 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharting Empirical Laws for LLM Fine-Tuning in Scientific Multi-Discipline Learning
Feb 11, 2026While large language models (LLMs) have achieved strong performance through fine-tuning within individual scientific domains, their learning dynamics in multi-disciplinary contexts remains poorly understood, despite the promise of improved generalization and broader applicability through cross-domain knowledge synergy. In this work, we present the first systematic study of multi-disciplinary LLM fine-tuning, constructing a five-discipline corpus and analyzing learning patterns of full fine-tuning, LoRA, LoRA-MoE, and LoRA compositions. Particularly, our study shows that multi-disciplinary learning is substantially more variable than single-discipline training and distills four consistent empirical laws: (1) Balance-then-Diversity: low-resource disciplines degrade performance unless mitigated via diversity-aware upsampling; (2) Merge-then-Align: restoring instruction-following ability is critical for cross-discipline synergy; (3) Optimize-then-Scale: parameter scaling offers limited gains without prior design optimization; and (4) Share-then-Specialize: asymmetric LoRA-MoE yields robust gains with minimal trainable parameters via shared low-rank projection. Together, these laws form a practical recipe for principled multi-discipline fine-tuning and provide actionable guidance for developing generalizable scientific LLMs.
Democratizing the Creation of Animatable Facial Avatars
Jan 29, 2024In high-end visual effects pipelines, a customized (and expensive) light stage system is (typically) used to scan an actor in order to acquire both geometry and texture for various expressions. Aiming towards democratization, we propose a novel pipeline for obtaining geometry and texture as well as enough expression information to build a customized person-specific animation rig without using a light stage or any other high-end hardware (or manual cleanup). A key novel idea consists of warping real-world images to align with the geometry of a template avatar and subsequently projecting the warped image into the template avatar's texture; importantly, this allows us to leverage baked-in real-world lighting/texture information in order to create surrogate facial features (and bridge the domain gap) for the sake of geometry reconstruction. Not only can our method be used to obtain a neutral expression geometry and de-lit texture, but it can also be used to improve avatars after they have been imported into an animation system (noting that such imports tend to be lossy, while also hallucinating various features). Since a default animation rig will contain template expressions that do not correctly correspond to those of a particular individual, we use a Simon Says approach to capture various expressions and build a person-specific animation rig (that moves like they do). Our aforementioned warping/projection method has high enough efficacy to reconstruct geometry corresponding to each expressions.
Leveraging Deepfakes to Close the Domain Gap between Real and Synthetic Images in Facial Capture Pipelines
Apr 27, 2022



We propose an end-to-end pipeline for both building and tracking 3D facial models from personalized in-the-wild (cellphone, webcam, youtube clips, etc.) video data. First, we present a method for automatic data curation and retrieval based on a hierarchical clustering framework typical of collision detection algorithms in traditional computer graphics pipelines. Subsequently, we utilize synthetic turntables and leverage deepfake technology in order to build a synthetic multi-view stereo pipeline for appearance capture that is robust to imperfect synthetic geometry and image misalignment. The resulting model is fit with an animation rig, which is then used to track facial performances. Notably, our novel use of deepfake technology enables us to perform robust tracking of in-the-wild data using differentiable renderers despite a significant synthetic-to-real domain gap. Finally, we outline how we train a motion capture regressor, leveraging the aforementioned techniques to avoid the need for real-world ground truth data and/or a high-end calibrated camera capture setup.
