 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLC: Communication-Efficient Collaborative Perception with LiDAR Completion
Feb 28, 2026Collaborative perception empowers autonomous agents to share complementary information and overcome perception limitations. While early fusion offers more perceptual complementarity and is inherently robust to model heterogeneity, its high communication cost has limited its practical deployment, prompting most existing works to favor intermediate or late fusion. To address this, we propose a communication-efficient early Collaborative perception framework that incorporates LiDAR Completion to restore scene completeness under sparse transmission, dubbed as CoLC. Specifically, the CoLC integrates three complementary designs. First, each neighbor agent applies Foreground-Aware Point Sampling (FAPS) to selectively transmit informative points that retain essential structural and contextual cues under bandwidth constraints. The ego agent then employs Completion-Enhanced Early Fusion (CEEF) to reconstruct dense pillars from the received sparse inputs and adaptively fuse them with its own observations, thereby restoring spatial completeness. Finally, the Dense-Guided Dual Alignment (DGDA) strategy enforces semantic and geometric consistency between the enhanced and dense pillars during training, ensuring consistent and robust feature learning. Experiments on both simulated and real-world datasets demonstrate that CoLC achieves superior perception-communication trade-offs and remains robust under heterogeneous model settings. The code is available at https://github.com/CatOneTwo/CoLC.
CoDTS: Enhancing Sparsely Supervised Collaborative Perception with a Dual Teacher-Student Framework
Dec 12, 2024



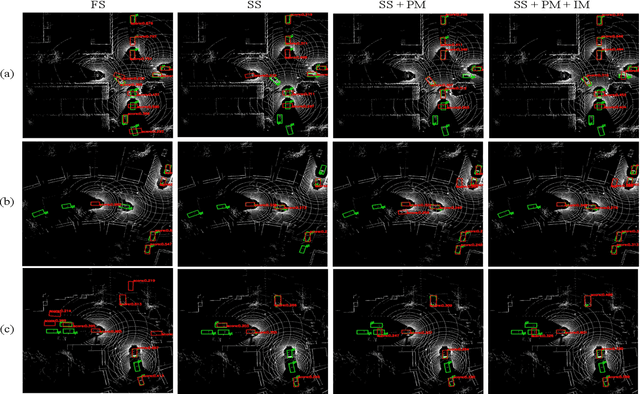
Current collaborative perception methods often rely on fully annotated datasets, which can be expensive to obtain in practical situations. To reduce annotation costs, some works adopt sparsely supervised learning techniques and generate pseudo labels for the missing instances. However, these methods fail to achieve an optimal confidence threshold that harmonizes the quality and quantity of pseudo labels. To address this issue, we propose an end-to-end Collaborative perception Dual Teacher-Student framework (CoDTS), which employs adaptive complementary learning to produce both high-quality and high-quantity pseudo labels. Specifically, the Main Foreground Mining (MFM) module generates high-quality pseudo labels based on the prediction of the static teacher. Subsequently, the Supplement Foreground Mining (SFM) module ensures a balance between the quality and quantity of pseudo labels by adaptively identifying missing instances based on the prediction of the dynamic teacher. Additionally, the Neighbor Anchor Sampling (NAS) module is incorporated to enhance the representation of pseudo labels. To promote the adaptive complementary learning, we implement a staged training strategy that trains the student and dynamic teacher in a mutually beneficial manner. Extensive experiments demonstrate that the CoDTS effectively ensures an optimal balance of pseudo labels in both quality and quantity, establishing a new state-of-the-art in sparsely supervised collaborative perception.
Shallow Signed Distance Functions for Kinematic Collision Bodies
Nov 11, 2024



We present learning-based implicit shape representations designed for real-time avatar collision queries arising in the simulation of clothing. Signed distance functions (SDFs) have been used for such queries for many years due to their computational efficiency. Recently deep neural networks have been used for implicit shape representations (DeepSDFs) due to their ability to represent multiple shapes with modest memory requirements compared to traditional representations over dense grids. However, the computational expense of DeepSDFs prevents their use in real-time clothing simulation applications. We design a learning-based representation of SDFs for human avatars whoes bodies change shape kinematically due to joint-based skinning. Rather than using a single DeepSDF for the entire avatar, we use a collection of extremely computationally efficient (shallow) neural networks that represent localized deformations arising from changes in body shape induced by the variation of a single joint. This requires a stitching process to combine each shallow SDF in the collection together into one SDF representing the signed closest distance to the boundary of the entire body. To achieve this we augment each shallow SDF with an additional output that resolves whether or not the individual shallow SDF value is referring to a closest point on the boundary of the body, or to a point on the interior of the body (but on the boundary of the individual shallow SDF). Our model is extremely fast and accurate and we demonstrate its applicability with real-time simulation of garments driven by animated characters.
