 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Uncertainty Measurement and Mitigation Methods for Large Language Models: A Systematic Review
Apr 25, 2025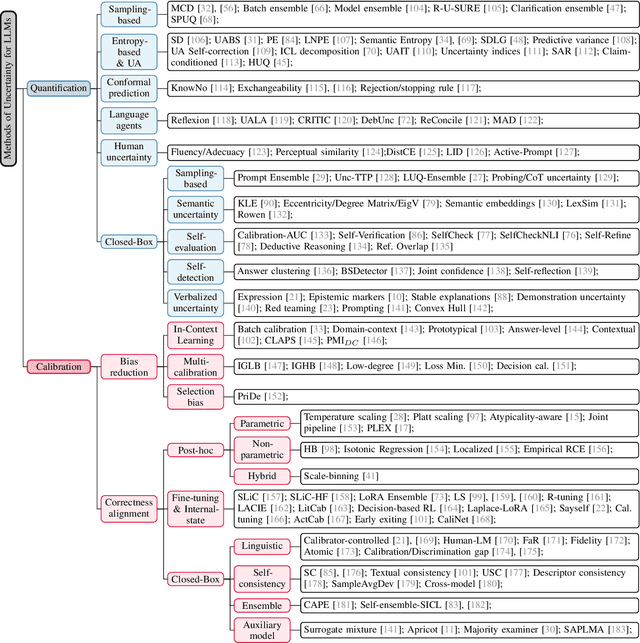
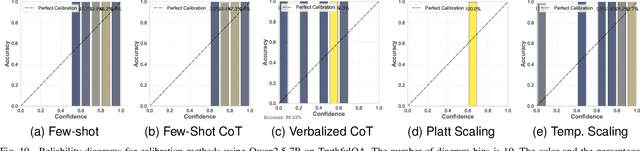
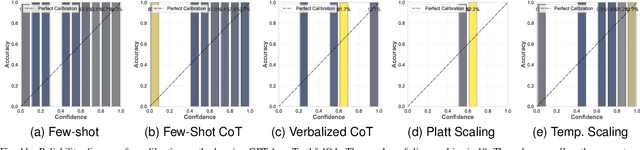
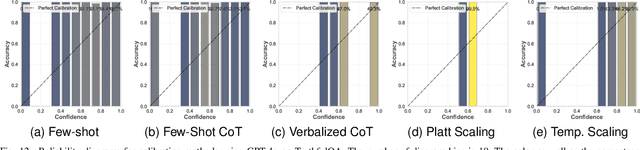
Large Language Models (LLMs) have been transformative across many domains. However, hallucination -- confidently outputting incorrect information -- remains one of the leading challenges for LLMs. This raises the question of how to accurately assess and quantify the uncertainty of LLMs. Extensive literature on traditional models has explored Uncertainty Quantification (UQ) to measure uncertainty and employed calibration techniques to address the misalignment between uncertainty and accuracy. While some of these methods have been adapted for LLMs, the literature lacks an in-depth analysis of their effectiveness and does not offer a comprehensive benchmark to enable insightful comparison among existing solutions. In this work, we fill this gap via a systematic survey of representative prior works on UQ and calibration for LLMs and introduce a rigorous benchmark. Using two widely used reliability datasets, we empirically evaluate six related methods, which justify the significant findings of our review. Finally, we provide outlooks for key future directions and outline open challenges. To the best of our knowledge, this survey is the first dedicated study to review the calibration methods and relevant metrics for LLMs.
Blockchain Data Analysis in the Era of Large-Language Models
Dec 09, 2024



Blockchain data analysis is essential for deriving insights, tracking transactions, identifying patterns, and ensuring the integrity and security of decentralized networks. It plays a key role in various areas, such as fraud detection, regulatory compliance, smart contract auditing, and decentralized finance (DeFi) risk management. However, existing blockchain data analysis tools face challenges, including data scarcity, the lack of generalizability, and the lack of reasoning capability. We believe large language models (LLMs) can mitigate these challenges; however, we have not seen papers discussing LLM integration in blockchain data analysis in a comprehensive and systematic way. This paper systematically explores potential techniques and design patterns in LLM-integrated blockchain data analysis. We also outline prospective research opportunities and challenges, emphasizing the need for further exploration in this promising field. This paper aims to benefit a diverse audience spanning academia, industry, and policy-making, offering valuable insights into the integration of LLMs in blockchain data analysis.
Identifying the Key Attributes in an Unlabeled Event Log for Automated Process Discovery
Jan 27, 2023



Process mining discovers and analyzes a process model from historical event logs. The prior art methods use the attributes of case-id, activity, and timestamp hidden in an event log as clues to discover a process model. However, a user needs to manually specify them, and this can be an exhaustive task. In this paper, we propose a two-stage key attribute identification method to avoid such a manual investigation, and thus this is toward fully automated process discovery. One of the challenging tasks is how to avoid exhaustive computation due to combinatorial explosion. For this, we narrow down candidates for each key attribute by using supervised machine learning in the first stage and identify the best combination of the in the second stage. Our computational complexity can be reduced from $\mathcal{O}(N^3)$ to $\mathcal{O}(k^3)$ where $N$ and $k$ are the numbers of columns and candidates we keep in the first stage, and usually $k$ is much smaller than $N$. We evaluated our method with 14 open datasets and showed that our method could identify the key attributes even with $k = 2$ for about 20 seconds for many datasets.
