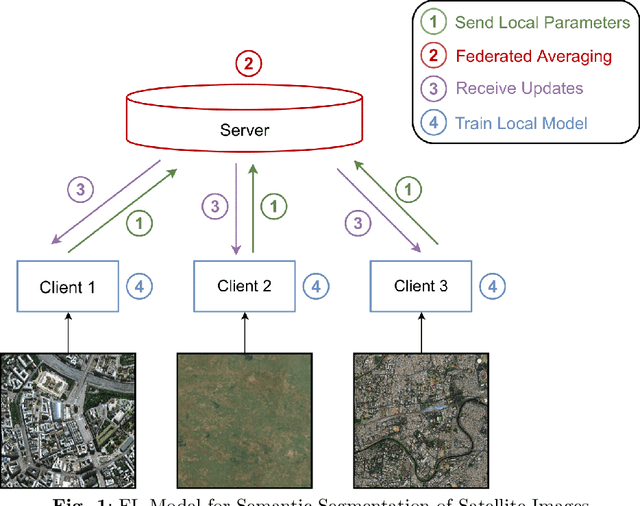

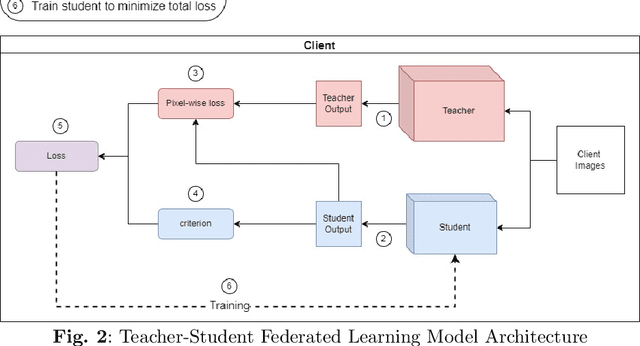
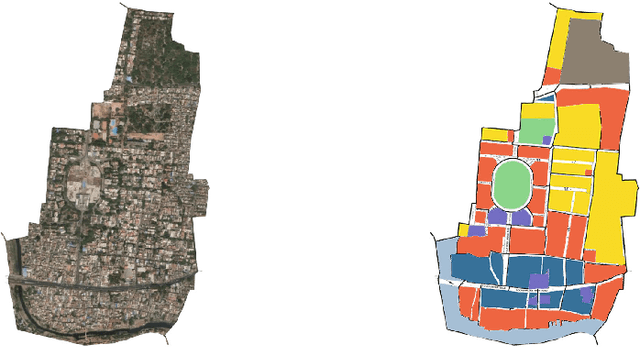
Federated Deep Learning frameworks can be used strategically to monitor Land Use locally and infer environmental impacts globally. Distributed data from across the world would be needed to build a global model for Land Use classification. The need for a Federated approach in this application domain would be to avoid transfer of data from distributed locations and save network bandwidth to reduce communication cost. We use a Federated UNet model for Semantic Segmentation of satellite and street view images. The novelty of the proposed architecture is the integration of Knowledge Distillation to reduce communication cost and response time. The accuracy obtained was above 95% and we also brought in a significant model compression to over 17 times and 62 times for street View and satellite images respectively. Our proposed framework has the potential to be a game-changer in real-time tracking of climate change across the planet.