ACTrack: Adding Spatio-Temporal Condition for Visual Object Tracking
Feb 27, 2024Efficiently modeling spatio-temporal relations of objects is a key challenge in visual object tracking (VOT). Existing methods track by appearance-based similarity or long-term relation modeling, resulting in rich temporal contexts between consecutive frames being easily overlooked. Moreover, training trackers from scratch or fine-tuning large pre-trained models needs more time and memory consumption. In this paper, we present ACTrack, a new tracking framework with additive spatio-temporal conditions. It preserves the quality and capabilities of the pre-trained Transformer backbone by freezing its parameters, and makes a trainable lightweight additive net to model spatio-temporal relations in tracking. We design an additive siamese convolutional network to ensure the integrity of spatial features and perform temporal sequence modeling to simplify the tracking pipeline. Experimental results on several benchmarks prove that ACTrack could balance training efficiency and tracking performance.
SSC3OD: Sparsely Supervised Collaborative 3D Object Detection from LiDAR Point Clouds
Jul 03, 2023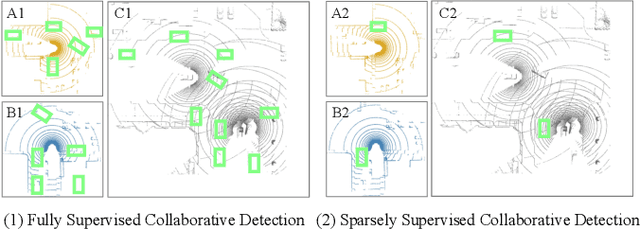


Collaborative 3D object detection, with its improved interaction advantage among multiple agents, has been widely explored in autonomous driving. However, existing collaborative 3D object detectors in a fully supervised paradigm heavily rely on large-scale annotated 3D bounding boxes, which is labor-intensive and time-consuming. To tackle this issue, we propose a sparsely supervised collaborative 3D object detection framework SSC3OD, which only requires each agent to randomly label one object in the scene. Specifically, this model consists of two novel components, i.e., the pillar-based masked autoencoder (Pillar-MAE) and the instance mining module. The Pillar-MAE module aims to reason over high-level semantics in a self-supervised manner, and the instance mining module generates high-quality pseudo labels for collaborative detectors online. By introducing these simple yet effective mechanisms, the proposed SSC3OD can alleviate the adverse impacts of incomplete annotations. We generate sparse labels based on collaborative perception datasets to evaluate our method. Extensive experiments on three large-scale datasets reveal that our proposed SSC3OD can effectively improve the performance of sparsely supervised collaborative 3D object detectors.
Collaborative Perception in Autonomous Driving: Methods, Datasets and Challenges
Jan 16, 2023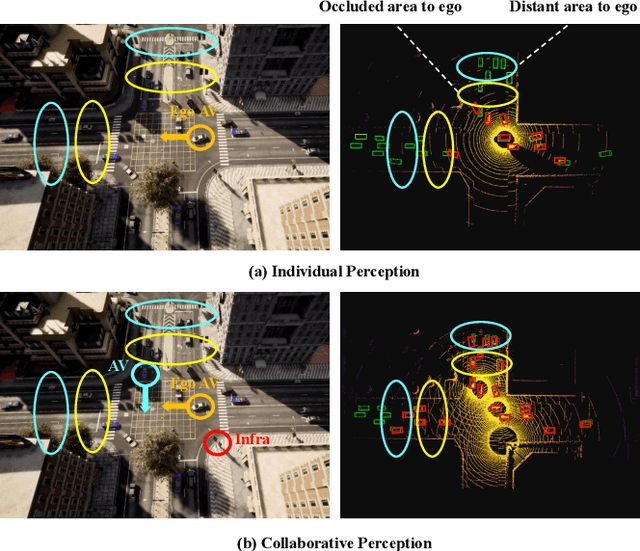
