 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Coercing Machine Learning to Output Physically Accurate Results
Nov 23, 2019

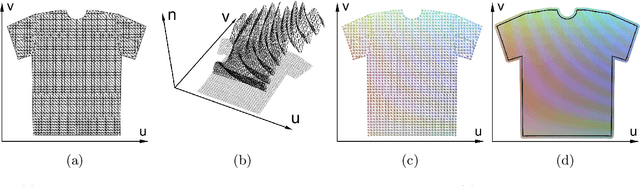

Many machine/deep learning artificial neural networks are trained to simply be interpolation functions that map input variables to output values interpolated from the training data in a linear/nonlinear fashion. Even when the input/output pairs of the training data are physically accurate (e.g. the results of an experiment or numerical simulation), interpolated quantities can deviate quite far from being physically accurate. Although one could project the output of a network into a physically feasible region, such a postprocess is not captured by the energy function minimized when training the network; thus, the final projected result could incorrectly deviate quite far from the training data. We propose folding any such projection or postprocess directly into the network so that the final result is correctly compared to the training data by the energy function. Although we propose a general approach, we illustrate its efficacy on a specific convolutional neural network that takes in human pose parameters (joint rotations) and outputs a prediction of vertex positions representing a triangulated cloth mesh. While the original network outputs vertex positions with erroneously high stretching and compression energies, the new network trained with our physics prior remedies these issues producing highly improved results.