 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Gaussian Splats to Create High-Fidelity Facial Geometry and Texture
Dec 18, 2025



We leverage increasingly popular three-dimensional neural representations in order to construct a unified and consistent explanation of a collection of uncalibrated images of the human face. Our approach utilizes Gaussian Splatting, since it is more explicit and thus more amenable to constraints than NeRFs. We leverage segmentation annotations to align the semantic regions of the face, facilitating the reconstruction of a neutral pose from only 11 images (as opposed to requiring a long video). We soft constrain the Gaussians to an underlying triangulated surface in order to provide a more structured Gaussian Splat reconstruction, which in turn informs subsequent perturbations to increase the accuracy of the underlying triangulated surface. The resulting triangulated surface can then be used in a standard graphics pipeline. In addition, and perhaps most impactful, we show how accurate geometry enables the Gaussian Splats to be transformed into texture space where they can be treated as a view-dependent neural texture. This allows one to use high visual fidelity Gaussian Splatting on any asset in a scene without the need to modify any other asset or any other aspect (geometry, lighting, renderer, etc.) of the graphics pipeline. We utilize a relightable Gaussian model to disentangle texture from lighting in order to obtain a delit high-resolution albedo texture that is also readily usable in a standard graphics pipeline. The flexibility of our system allows for training with disparate images, even with incompatible lighting, facilitating robust regularization. Finally, we demonstrate the efficacy of our approach by illustrating its use in a text-driven asset creation pipeline.
View-Consistent Hierarchical 3D SegmentationUsing Ultrametric Feature Fields
May 30, 2024Large-scale vision foundation models such as Segment Anything (SAM) demonstrate impressive performance in zero-shot image segmentation at multiple levels of granularity. However, these zero-shot predictions are rarely 3D-consistent. As the camera viewpoint changes in a scene, so do the segmentation predictions, as well as the characterizations of ``coarse" or ``fine" granularity. In this work, we address the challenging task of lifting multi-granular and view-inconsistent image segmentations into a hierarchical and 3D-consistent representation. We learn a novel feature field within a Neural Radiance Field (NeRF) representing a 3D scene, whose segmentation structure can be revealed at different scales by simply using different thresholds on feature distance. Our key idea is to learn an ultrametric feature space, which unlike a Euclidean space, exhibits transitivity in distance-based grouping, naturally leading to a hierarchical clustering. Put together, our method takes view-inconsistent multi-granularity 2D segmentations as input and produces a hierarchy of 3D-consistent segmentations as output. We evaluate our method and several baselines on synthetic datasets with multi-view images and multi-granular segmentation, showcasing improved accuracy and viewpoint-consistency. We additionally provide qualitative examples of our model's 3D hierarchical segmentations in real world scenes.\footnote{The code and dataset are available at:
Democratizing the Creation of Animatable Facial Avatars
Jan 29, 2024In high-end visual effects pipelines, a customized (and expensive) light stage system is (typically) used to scan an actor in order to acquire both geometry and texture for various expressions. Aiming towards democratization, we propose a novel pipeline for obtaining geometry and texture as well as enough expression information to build a customized person-specific animation rig without using a light stage or any other high-end hardware (or manual cleanup). A key novel idea consists of warping real-world images to align with the geometry of a template avatar and subsequently projecting the warped image into the template avatar's texture; importantly, this allows us to leverage baked-in real-world lighting/texture information in order to create surrogate facial features (and bridge the domain gap) for the sake of geometry reconstruction. Not only can our method be used to obtain a neutral expression geometry and de-lit texture, but it can also be used to improve avatars after they have been imported into an animation system (noting that such imports tend to be lossy, while also hallucinating various features). Since a default animation rig will contain template expressions that do not correctly correspond to those of a particular individual, we use a Simon Says approach to capture various expressions and build a person-specific animation rig (that moves like they do). Our aforementioned warping/projection method has high enough efficacy to reconstruct geometry corresponding to each expressions.
DETRs with Hybrid Matching
Jul 26, 2022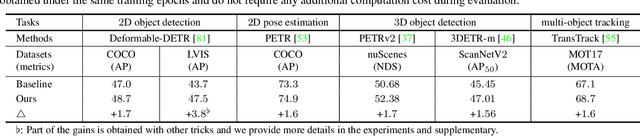
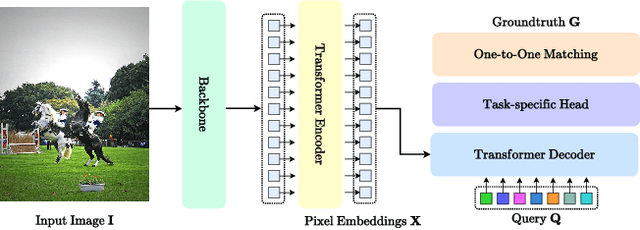