Learning Topological Motion Primitives for Knot Planning
Sep 05, 2020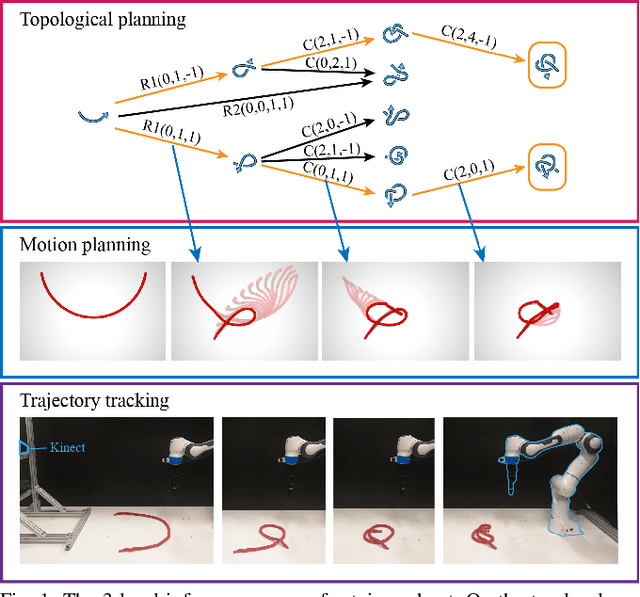
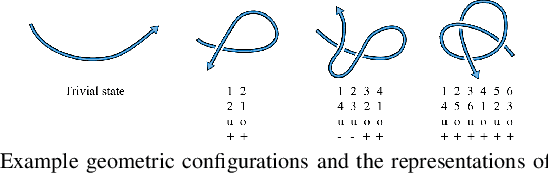
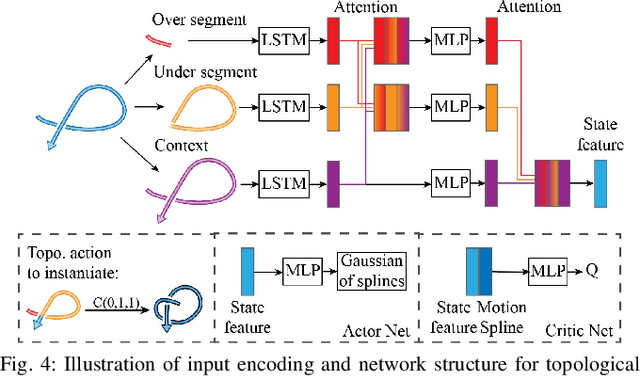
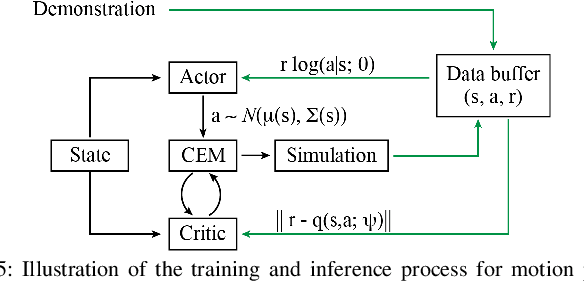
In this paper, we approach the challenging problem of motion planning for knot tying. We propose a hierarchical approach in which the top layer produces a topological plan and the bottom layer translates this plan into continuous robot motion. The top layer decomposes a knotting task into sequences of abstract topological actions based on knot theory. The bottom layer translates each of these abstract actions into robot motion trajectories through learned topological motion primitives. To adapt each topological action to the specific rope geometry, the motion primitives take the observed rope configuration as input. We train the motion primitives by imitating human demonstrations and reinforcement learning in simulation. To generalize human demonstrations of simple knots into more complex knots, we observe similarities in the motion strategies of different topological actions and design the neural network structure to exploit such similarities. We demonstrate that our learned motion primitives can be used to efficiently generate motion plans for tying the overhand knot. The motion plan can then be executed on a real robot using visual tracking and Model Predictive Control. We also demonstrate that our learned motion primitives can be composed to tie a more complex pentagram-like knot despite being only trained on human demonstrations of simpler knots.
