 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Generative Recommender Tokenizer: Recsys-Native Encoding and Semantic Quantization Beyond LLMs
Feb 02, 2026Semantic ID (SID)-based recommendation is a promising paradigm for scaling sequential recommender systems, but existing methods largely follow a semantic-centric pipeline: item embeddings are learned from foundation models and discretized using generic quantization schemes. This design is misaligned with generative recommendation objectives: semantic embeddings are weakly coupled with collaborative prediction, and generic quantization is inefficient at reducing sequential uncertainty for autoregressive modeling. To address these, we propose ReSID, a recommendation-native, principled SID framework that rethinks representation learning and quantization from the perspective of information preservation and sequential predictability, without relying on LLMs. ReSID consists of two components: (i) Field-Aware Masked Auto-Encoding (FAMAE), which learns predictive-sufficient item representations from structured features, and (ii) Globally Aligned Orthogonal Quantization (GAOQ), which produces compact and predictable SID sequences by jointly reducing semantic ambiguity and prefix-conditional uncertainty. Theoretical analysis and extensive experiments across ten datasets show the effectiveness of ReSID. ReSID consistently outperforms strong sequential and SID-based generative baselines by an average of over 10%, while reducing tokenization cost by up to 122x. Code is available at https://github.com/FuCongResearchSquad/ReSID.
Recurrent Temporal Revision Graph Networks
Sep 26, 2023Temporal graphs offer more accurate modeling of many real-world scenarios than static graphs. However, neighbor aggregation, a critical building block of graph networks, for temporal graphs, is currently straightforwardly extended from that of static graphs. It can be computationally expensive when involving all historical neighbors during such aggregation. In practice, typically only a subset of the most recent neighbors are involved. However, such subsampling leads to incomplete and biased neighbor information. To address this limitation, we propose a novel framework for temporal neighbor aggregation that uses the recurrent neural network with node-wise hidden states to integrate information from all historical neighbors for each node to acquire the complete neighbor information. We demonstrate the superior theoretical expressiveness of the proposed framework as well as its state-of-the-art performance in real-world applications. Notably, it achieves a significant +9.6% improvement on averaged precision in a real-world Ecommerce dataset over existing methods on 2-layer models.
Makeup216: Logo Recognition with Adversarial Attention Representations
Dec 13, 2021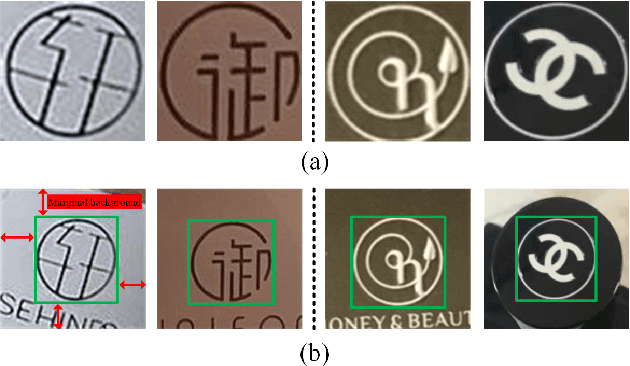
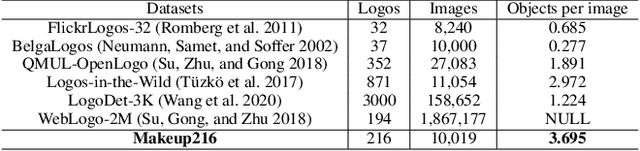

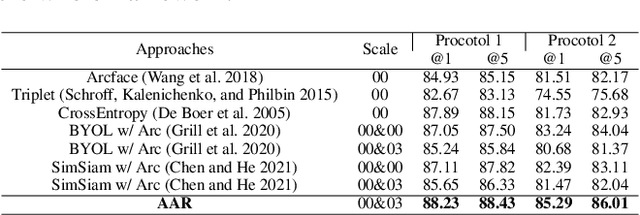
One of the challenges of logo recognition lies in the diversity of forms, such as symbols, texts or a combination of both; further, logos tend to be extremely concise in design while similar in appearance, suggesting the difficulty of learning discriminative representations. To investigate the variety and representation of logo, we introduced Makeup216, the largest and most complex logo dataset in the field of makeup, captured from the real world. It comprises of 216 logos and 157 brands, including 10,019 images and 37,018 annotated logo objects. In addition, we found that the marginal background around the pure logo can provide a important context information and proposed an adversarial attention representation framework (AAR) to attend on the logo subject and auxiliary marginal background separately, which can be combined for better representation. Our proposed framework achieved competitive results on Makeup216 and another large-scale open logo dataset, which could provide fresh thinking for logo recognition. The dataset of Makeup216 and the code of the proposed framework will be released soon.
Matrix embedding method in match for session-based recommendation
Aug 27, 2019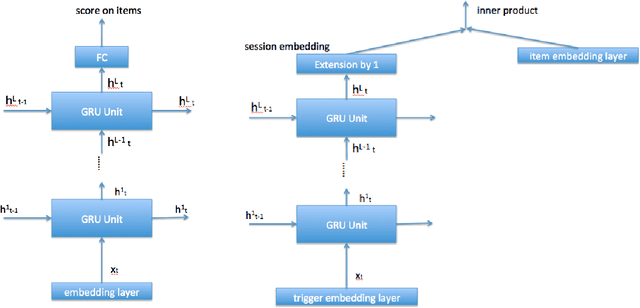



Session based model is widely used in recommend system. It use the user click sequence as input of a Recurrent Neural Network (RNN), and get the output of the RNN network as the vector embedding of the session, and use the inner product of the vector embedding of session and the vector embedding of the next item as the score that is the metric of the interest to the next item. This method can be used for the "match" stage for the recommendation system whose item number is very big by using some index method like KD-Tree or Ball-Tree and etc.. But this method repudiate the variousness of the interest of user in a session. We generated the model to modify the vector embedding of session to a symmetric matrix embedding, that is equivalent to a quadratic form on the vector space of items. The score is builded as the value of the vector embedding of next item under the quadratic form. The eigenvectors of the symmetric matrix embedding corresponding to the positive eigenvalues are conjectured to represent the interests of user in the session. This method can be used for the "match" stage also. The experiments show that this method is better than the method of vector embedding.