 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
TEXTS-Diff: TEXTS-Aware Diffusion Model for Real-World Text Image Super-Resolution
Jan 24, 2026Real-world text image super-resolution aims to restore overall visual quality and text legibility in images suffering from diverse degradations and text distortions. However, the scarcity of text image data in existing datasets results in poor performance on text regions. In addition, datasets consisting of isolated text samples limit the quality of background reconstruction. To address these limitations, we construct Real-Texts, a large-scale, high-quality dataset collected from real-world images, which covers diverse scenarios and contains natural text instances in both Chinese and English. Additionally, we propose the TEXTS-Aware Diffusion Model (TEXTS-Diff) to achieve high-quality generation in both background and textual regions. This approach leverages abstract concepts to improve the understanding of textual elements within visual scenes and concrete text regions to enhance textual details. It mitigates distortions and hallucination artifacts commonly observed in text regions, while preserving high-quality visual scene fidelity. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple evaluation metrics, exhibiting superior generalization ability and text restoration accuracy in complex scenarios. All the code, model, and dataset will be released.
Real-world Reinforcement Learning from Suboptimal Interventions
Dec 30, 2025Real-world reinforcement learning (RL) offers a promising approach to training precise and dexterous robotic manipulation policies in an online manner, enabling robots to learn from their own experience while gradually reducing human labor. However, prior real-world RL methods often assume that human interventions are optimal across the entire state space, overlooking the fact that even expert operators cannot consistently provide optimal actions in all states or completely avoid mistakes. Indiscriminately mixing intervention data with robot-collected data inherits the sample inefficiency of RL, while purely imitating intervention data can ultimately degrade the final performance achievable by RL. The question of how to leverage potentially suboptimal and noisy human interventions to accelerate learning without being constrained by them thus remains open. To address this challenge, we propose SiLRI, a state-wise Lagrangian reinforcement learning algorithm for real-world robot manipulation tasks. Specifically, we formulate the online manipulation problem as a constrained RL optimization, where the constraint bound at each state is determined by the uncertainty of human interventions. We then introduce a state-wise Lagrange multiplier and solve the problem via a min-max optimization, jointly optimizing the policy and the Lagrange multiplier to reach a saddle point. Built upon a human-as-copilot teleoperation system, our algorithm is evaluated through real-world experiments on diverse manipulation tasks. Experimental results show that SiLRI effectively exploits human suboptimal interventions, reducing the time required to reach a 90% success rate by at least 50% compared with the state-of-the-art RL method HIL-SERL, and achieving a 100% success rate on long-horizon manipulation tasks where other RL methods struggle to succeed. Project website: https://silri-rl.github.io/.
Semantic Context Matters: Improving Conditioning for Autoregressive Models
Nov 18, 2025Recently, autoregressive (AR) models have shown strong potential in image generation, offering better scalability and easier integration with unified multi-modal systems compared to diffusion-based methods. However, extending AR models to general image editing remains challenging due to weak and inefficient conditioning, often leading to poor instruction adherence and visual artifacts. To address this, we propose SCAR, a Semantic-Context-driven method for Autoregressive models. SCAR introduces two key components: Compressed Semantic Prefilling, which encodes high-level semantics into a compact and efficient prefix, and Semantic Alignment Guidance, which aligns the last visual hidden states with target semantics during autoregressive decoding to enhance instruction fidelity. Unlike decoding-stage injection methods, SCAR builds upon the flexibility and generality of vector-quantized-based prefilling while overcoming its semantic limitations and high cost. It generalizes across both next-token and next-set AR paradigms with minimal architectural changes. SCAR achieves superior visual fidelity and semantic alignment on both instruction editing and controllable generation benchmarks, outperforming prior AR-based methods while maintaining controllability. All code will be released.
From Editor to Dense Geometry Estimator
Sep 04, 2025
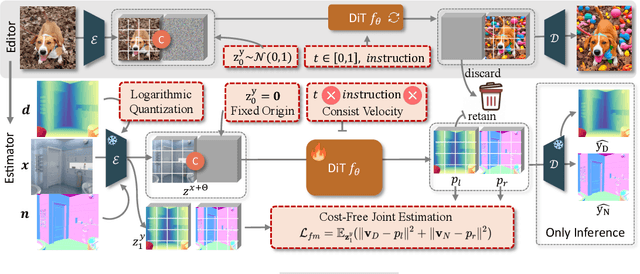


Leveraging visual priors from pre-trained text-to-image (T2I) generative models has shown success in dense prediction. However, dense prediction is inherently an image-to-image task, suggesting that image editing models, rather than T2I generative models, may be a more suitable foundation for fine-tuning. Motivated by this, we conduct a systematic analysis of the fine-tuning behaviors of both editors and generators for dense geometry estimation. Our findings show that editing models possess inherent structural priors, which enable them to converge more stably by ``refining" their innate features, and ultimately achieve higher performance than their generative counterparts. Based on these findings, we introduce \textbf{FE2E}, a framework that pioneeringly adapts an advanced editing model based on Diffusion Transformer (DiT) architecture for dense geometry prediction. Specifically, to tailor the editor for this deterministic task, we reformulate the editor's original flow matching loss into the ``consistent velocity" training objective. And we use logarithmic quantization to resolve the precision conflict between the editor's native BFloat16 format and the high precision demand of our tasks. Additionally, we leverage the DiT's global attention for a cost-free joint estimation of depth and normals in a single forward pass, enabling their supervisory signals to mutually enhance each other. Without scaling up the training data, FE2E achieves impressive performance improvements in zero-shot monocular depth and normal estimation across multiple datasets. Notably, it achieves over 35\% performance gains on the ETH3D dataset and outperforms the DepthAnything series, which is trained on 100$\times$ data. The project page can be accessed \href{https://amap-ml.github.io/FE2E/}{here}.
