 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTEXTS-Diff: TEXTS-Aware Diffusion Model for Real-World Text Image Super-Resolution
Jan 24, 2026Real-world text image super-resolution aims to restore overall visual quality and text legibility in images suffering from diverse degradations and text distortions. However, the scarcity of text image data in existing datasets results in poor performance on text regions. In addition, datasets consisting of isolated text samples limit the quality of background reconstruction. To address these limitations, we construct Real-Texts, a large-scale, high-quality dataset collected from real-world images, which covers diverse scenarios and contains natural text instances in both Chinese and English. Additionally, we propose the TEXTS-Aware Diffusion Model (TEXTS-Diff) to achieve high-quality generation in both background and textual regions. This approach leverages abstract concepts to improve the understanding of textual elements within visual scenes and concrete text regions to enhance textual details. It mitigates distortions and hallucination artifacts commonly observed in text regions, while preserving high-quality visual scene fidelity. Extensive experiments demonstrate that our method achieves state-of-the-art performance across multiple evaluation metrics, exhibiting superior generalization ability and text restoration accuracy in complex scenarios. All the code, model, and dataset will be released.
Semantic Context Matters: Improving Conditioning for Autoregressive Models
Nov 18, 2025Recently, autoregressive (AR) models have shown strong potential in image generation, offering better scalability and easier integration with unified multi-modal systems compared to diffusion-based methods. However, extending AR models to general image editing remains challenging due to weak and inefficient conditioning, often leading to poor instruction adherence and visual artifacts. To address this, we propose SCAR, a Semantic-Context-driven method for Autoregressive models. SCAR introduces two key components: Compressed Semantic Prefilling, which encodes high-level semantics into a compact and efficient prefix, and Semantic Alignment Guidance, which aligns the last visual hidden states with target semantics during autoregressive decoding to enhance instruction fidelity. Unlike decoding-stage injection methods, SCAR builds upon the flexibility and generality of vector-quantized-based prefilling while overcoming its semantic limitations and high cost. It generalizes across both next-token and next-set AR paradigms with minimal architectural changes. SCAR achieves superior visual fidelity and semantic alignment on both instruction editing and controllable generation benchmarks, outperforming prior AR-based methods while maintaining controllability. All code will be released.
FLUX-Text: A Simple and Advanced Diffusion Transformer Baseline for Scene Text Editing
May 06, 2025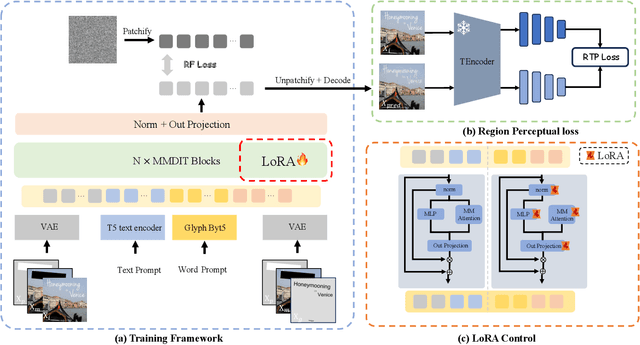
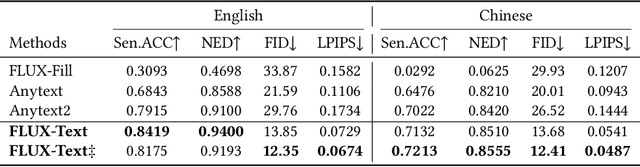
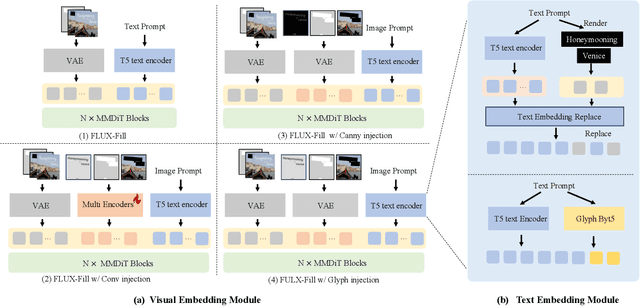