Decentral and Incentivized Federated Learning Frameworks: A Systematic Literature Review
May 18, 2022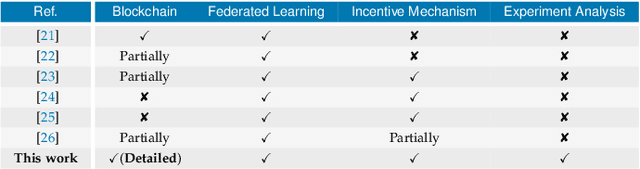
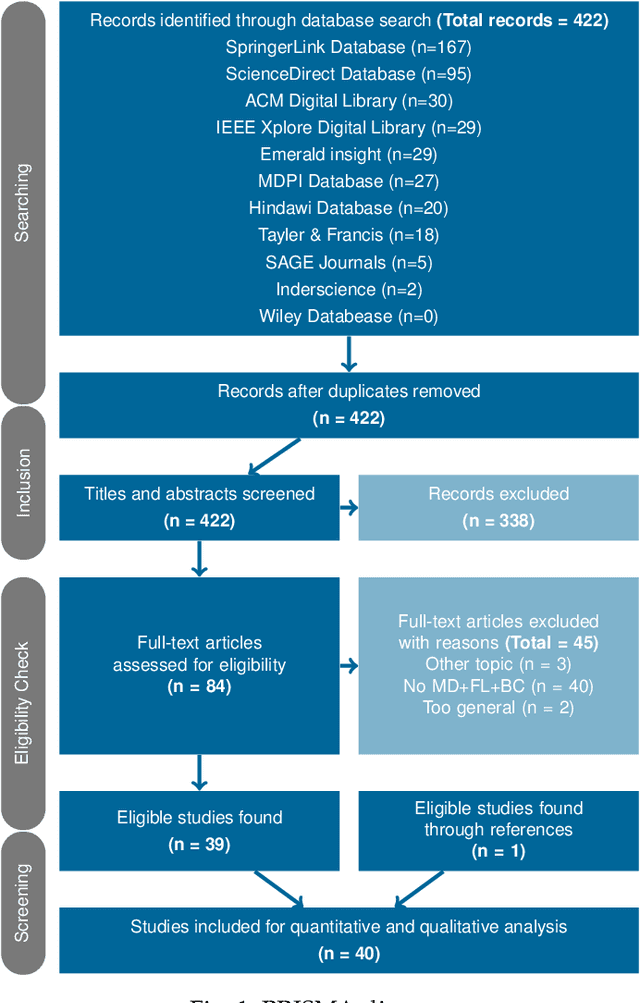
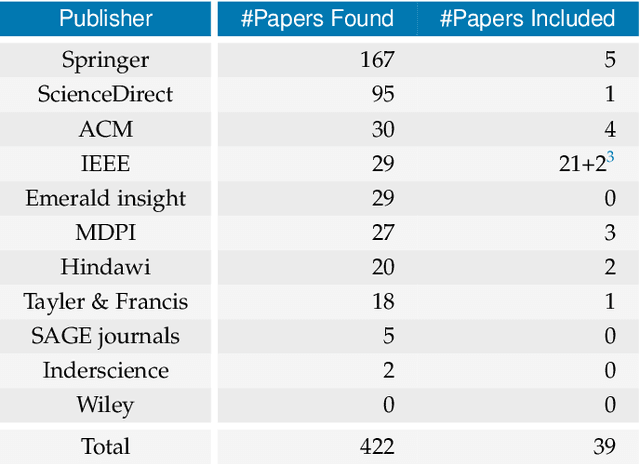
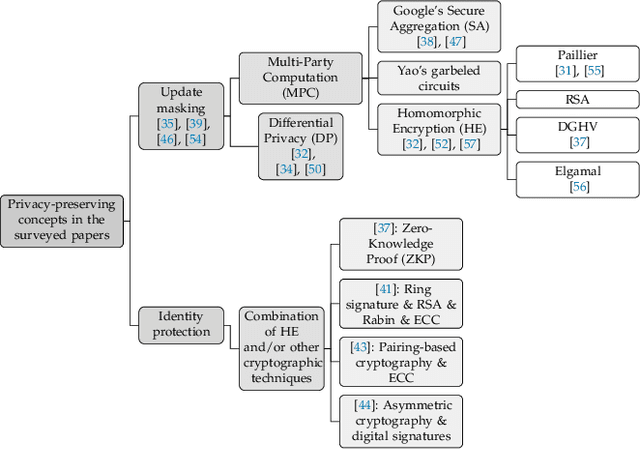
The advent of Federated Learning (FL) has ignited a new paradigm for parallel and confidential decentralized Machine Learning (ML) with the potential of utilizing the computational power of a vast number of IoT, mobile and edge devices without data leaving the respective device, ensuring privacy by design. Yet, in order to scale this new paradigm beyond small groups of already entrusted entities towards mass adoption, the Federated Learning Framework (FLF) has to become (i) truly decentralized and (ii) participants have to be incentivized. This is the first systematic literature review analyzing holistic FLFs in the domain of both, decentralized and incentivized federated learning. 422 publications were retrieved, by querying 12 major scientific databases. Finally, 40 articles remained after a systematic review and filtering process for in-depth examination. Although having massive potential to direct the future of a more distributed and secure AI, none of the analyzed FLF is production-ready. The approaches vary heavily in terms of use-cases, system design, solved issues and thoroughness. We are the first to provide a systematic approach to classify and quantify differences between FLF, exposing limitations of current works and derive future directions for research in this novel domain.