 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalytically Integratable Zero-restlength Springs for Capturing Dynamic Modes unrepresented by Quasistatic Neural Networks
Jan 25, 2022
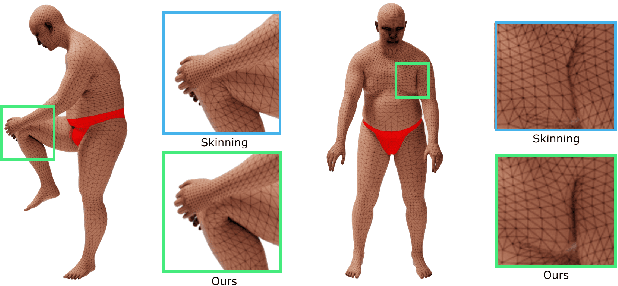
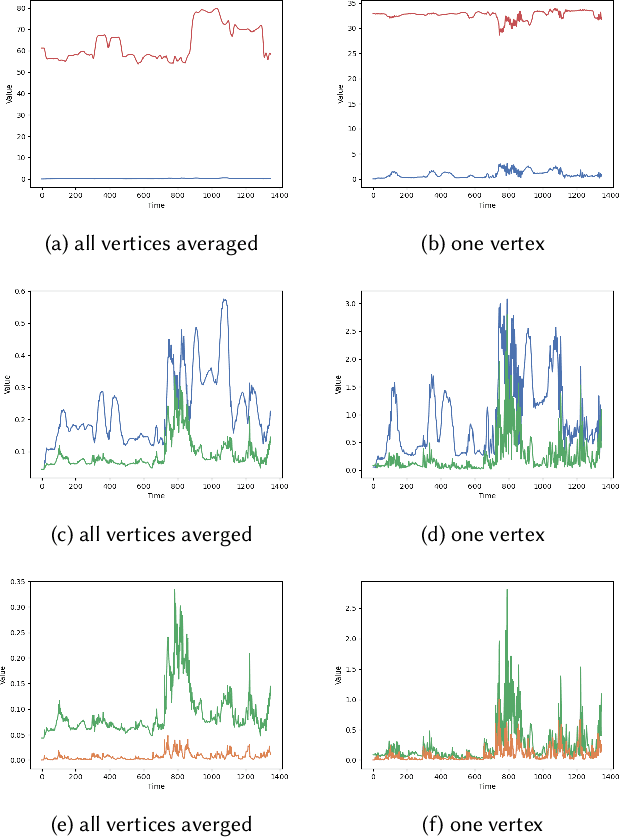
We present a novel paradigm for modeling certain types of dynamic simulation in real-time with the aid of neural networks. In order to significantly reduce the requirements on data (especially time-dependent data), as well as decrease generalization error, our approach utilizes a data-driven neural network only to capture quasistatic information (instead of dynamic or time-dependent information). Subsequently, we augment our quasistatic neural network (QNN) inference with a (real-time) dynamic simulation layer. Our key insight is that the dynamic modes lost when using a QNN approximation can be captured with a quite simple (and decoupled) zero-restlength spring model, which can be integrated analytically (as opposed to numerically) and thus has no time-step stability restrictions. Additionally, we demonstrate that the spring constitutive parameters can be robustly learned from a surprisingly small amount of dynamic simulation data. Although we illustrate the efficacy of our approach by considering soft-tissue dynamics on animated human bodies, the paradigm is extensible to many different simulation frameworks.
Skinning a Parameterization of Three-Dimensional Space for Neural Network Cloth
Jun 08, 2020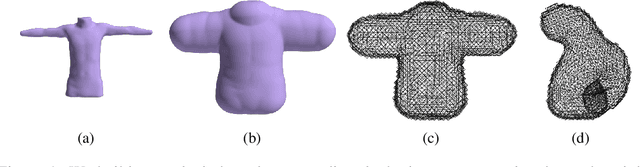