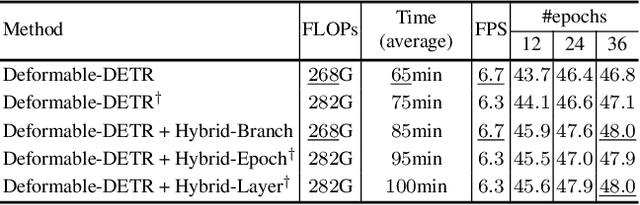
One-to-one set matching is a key design for DETR to establish its end-to-end capability, so that object detection does not require a hand-crafted NMS (non-maximum suppression) method to remove duplicate detections. This end-to-end signature is important for the versatility of DETR, and it has been generalized to a wide range of visual problems, including instance/semantic segmentation, human pose estimation, and point cloud/multi-view-images based detection, etc. However, we note that because there are too few queries assigned as positive samples, the one-to-one set matching significantly reduces the training efficiency of positive samples. This paper proposes a simple yet effective method based on a hybrid matching scheme that combines the original one-to-one matching branch with auxiliary queries that use one-to-many matching loss during training. This hybrid strategy has been shown to significantly improve training efficiency and improve accuracy. In inference, only the original one-to-one match branch is used, thus maintaining the end-to-end merit and the same inference efficiency of DETR. The method is named $\mathcal{H}$-DETR, and it shows that a wide range of representative DETR methods can be consistently improved across a wide range of visual tasks, including Deformable-DETR, 3DETR/PETRv2, PETR, and TransTrack, among others. Code will be available at: https://github.com/HDETR
MLSeg: Image and Video Segmentation as Multi-Label Classification and Selected-Label Pixel Classification
Mar 08, 2022

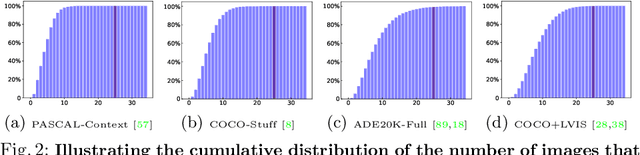
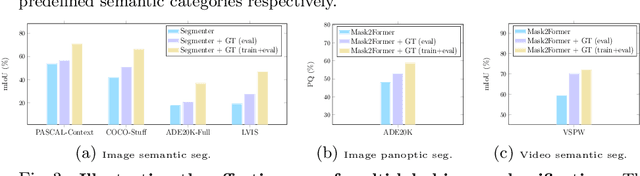
For a long period of time, research studies on segmentation have typically formulated the task as pixel classification that predicts a class for each pixel from a set of predefined, fixed number of semantic categories. Yet standard architectures following this formulation will inevitably encounter various challenges under more realistic settings where the total number of semantic categories scales up (e.g., beyond $1\rm{k}$ classes). On the other hand, a standard image or video usually contains only a small number of semantic categories from the entire label set. Motivated by this intuition, in this paper, we propose to decompose segmentation into two sub-problems: (i) image-level or video-level multi-label classification and (ii) pixel-level selected-label classification. Given an input image or video, our framework first conducts multi-label classification over the large complete label set and selects a small set of labels according to the class confidence scores. Then the follow-up pixel-wise classification is only performed among the selected subset of labels. Our approach is conceptually general and can be applied to various existing segmentation frameworks by simply adding a lightweight multi-label classification branch. We demonstrate the effectiveness of our framework with competitive experimental results across four tasks including image semantic segmentation, image panoptic segmentation, video instance segmentation, and video semantic segmentation. Especially, with our MLSeg, Mask$2$Former gains +$0.8\%$/+$0.7\%$/+$0.7\%$ on ADE$20$K panoptic segmentation/YouTubeVIS $2019$ video instance segmentation/VSPW video semantic segmentation benchmarks respectively. Code will be available at:https://github.com/openseg-group/MLSeg