 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantically Structured Mixture-of-Experts for Compositional Robotic Manipulation
May 22, 2026Diffusion-based policies have established a new standard for precise robotic manipulation but face a critical scalability bottleneck: high-performance models are computationally expensive, while lightweight alternatives often fail to generalize across diverse multi-task environments. Mixture-of-Experts (MoE) architectures offer a promising path to efficiency by activating only a subset of parameters. However, existing MoE routing mechanisms typically rely on low-level noise or latent statistics, ignoring the compositional nature of manipulation tasks. This can fragment reusable behaviors across experts, limiting interpretability and transferability. We introduce Semantically Structured Mixture-of-Experts Diffusion Policy (SMoDP) for compositional robotic manipulation, a framework that grounds expert specialization in semantic task structure. SMoDP leverages a lightweight, inference-time skill predictor, supervised by offline annotations from Vision-Language Models (VLMs), to route action chunks to experts specialized for specific behavioral phases. To ensure robust assignment, we propose a dual contrastive alignment strategy that grounds multi-modal observations in language-defined skill semantics (Inter-modal) while enforcing routing consistency across visually distinct but functionally related behaviors (Intra-modal). Our approach outperforms representative diffusion and MoE-based baselines on multi-task benchmarks with significantly improved parameter efficiency and demonstrates effective compositional transfer to novel tasks through parameter-efficient fine-tuning. Project website: https://deng-cy20.github.io/SMoDP/
HumanSplatHMR: Closing the Loop Between Human Mesh Recovery and Gaussian Splatting Avatar
May 04, 2026Accurately recovering human pose and appearance from video is an essential component of scene reconstruction, with applications to motion capture, motion prediction, virtual reality, and digital twinning. Despite significant interest in building realistic human avatars from video, this paper demonstrates that existing methods do not accurately recover the 3D geometry of humans. ViT-based approaches are not consistently reliable and can overfit to 2D views, while NeRF- and Gaussian Splatting-based avatars treat pose and appearance separately, limiting rendering generalization to new poses. To resolve these shortcomings, this paper proposes HumanSplatHMR, a joint optimization framework that refines 3D human poses while simultaneously learning a high-fidelity avatar for novel-view and novel-pose synthesis. Our key insight is to close the loop between geometric pose estimation and differentiable rendering. Unlike prior human avatar methods that rely on accurate human pose obtained through motion capture systems or offline refinement, which are impractical in in-the-wild scenarios, our approach uses only human mesh estimates from a state-of-the-art human pose estimator to better reflect real-world conditions. Therefore, instead of using the human pose only as a deformation prior, HumanSplatHMR backpropagates photometric, segmentation, and depth losses through a differentiable renderer to the pose parameters and global position. This coupling refines the global 3D pose over time, improving accuracy and alignment while producing better renderings from novel views. Experiments show consistent improvements over pose recovery baselines that omit image-level refinement and avatar baselines that decouple pose estimation from avatar reconstruction.
TrackDeform3D: Markerless and Autonomous 3D Keypoint Tracking and Dataset Collection for Deformable Objects
Mar 17, 2026Structured 3D representations such as keypoints and meshes offer compact, expressive descriptions of deformable objects, jointly capturing geometric and topological information useful for downstream tasks such as dynamics modeling and motion planning. However, robustly extracting such representations remains challenging, as current perception methods struggle to handle complex deformations. Moreover, large-scale 3D data collection remains a bottleneck: existing approaches either require prohibitive data collection efforts, such as labor-intensive annotation or expensive motion capture setups, or rely on simplifying assumptions that break down in unstructured environments. As a result, large-scale 3D datasets and benchmarks for deformable objects remain scarce. To address these challenges, this paper presents an affordable and autonomous framework for collecting 3D datasets of deformable objects using only RGB-D cameras. The proposed method identifies 3D keypoints and robustly tracks their trajectories, incorporating motion consistency constraints to produce temporally smooth and geometrically coherent data. TrackDeform3D is evaluated against several state-of-the-art tracking methods across diverse object categories and demonstrates consistent improvements in both geometric and tracking accuracy. Using this framework, this paper presents a high-quality, large-scale dataset consisting of 6 deformable objects, totaling 110 minutes of trajectory data.