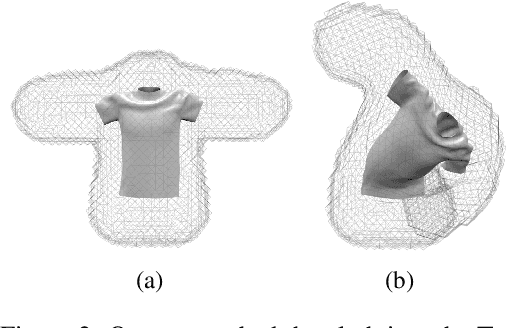
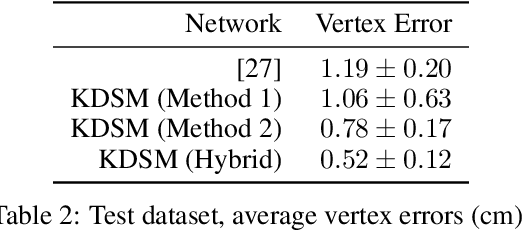
We present a novel learning framework for cloth deformation by embedding virtual cloth into a tetrahedral mesh that parametrizes the volumetric region of air surrounding the underlying body. In order to maintain this volumetric parameterization during character animation, the tetrahedral mesh is constrained to follow the body surface as it deforms. We embed the cloth mesh vertices into this parameterization of three-dimensional space in order to automatically capture much of the nonlinear deformation due to both joint rotations and collisions. We then train a convolutional neural network to recover ground truth deformation by learning cloth embedding offsets for each skeletal pose. Our experiments show significant improvement over learning cloth offsets from body surface parameterizations, both quantitatively and visually, with prior state of the art having a mean error five standard deviations higher than ours. Moreover, our results demonstrate the efficacy of a general learning paradigm where high-frequency details can be embedded into low-frequency parameterizations.
Recovering Geometric Information with Learned Texture Perturbations
Jan 20, 2020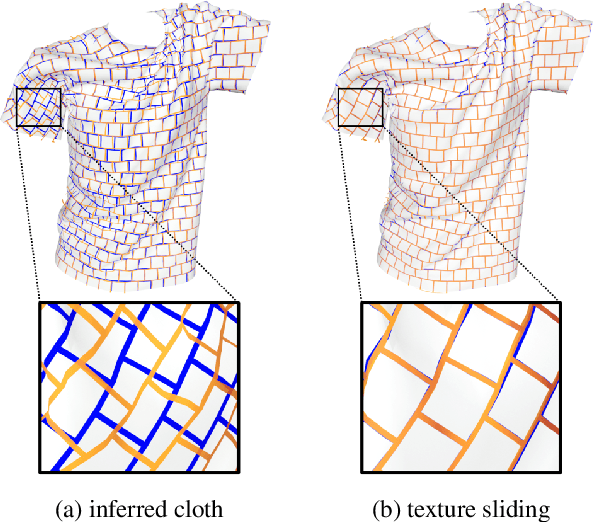
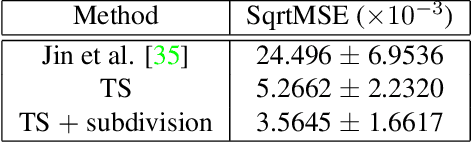
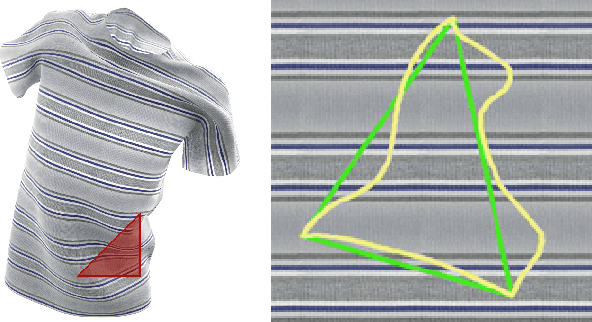

Regularization is used to avoid overfitting when training a neural network; unfortunately, this reduces the attainable level of detail hindering the ability to capture high-frequency information present in the training data. Even though various approaches may be used to re-introduce high-frequency detail, it typically does not match the training data and is often not time coherent. In the case of network inferred cloth, these sentiments manifest themselves via either a lack of detailed wrinkles or unnaturally appearing and/or time incoherent surrogate wrinkles. Thus, we propose a general strategy whereby high-frequency information is procedurally embedded into low-frequency data so that when the latter is smeared out by the network the former still retains its high-frequency detail. We illustrate this approach by learning texture coordinates which when smeared do not in turn smear out the high-frequency detail in the texture itself but merely smoothly distort it. Notably, we prescribe perturbed texture coordinates that are subsequently used to correct the over-smoothed appearance of inferred cloth, and correcting the appearance from multiple camera views naturally recovers lost geometric information.
Coercing Machine Learning to Output Physically Accurate Results
Nov 23, 2019