RealisMotion: Decomposed Human Motion Control and Video Generation in the World Space
Aug 12, 2025Generating human videos with realistic and controllable motions is a challenging task. While existing methods can generate visually compelling videos, they lack separate control over four key video elements: foreground subject, background video, human trajectory and action patterns. In this paper, we propose a decomposed human motion control and video generation framework that explicitly decouples motion from appearance, subject from background, and action from trajectory, enabling flexible mix-and-match composition of these elements. Concretely, we first build a ground-aware 3D world coordinate system and perform motion editing directly in the 3D space. Trajectory control is implemented by unprojecting edited 2D trajectories into 3D with focal-length calibration and coordinate transformation, followed by speed alignment and orientation adjustment; actions are supplied by a motion bank or generated via text-to-motion methods. Then, based on modern text-to-video diffusion transformer models, we inject the subject as tokens for full attention, concatenate the background along the channel dimension, and add motion (trajectory and action) control signals by addition. Such a design opens up the possibility for us to generate realistic videos of anyone doing anything anywhere. Extensive experiments on benchmark datasets and real-world cases demonstrate that our method achieves state-of-the-art performance on both element-wise controllability and overall video quality.
DriveAction: A Benchmark for Exploring Human-like Driving Decisions in VLA Models
Jun 06, 2025Vision-Language-Action (VLA) models have advanced autonomous driving, but existing benchmarks still lack scenario diversity, reliable action-level annotation, and evaluation protocols aligned with human preferences. To address these limitations, we introduce DriveAction, the first action-driven benchmark specifically designed for VLA models, comprising 16,185 QA pairs generated from 2,610 driving scenarios. DriveAction leverages real-world driving data proactively collected by users of production-level autonomous vehicles to ensure broad and representative scenario coverage, offers high-level discrete action labels collected directly from users' actual driving operations, and implements an action-rooted tree-structured evaluation framework that explicitly links vision, language, and action tasks, supporting both comprehensive and task-specific assessment. Our experiments demonstrate that state-of-the-art vision-language models (VLMs) require both vision and language guidance for accurate action prediction: on average, accuracy drops by 3.3% without vision input, by 4.1% without language input, and by 8.0% without either. Our evaluation supports precise identification of model bottlenecks with robust and consistent results, thus providing new insights and a rigorous foundation for advancing human-like decisions in autonomous driving.
UniVG-R1: Reasoning Guided Universal Visual Grounding with Reinforcement Learning