TheraAgent: Multi-Agent Framework with Self-Evolving Memory and Evidence-Calibrated Reasoning for PET Theranostics
Mar 14, 2026PET theranostics is transforming precision oncology, yet treatment response varies substantially; many patients receiving 177Lu-PSMA radioligand therapy (RLT) for metastatic castration-resistant prostate cancer (mCRPC) fail to respond, demanding reliable pre-therapy prediction. While LLM-based agents have shown remarkable potential in complex medical diagnosis, their application to PET theranostic outcome prediction remains unexplored, which faces three key challenges: (1) data and knowledge scarcity: RLT was only FDA-approved in 2022, yielding few training cases and insufficient domain knowledge in general LLMs; (2) heterogeneous information integration: robust prediction hinges on structured knowledge extraction from PET/CT, laboratory tests, and free-text clinical documentation; (3) evidence-grounded reasoning: clinical decisions must be anchored in trial evidence rather than LLM hallucinations. In this paper, we present TheraAgent, to our knowledge, the first agentic framework for PET theranostics, with three core innovations: (1) Multi-Expert Feature Extraction with Confidence-Weighted Consensus, where three specialized experts process heterogeneous inputs with uncertainty quantification; (2) Self-Evolving Agentic Memory (SEA-Mem), which learns prognostic patterns from accumulated cases, enabling case-based reasoning from limited data; (3) Evidence-Calibrated Reasoning, integrating a curated theranostics knowledge base to ground predictions in VISION/TheraP trial evidence. Evaluated on 35 real patients and 400 synthetic cases, TheraAgent achieves 75.7% overall accuracy on real patients and 87.0% on synthetic cases, outperforming MDAgents and MedAgent-Pro by over 20%. These results highlight a promising blueprint for trustworthy AI agents in PET theranostics, enabling trial-calibrated, multi-source decision support. Code will be released upon acceptance.
Learning Unified Distance Metric for Heterogeneous Attribute Data Clustering
Mar 03, 2026Datasets composed of numerical and categorical attributes (also called mixed data hereinafter) are common in real clustering tasks. Differing from numerical attributes that indicate tendencies between two concepts (e.g., high and low temperature) with their values in well-defined Euclidean distance space, categorical attribute values are different concepts (e.g., different occupations) embedded in an implicit space. Simultaneously exploiting these two very different types of information is an unavoidable but challenging problem, and most advanced attempts either encode the heterogeneous numerical and categorical attributes into one type, or define a unified metric for them for mixed data clustering, leaving their inherent connection unrevealed. This paper, therefore, studies the connection among any-type of attributes and proposes a novel Heterogeneous Attribute Reconstruction and Representation (HARR) learning paradigm accordingly for cluster analysis. The paradigm transforms heterogeneous attributes into a homogeneous status for distance metric learning, and integrates the learning with clustering to automatically adapt the metric to different clustering tasks. Differing from most existing works that directly adopt defined distance metrics or learn attribute weights to search clusters in a subspace. We propose to project the values of each attribute into unified learnable multiple spaces to more finely represent and learn the distance metric for categorical data. HARR is parameter-free, convergence-guaranteed, and can more effectively self-adapt to different sought number of clusters $k$. Extensive experiments illustrate its superiority in terms of accuracy and efficiency.
* ESWA 2025 paper
BiKC+: Bimanual Hierarchical Imitation with Keypose-Conditioned Coordination-Aware Consistency Policies
Jan 17, 2026Robots are essential in industrial manufacturing due to their reliability and efficiency. They excel in performing simple and repetitive unimanual tasks but still face challenges with bimanual manipulation. This difficulty arises from the complexities of coordinating dual arms and handling multi-stage processes. Recent integration of generative models into imitation learning (IL) has made progress in tackling specific challenges. However, few approaches explicitly consider the multi-stage nature of bimanual tasks while also emphasizing the importance of inference speed. In multi-stage tasks, failures or delays at any stage can cascade over time, impacting the success and efficiency of subsequent sub-stages and ultimately hindering overall task performance. In this paper, we propose a novel keypose-conditioned coordination-aware consistency policy tailored for bimanual manipulation. Our framework instantiates hierarchical imitation learning with a high-level keypose predictor and a low-level trajectory generator. The predicted keyposes serve as sub-goals for trajectory generation, indicating targets for individual sub-stages. The trajectory generator is formulated as a consistency model, generating action sequences based on historical observations and predicted keyposes in a single inference step. In particular, we devise an innovative approach for identifying bimanual keyposes, considering both robot-centric action features and task-centric operation styles. Simulation and real-world experiments illustrate that our approach significantly outperforms baseline methods in terms of success rates and operational efficiency. Implementation codes can be found at https://github.com/JoanaHXU/BiKC-plus.
Artificial intelligence for simplified patient-centered dosimetry in radiopharmaceutical therapies
Oct 14, 2025KEY WORDS: Artificial Intelligence (AI), Theranostics, Dosimetry, Radiopharmaceutical Therapy (RPT), Patient-friendly dosimetry KEY POINTS - The rapid evolution of radiopharmaceutical therapy (RPT) highlights the growing need for personalized and patient-centered dosimetry. - Artificial Intelligence (AI) offers solutions to the key limitations in current dosimetry calculations. - The main advances on AI for simplified dosimetry toward patient-friendly RPT are reviewed. - Future directions on the role of AI in RPT dosimetry are discussed.