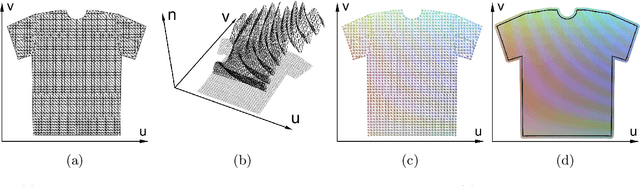

Many machine/deep learning artificial neural networks are trained to simply be interpolation functions that map input variables to output values interpolated from the training data in a linear/nonlinear fashion. Even when the input/output pairs of the training data are physically accurate (e.g. the results of an experiment or numerical simulation), interpolated quantities can deviate quite far from being physically accurate. Although one could project the output of a network into a physically feasible region, such a postprocess is not captured by the energy function minimized when training the network; thus, the final projected result could incorrectly deviate quite far from the training data. We propose folding any such projection or postprocess directly into the network so that the final result is correctly compared to the training data by the energy function. Although we propose a general approach, we illustrate its efficacy on a specific convolutional neural network that takes in human pose parameters (joint rotations) and outputs a prediction of vertex positions representing a triangulated cloth mesh. While the original network outputs vertex positions with erroneously high stretching and compression energies, the new network trained with our physics prior remedies these issues producing highly improved results.
3D Guided Fine-Grained Face Manipulation
Feb 24, 2019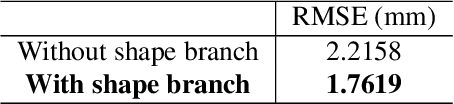
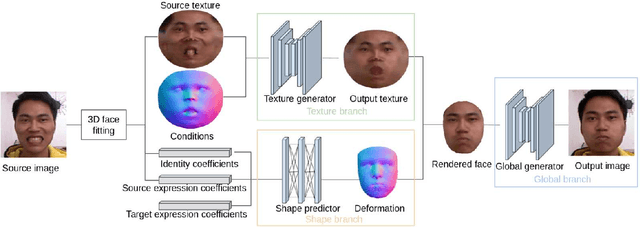
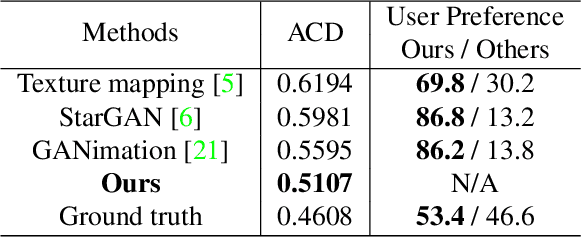

We present a method for fine-grained face manipulation. Given a face image with an arbitrary expression, our method can synthesize another arbitrary expression by the same person. This is achieved by first fitting a 3D face model and then disentangling the face into a texture and a shape. We then learn different networks in these two spaces. In the texture space, we use a conditional generative network to change the appearance, and carefully design input formats and loss functions to achieve the best results. In the shape space, we use a fully connected network to predict the accurate shapes and use the available depth data for supervision. Both networks are conditioned on expression coefficients rather than discrete labels, allowing us to generate an unlimited amount of expressions. We show the superiority of this disentangling approach through both quantitative and qualitative studies. In a user study, our method is preferred in 85% of cases when compared to the most recent work. When compared to the ground truth, annotators cannot reliably distinguish between our synthesized images and real images, preferring our method in 53% of the cases.
A Pixel-Based Framework for Data-Driven Clothing
Dec 03, 2018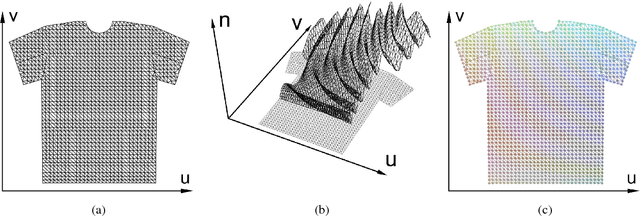
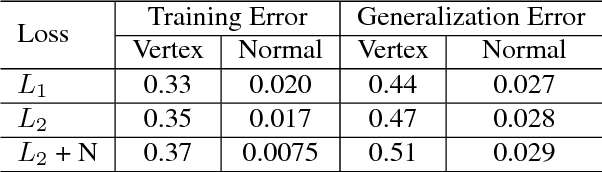
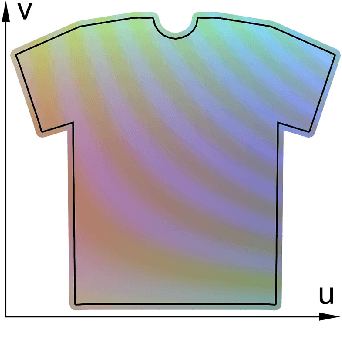
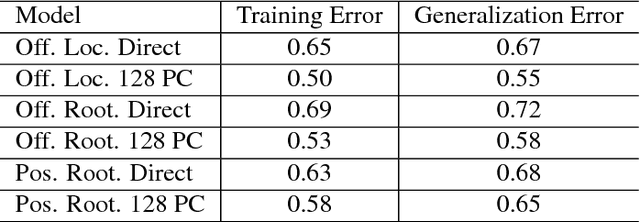
With the aim of creating virtual cloth deformations more similar to real world clothing, we propose a new computational framework that recasts three dimensional cloth deformation as an RGB image in a two dimensional pattern space. Then a three dimensional animation of cloth is equivalent to a sequence of two dimensional RGB images, which in turn are driven/choreographed via animation parameters such as joint angles. This allows us to leverage popular CNNs to learn cloth deformations in image space. The two dimensional cloth pixels are extended into the real world via standard body skinning techniques, after which the RGB values are interpreted as texture offsets and displacement maps. Notably, we illustrate that our approach does not require accurate unclothed body shapes or robust skinning techniques. Additionally, we discuss how standard image based techniques such as image partitioning for higher resolution, GANs for merging partitioned image regions back together, etc., can readily be incorporated into our framework.