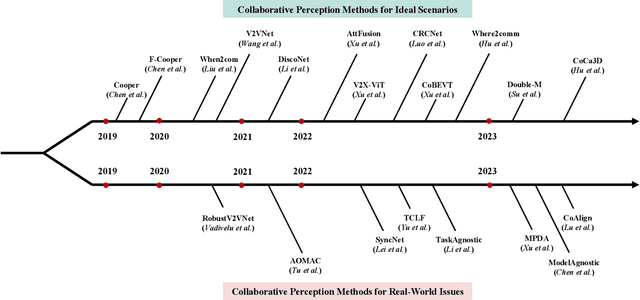
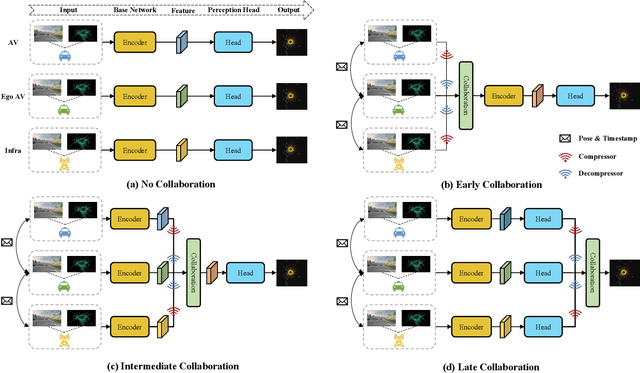
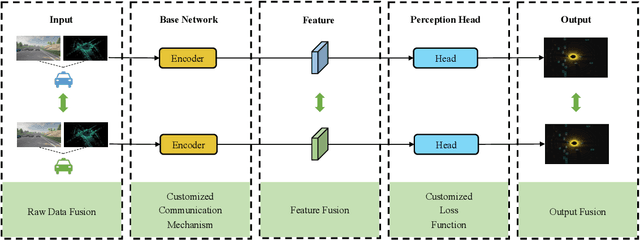
Collaborative perception is essential to address occlusion and sensor failure issues in autonomous driving. In recent years, deep learning on collaborative perception has become even thriving, with numerous methods have been proposed. Although some works have reviewed and analyzed the basic architecture and key components in this field, there is still a lack of reviews on systematical collaboration modules in perception networks and large-scale collaborative perception datasets. The primary goal of this work is to address the abovementioned issues and provide a comprehensive review of recent achievements in this field. First, we introduce fundamental technologies and collaboration schemes. Following that, we provide an overview of practical collaborative perception methods and systematically summarize the collaboration modules in networks to improve collaboration efficiency and performance while also ensuring collaboration robustness and safety. Then, we present large-scale public datasets and summarize quantitative results on these benchmarks. Finally, we discuss the remaining challenges and promising future research directions.
Analytically Integratable Zero-restlength Springs for Capturing Dynamic Modes unrepresented by Quasistatic Neural Networks
Jan 25, 2022
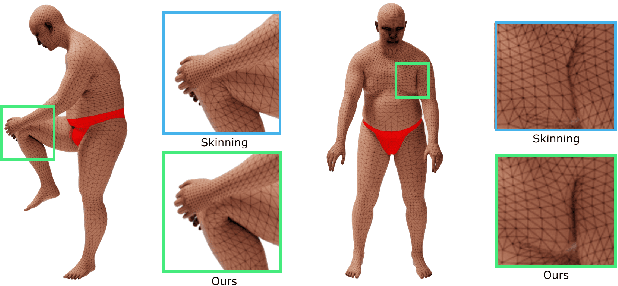
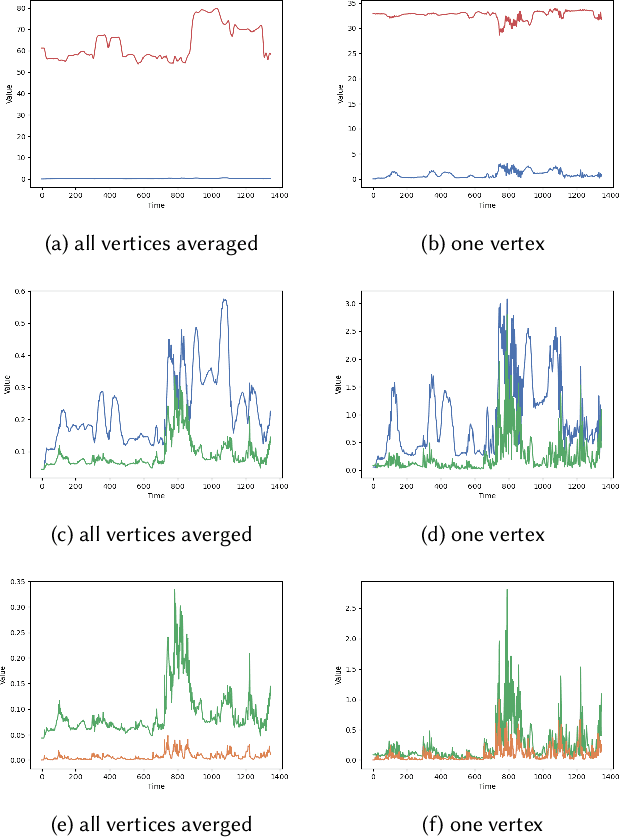
We present a novel paradigm for modeling certain types of dynamic simulation in real-time with the aid of neural networks. In order to significantly reduce the requirements on data (especially time-dependent data), as well as decrease generalization error, our approach utilizes a data-driven neural network only to capture quasistatic information (instead of dynamic or time-dependent information). Subsequently, we augment our quasistatic neural network (QNN) inference with a (real-time) dynamic simulation layer. Our key insight is that the dynamic modes lost when using a QNN approximation can be captured with a quite simple (and decoupled) zero-restlength spring model, which can be integrated analytically (as opposed to numerically) and thus has no time-step stability restrictions. Additionally, we demonstrate that the spring constitutive parameters can be robustly learned from a surprisingly small amount of dynamic simulation data. Although we illustrate the efficacy of our approach by considering soft-tissue dynamics on animated human bodies, the paradigm is extensible to many different simulation frameworks.