BagIt! An Adaptive Dual-Arm Manipulation of Fabric Bags for Object Bagging
Sep 11, 2025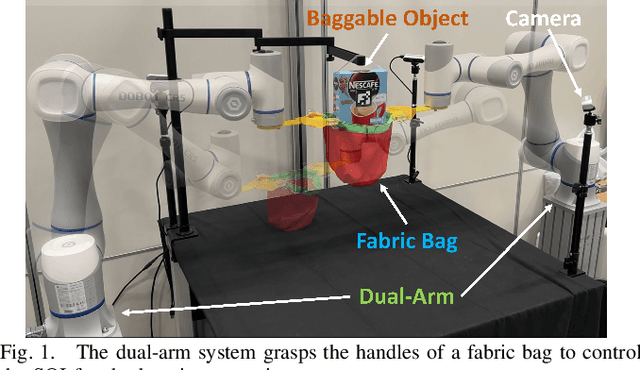
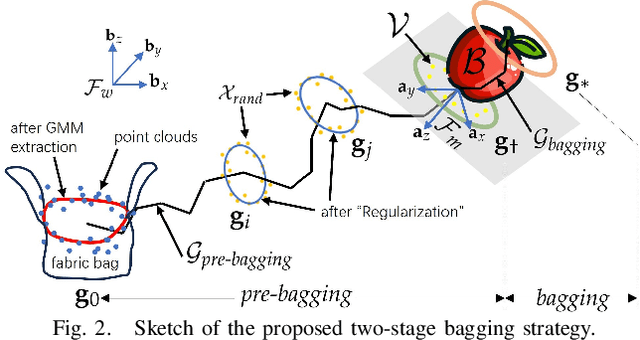
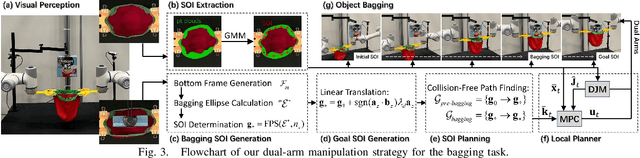
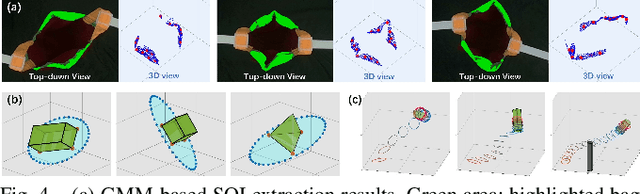
Bagging tasks, commonly found in industrial scenarios, are challenging considering deformable bags' complicated and unpredictable nature. This paper presents an automated bagging system from the proposed adaptive Structure-of-Interest (SOI) manipulation strategy for dual robot arms. The system dynamically adjusts its actions based on real-time visual feedback, removing the need for pre-existing knowledge of bag properties. Our framework incorporates Gaussian Mixture Models (GMM) for estimating SOI states, optimization techniques for SOI generation, motion planning via Constrained Bidirectional Rapidly-exploring Random Tree (CBiRRT), and dual-arm coordination using Model Predictive Control (MPC). Extensive experiments validate the capability of our system to perform precise and robust bagging across various objects, showcasing its adaptability. This work offers a new solution for robotic deformable object manipulation (DOM), particularly in automated bagging tasks. Video of this work is available at https://youtu.be/6JWjCOeTGiQ.
SViP: Sequencing Bimanual Visuomotor Policies with Object-Centric Motion Primitives
Jun 23, 2025Imitation learning (IL), particularly when leveraging high-dimensional visual inputs for policy training, has proven intuitive and effective in complex bimanual manipulation tasks. Nonetheless, the generalization capability of visuomotor policies remains limited, especially when small demonstration datasets are available. Accumulated errors in visuomotor policies significantly hinder their ability to complete long-horizon tasks. To address these limitations, we propose SViP, a framework that seamlessly integrates visuomotor policies into task and motion planning (TAMP). SViP partitions human demonstrations into bimanual and unimanual operations using a semantic scene graph monitor. Continuous decision variables from the key scene graph are employed to train a switching condition generator. This generator produces parameterized scripted primitives that ensure reliable performance even when encountering out-of-the-distribution observations. Using only 20 real-world demonstrations, we show that SViP enables visuomotor policies to generalize across out-of-distribution initial conditions without requiring object pose estimators. For previously unseen tasks, SViP automatically discovers effective solutions to achieve the goal, leveraging constraint modeling in TAMP formulism. In real-world experiments, SViP outperforms state-of-the-art generative IL methods, indicating wider applicability for more complex tasks. Project website: https://sites.google.com/view/svip-bimanual
Establishing Reliability Metrics for Reward Models in Large Language Models
Apr 21, 2025The reward model (RM) that represents human preferences plays a crucial role in optimizing the outputs of large language models (LLMs), e.g., through reinforcement learning from human feedback (RLHF) or rejection sampling. However, a long challenge for RM is its uncertain reliability, i.e., LLM outputs with higher rewards may not align with actual human preferences. Currently, there is a lack of a convincing metric to quantify the reliability of RMs. To bridge this gap, we propose the \textit{\underline{R}eliable at \underline{$\eta$}} (RETA) metric, which directly measures the reliability of an RM by evaluating the average quality (scored by an oracle) of the top $\eta$ quantile responses assessed by an RM. On top of RETA, we present an integrated benchmarking pipeline that allows anyone to evaluate their own RM without incurring additional Oracle labeling costs. Extensive experimental studies demonstrate the superior stability of RETA metric, providing solid evaluations of the reliability of various publicly available and proprietary RMs. When dealing with an unreliable RM, we can use the RETA metric to identify the optimal quantile from which to select the responses.