Self-Supervised Learning of State Estimation for Manipulating Deformable Linear Objects
Nov 14, 2019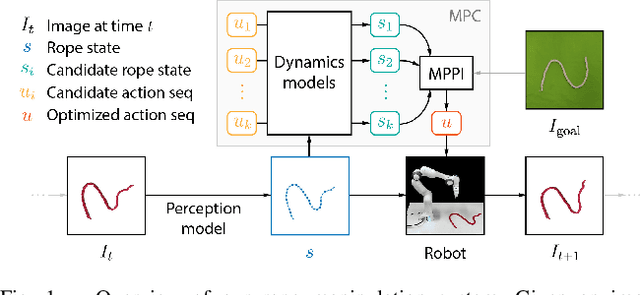
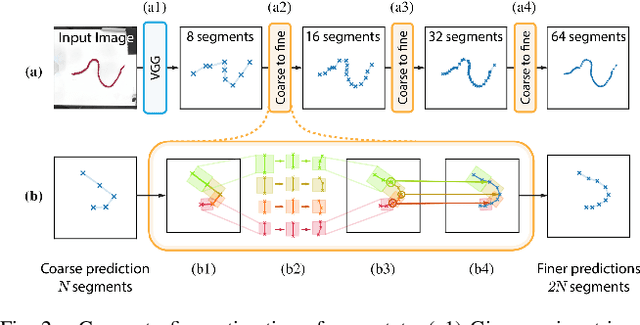
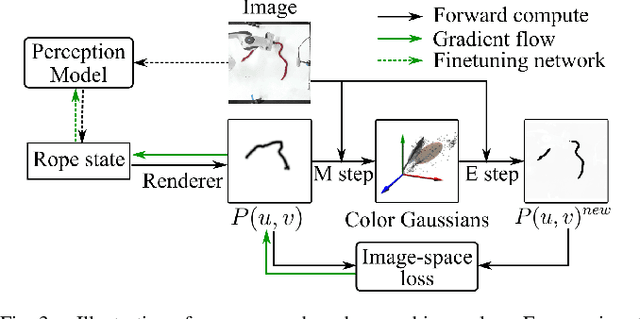
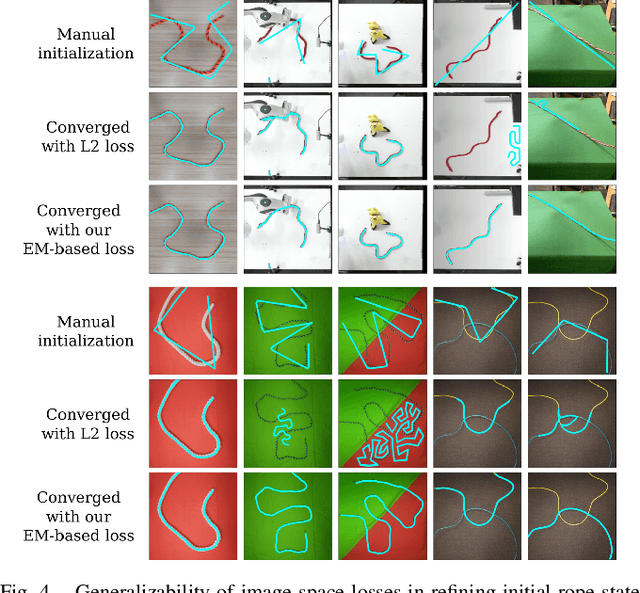
We demonstrate model-based, visual robot manipulation of linear deformable objects. Our approach is based on a state-space representation of the physical system that the robot aims to control. This choice has multiple advantages, including the ease of incorporating physical priors in the dynamics model and perception model, and the ease of planning manipulation actions. In addition, physical states can naturally represent object instances of different appearances. Therefore, dynamics in the state space can be learned in one setting and directly used in other visually different settings. This is in contrast to dynamics learned in pixel space or latent space, where generalization to visual differences are not guaranteed. Challenges in taking the state-space approach are the estimation of the high-dimensional state of a deformable object from raw images, where annotations are very expensive on real data, and finding a dynamics model that is both accurate, generalizable, and efficient to compute. We are the first to demonstrate self-supervised training of rope state estimation on real images, without requiring expensive annotations. This is achieved by our novel differentiable renderer and image loss, which are generalizable across a wide range of visual appearances. With estimated rope states, we train a fast and differentiable neural network dynamics model that encodes the physics of mass-spring systems. Our method has a higher accuracy in predicting future states compared to models that do not involve explicit state estimation and do not use any physics prior. We also show that our approach achieves more efficient manipulation, both in simulation and on a real robot, when used within a model predictive controller.
