 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Large-scale Dataset for Robust Complex Anime Scene Text Detection
Oct 09, 2025Current text detection datasets primarily target natural or document scenes, where text typically appear in regular font and shapes, monotonous colors, and orderly layouts. The text usually arranged along straight or curved lines. However, these characteristics differ significantly from anime scenes, where text is often diverse in style, irregularly arranged, and easily confused with complex visual elements such as symbols and decorative patterns. Text in anime scene also includes a large number of handwritten and stylized fonts. Motivated by this gap, we introduce AnimeText, a large-scale dataset containing 735K images and 4.2M annotated text blocks. It features hierarchical annotations and hard negative samples tailored for anime scenarios. %Cross-dataset evaluations using state-of-the-art methods demonstrate that models trained on AnimeText achieve superior performance in anime text detection tasks compared to existing datasets. To evaluate the robustness of AnimeText in complex anime scenes, we conducted cross-dataset benchmarking using state-of-the-art text detection methods. Experimental results demonstrate that models trained on AnimeText outperform those trained on existing datasets in anime scene text detection tasks. AnimeText on HuggingFace: https://huggingface.co/datasets/deepghs/AnimeText
Robustly Invertible Nonlinear Dynamics and the BiLipREN: Contracting Neural Models with Contracting Inverses
May 05, 2025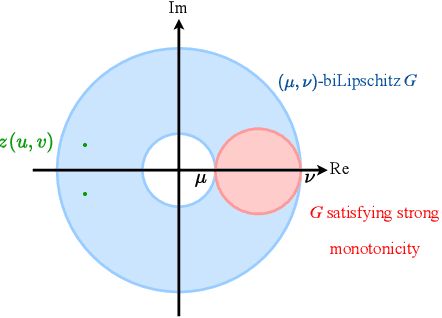
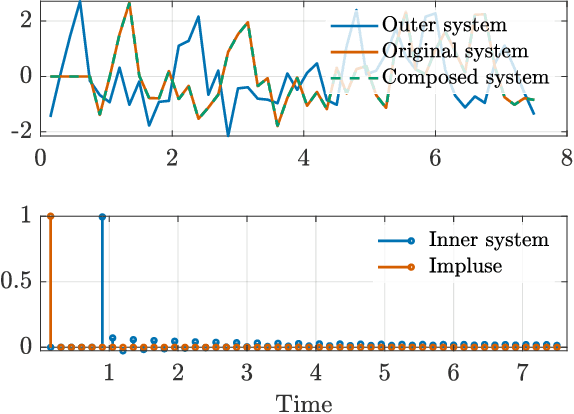
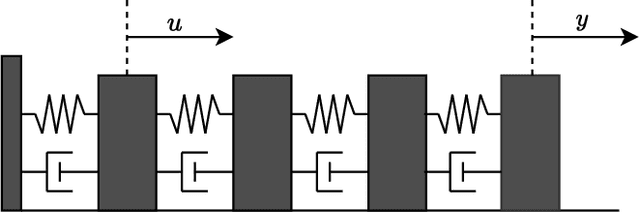
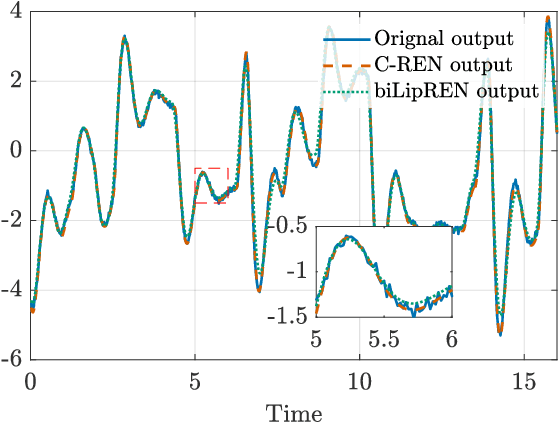
We study the invertibility of nonlinear dynamical systems from the perspective of contraction and incremental stability analysis and propose a new invertible recurrent neural model: the BiLipREN. In particular, we consider a nonlinear state space model to be robustly invertible if an inverse exists with a state space realisation, and both the forward model and its inverse are contracting, i.e. incrementally exponentially stable, and Lipschitz, i.e. have bounded incremental gain. This property of bi-Lipschitzness implies both robustness in the sense of sensitivity to input perturbations, as well as robust distinguishability of different inputs from their corresponding outputs, i.e. the inverse model robustly reconstructs the input sequence despite small perturbations to the initial conditions and measured output. Building on this foundation, we propose a parameterization of neural dynamic models: bi-Lipschitz recurrent equilibrium networks (biLipREN), which are robustly invertible by construction. Moreover, biLipRENs can be composed with orthogonal linear systems to construct more general bi-Lipschitz dynamic models, e.g., a nonlinear analogue of minimum-phase/all-pass (inner/outer) factorization. We illustrate the utility of our proposed approach with numerical examples.
Multi-modal Summarization in Model-Based Engineering: Automotive Software Development Case Study
Mar 06, 2025Multimodal summarization integrating information from diverse data modalities presents a promising solution to aid the understanding of information within various processes. However, the application and advantages of multimodal summarization have not received much attention in model-based engineering (MBE), where it has become a cornerstone in the design and development of complex systems, leveraging formal models to improve understanding, validation and automation throughout the engineering lifecycle. UML and EMF diagrams in model-based engineering contain a large amount of multimodal information and intricate relational data. Hence, our study explores the application of multimodal large language models within the domain of model-based engineering to evaluate their capacity for understanding and identifying relationships, features, and functionalities embedded in UML and EMF diagrams. We aim to demonstrate the transformative potential benefits and limitations of multimodal summarization in improving productivity and accuracy in MBE practices. The proposed approach is evaluated within the context of automotive software development, while many promising state-of-art models were taken into account.
Can Vision-Language Models be a Good Guesser? Exploring VLMs for Times and Location Reasoning
Jul 12, 2023



Vision-Language Models (VLMs) are expected to be capable of reasoning with commonsense knowledge as human beings. One example is that humans can reason where and when an image is taken based on their knowledge. This makes us wonder if, based on visual cues, Vision-Language Models that are pre-trained with large-scale image-text resources can achieve and even outperform human's capability in reasoning times and location. To address this question, we propose a two-stage \recognition\space and \reasoning\space probing task, applied to discriminative and generative VLMs to uncover whether VLMs can recognize times and location-relevant features and further reason about it. To facilitate the investigation, we introduce WikiTiLo, a well-curated image dataset compromising images with rich socio-cultural cues. In the extensive experimental studies, we find that although VLMs can effectively retain relevant features in visual encoders, they still fail to make perfect reasoning. We will release our dataset and codes to facilitate future studies.