May 20, 2025Traditional visual grounding methods primarily focus on single-image scenarios with simple textual references. However, extending these methods to real-world scenarios that involve implicit and complex instructions, particularly in conjunction with multiple images, poses significant challenges, which is mainly due to the lack of advanced reasoning ability across diverse multi-modal contexts. In this work, we aim to address the more practical universal grounding task, and propose UniVG-R1, a reasoning guided multimodal large language model (MLLM) for universal visual grounding, which enhances reasoning capabilities through reinforcement learning (RL) combined with cold-start data. Specifically, we first construct a high-quality Chain-of-Thought (CoT) grounding dataset, annotated with detailed reasoning chains, to guide the model towards correct reasoning paths via supervised fine-tuning. Subsequently, we perform rule-based reinforcement learning to encourage the model to identify correct reasoning chains, thereby incentivizing its reasoning capabilities. In addition, we identify a difficulty bias arising from the prevalence of easy samples as RL training progresses, and we propose a difficulty-aware weight adjustment strategy to further strengthen the performance. Experimental results demonstrate the effectiveness of UniVG-R1, which achieves state-of-the-art performance on MIG-Bench with a 9.1% improvement over the previous method. Furthermore, our model exhibits strong generalizability, achieving an average improvement of 23.4% in zero-shot performance across four image and video reasoning grounding benchmarks. The project page can be accessed at https://amap-ml.github.io/UniVG-R1-page/.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025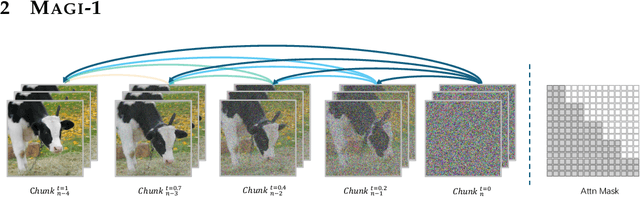
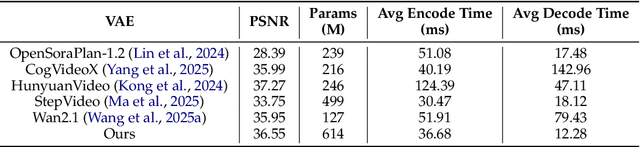
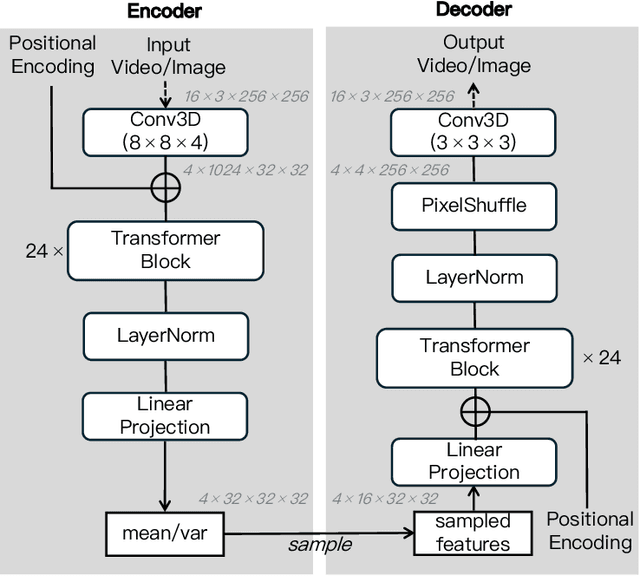
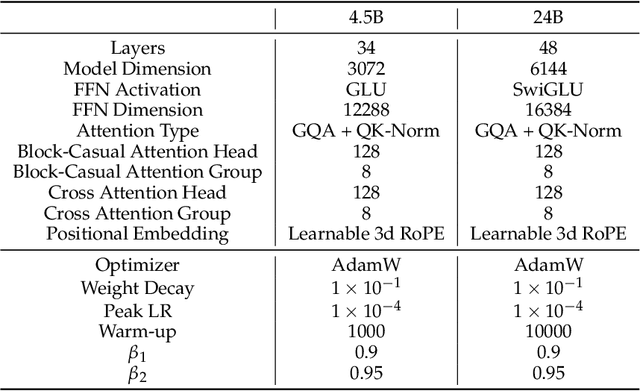
We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
FLUX-Text: A Simple and Advanced Diffusion Transformer Baseline for Scene Text Editing
May 06, 2025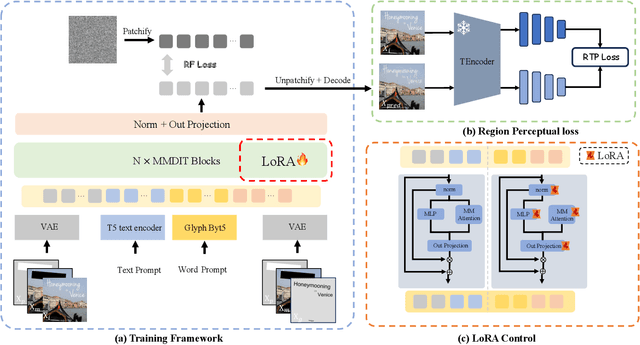
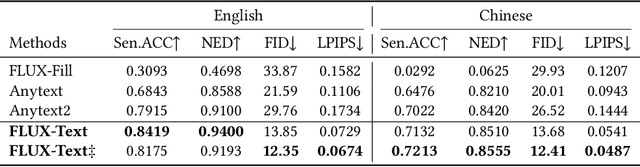
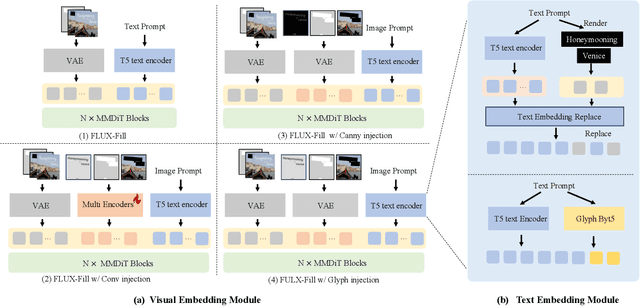

The task of scene text editing is to modify or add texts on images while maintaining the fidelity of newly generated text and visual coherence with the background. Recent works based on latent diffusion models (LDM) show improved text editing results, yet still face challenges and often generate inaccurate or unrecognizable characters, especially for non-Latin ones (\eg, Chinese), which have complex glyph structures. To address these issues, we present FLUX-Text, a simple and advanced multilingual scene text editing framework based on FLUX-Fill. Specifically, we carefully investigate glyph conditioning, considering both visual and textual modalities. To retain the original generative capabilities of FLUX-Fill while enhancing its understanding and generation of glyphs, we propose lightweight glyph and text embedding modules. Owning to the lightweight design, FLUX-Text is trained only with $100K$ training examples compared to current popular methods trained with 2.9M ones. With no bells and whistles, our method achieves state-of-the-art performance on text editing tasks. Qualitative and quantitative experiments on the public datasets demonstrate that our method surpasses previous works in text fidelity.