Three Dimensional Reconstruction of Botanical Trees with Simulatable Geometry
Dec 20, 2018



We tackle the challenging problem of creating full and accurate three dimensional reconstructions of botanical trees with the topological and geometric accuracy required for subsequent physical simulation, e.g. in response to wind forces. Although certain aspects of our approach would benefit from various improvements, our results exceed the state of the art especially in geometric and topological complexity and accuracy. Starting with two dimensional RGB image data acquired from cameras attached to drones, we create point clouds, textured triangle meshes, and a simulatable and skinned cylindrical articulated rigid body model. We discuss the pros and cons of each step of our pipeline, and in order to stimulate future research we make the raw and processed data from every step of the pipeline as well as the final geometric reconstructions publicly available.
A Pixel-Based Framework for Data-Driven Clothing
Dec 03, 2018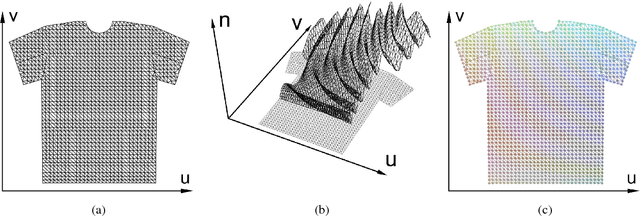
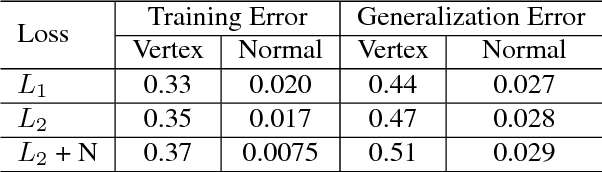
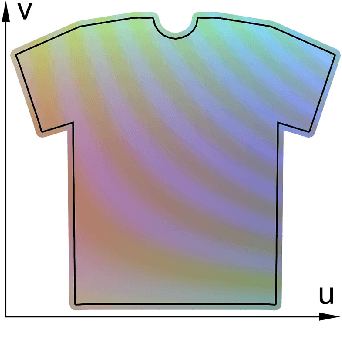
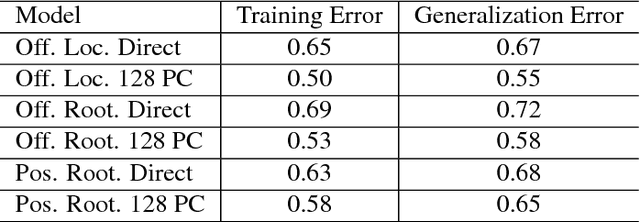
With the aim of creating virtual cloth deformations more similar to real world clothing, we propose a new computational framework that recasts three dimensional cloth deformation as an RGB image in a two dimensional pattern space. Then a three dimensional animation of cloth is equivalent to a sequence of two dimensional RGB images, which in turn are driven/choreographed via animation parameters such as joint angles. This allows us to leverage popular CNNs to learn cloth deformations in image space. The two dimensional cloth pixels are extended into the real world via standard body skinning techniques, after which the RGB values are interpreted as texture offsets and displacement maps. Notably, we illustrate that our approach does not require accurate unclothed body shapes or robust skinning techniques. Additionally, we discuss how standard image based techniques such as image partitioning for higher resolution, GANs for merging partitioned image regions back together, etc., can readily be incorporated into our framework.