 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Generative Recommender Tokenizer: Recsys-Native Encoding and Semantic Quantization Beyond LLMs
Feb 02, 2026Semantic ID (SID)-based recommendation is a promising paradigm for scaling sequential recommender systems, but existing methods largely follow a semantic-centric pipeline: item embeddings are learned from foundation models and discretized using generic quantization schemes. This design is misaligned with generative recommendation objectives: semantic embeddings are weakly coupled with collaborative prediction, and generic quantization is inefficient at reducing sequential uncertainty for autoregressive modeling. To address these, we propose ReSID, a recommendation-native, principled SID framework that rethinks representation learning and quantization from the perspective of information preservation and sequential predictability, without relying on LLMs. ReSID consists of two components: (i) Field-Aware Masked Auto-Encoding (FAMAE), which learns predictive-sufficient item representations from structured features, and (ii) Globally Aligned Orthogonal Quantization (GAOQ), which produces compact and predictable SID sequences by jointly reducing semantic ambiguity and prefix-conditional uncertainty. Theoretical analysis and extensive experiments across ten datasets show the effectiveness of ReSID. ReSID consistently outperforms strong sequential and SID-based generative baselines by an average of over 10%, while reducing tokenization cost by up to 122x. Code is available at https://github.com/FuCongResearchSquad/ReSID.
Recurrent Temporal Revision Graph Networks
Sep 26, 2023Temporal graphs offer more accurate modeling of many real-world scenarios than static graphs. However, neighbor aggregation, a critical building block of graph networks, for temporal graphs, is currently straightforwardly extended from that of static graphs. It can be computationally expensive when involving all historical neighbors during such aggregation. In practice, typically only a subset of the most recent neighbors are involved. However, such subsampling leads to incomplete and biased neighbor information. To address this limitation, we propose a novel framework for temporal neighbor aggregation that uses the recurrent neural network with node-wise hidden states to integrate information from all historical neighbors for each node to acquire the complete neighbor information. We demonstrate the superior theoretical expressiveness of the proposed framework as well as its state-of-the-art performance in real-world applications. Notably, it achieves a significant +9.6% improvement on averaged precision in a real-world Ecommerce dataset over existing methods on 2-layer models.
Can Vision-Language Models be a Good Guesser? Exploring VLMs for Times and Location Reasoning
Jul 12, 2023



Vision-Language Models (VLMs) are expected to be capable of reasoning with commonsense knowledge as human beings. One example is that humans can reason where and when an image is taken based on their knowledge. This makes us wonder if, based on visual cues, Vision-Language Models that are pre-trained with large-scale image-text resources can achieve and even outperform human's capability in reasoning times and location. To address this question, we propose a two-stage \recognition\space and \reasoning\space probing task, applied to discriminative and generative VLMs to uncover whether VLMs can recognize times and location-relevant features and further reason about it. To facilitate the investigation, we introduce WikiTiLo, a well-curated image dataset compromising images with rich socio-cultural cues. In the extensive experimental studies, we find that although VLMs can effectively retain relevant features in visual encoders, they still fail to make perfect reasoning. We will release our dataset and codes to facilitate future studies.
BiRA-Net: Bilinear Attention Net for Diabetic Retinopathy Grading
May 15, 2019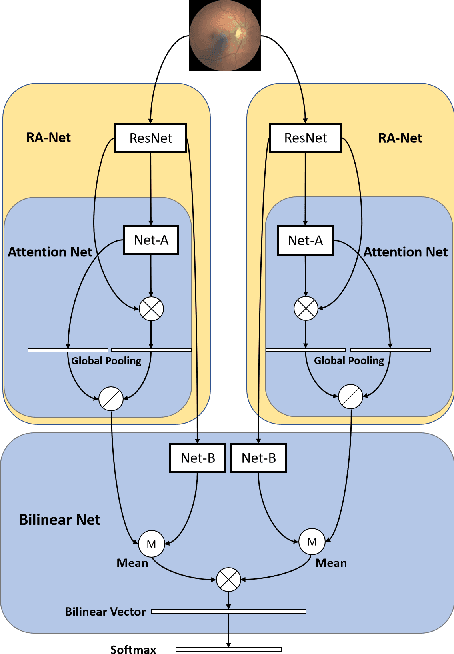
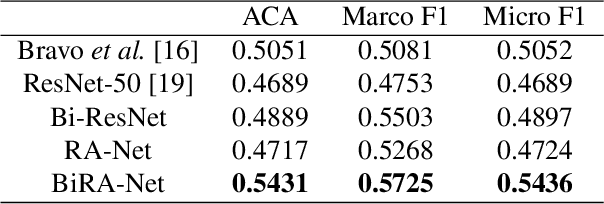


Diabetic retinopathy (DR) is a common retinal disease that leads to blindness. For diagnosis purposes, DR image grading aims to provide automatic DR grade classification, which is not addressed in conventional research methods of binary DR image classification. Small objects in the eye images, like lesions and microaneurysms, are essential to DR grading in medical imaging, but they could easily be influenced by other objects. To address these challenges, we propose a new deep learning architecture, called BiRA-Net, which combines the attention model for feature extraction and bilinear model for fine-grained classification. Furthermore, in considering the distance between different grades of different DR categories, we propose a new loss function, called grading loss, which leads to improved training convergence of the proposed approach. Experimental results are provided to demonstrate the superior performance of the proposed approach.