The task of scene text editing is to modify or add texts on images while maintaining the fidelity of newly generated text and visual coherence with the background. Recent works based on latent diffusion models (LDM) show improved text editing results, yet still face challenges and often generate inaccurate or unrecognizable characters, especially for non-Latin ones (\eg, Chinese), which have complex glyph structures. To address these issues, we present FLUX-Text, a simple and advanced multilingual scene text editing framework based on FLUX-Fill. Specifically, we carefully investigate glyph conditioning, considering both visual and textual modalities. To retain the original generative capabilities of FLUX-Fill while enhancing its understanding and generation of glyphs, we propose lightweight glyph and text embedding modules. Owning to the lightweight design, FLUX-Text is trained only with $100K$ training examples compared to current popular methods trained with 2.9M ones. With no bells and whistles, our method achieves state-of-the-art performance on text editing tasks. Qualitative and quantitative experiments on the public datasets demonstrate that our method surpasses previous works in text fidelity.
Next Token Is Enough: Realistic Image Quality and Aesthetic Scoring with Multimodal Large Language Model
Mar 08, 2025The rapid expansion of mobile internet has resulted in a substantial increase in user-generated content (UGC) images, thereby making the thorough assessment of UGC images both urgent and essential. Recently, multimodal large language models (MLLMs) have shown great potential in image quality assessment (IQA) and image aesthetic assessment (IAA). Despite this progress, effectively scoring the quality and aesthetics of UGC images still faces two main challenges: 1) A single score is inadequate to capture the hierarchical human perception. 2) How to use MLLMs to output numerical scores, such as mean opinion scores (MOS), remains an open question. To address these challenges, we introduce a novel dataset, named Realistic image Quality and Aesthetic (RealQA), including 14,715 UGC images, each of which is annoted with 10 fine-grained attributes. These attributes span three levels: low level (e.g., image clarity), middle level (e.g., subject integrity) and high level (e.g., composition). Besides, we conduct a series of in-depth and comprehensive investigations into how to effectively predict numerical scores using MLLMs. Surprisingly, by predicting just two extra significant digits, the next token paradigm can achieve SOTA performance. Furthermore, with the help of chain of thought (CoT) combined with the learnt fine-grained attributes, the proposed method can outperform SOTA methods on five public datasets for IQA and IAA with superior interpretability and show strong zero-shot generalization for video quality assessment (VQA). The code and dataset will be released.
Contextual Multi-Scale Region Convolutional 3D Network for Activity Detection
Jan 28, 2018

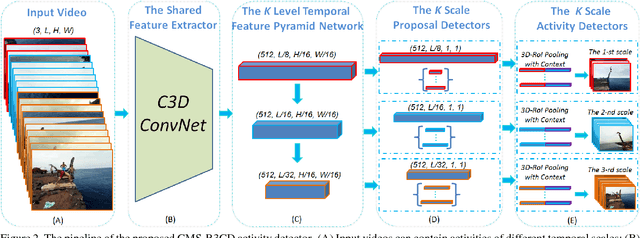

Activity detection is a fundamental problem in computer vision. Detecting activities of different temporal scales is particularly challenging. In this paper, we propose the contextual multi-scale region convolutional 3D network (CMS-RC3D) for activity detection. To deal with the inherent temporal scale variability of activity instances, the temporal feature pyramid is used to represent activities of different temporal scales. On each level of the temporal feature pyramid, an activity proposal detector and an activity classifier are learned to detect activities of specific temporal scales. Temporal contextual information is fused into activity classifiers for better recognition. More importantly, the entire model at all levels can be trained end-to-end. Our CMS-RC3D detector can deal with activities at all temporal scale ranges with only a single pass through the backbone network. We test our detector on two public activity detection benchmarks, THUMOS14 and ActivityNet. Extensive experiments show that the proposed CMS-RC3D detector outperforms state-of-the-art methods on THUMOS14 by a substantial margin and achieves comparable results on ActivityNet despite using a shallow feature extractor.
Multi-Branch Fully Convolutional Network for Face Detection
Jul 20, 2017

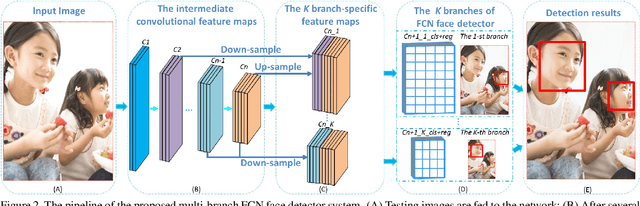

Face detection is a fundamental problem in computer vision. It is still a challenging task in unconstrained conditions due to significant variations in scale, pose, expressions, and occlusion. In this paper, we propose a multi-branch fully convolutional network (MB-FCN) for face detection, which considers both efficiency and effectiveness in the design process. Our MB-FCN detector can deal with faces at all scale ranges with only a single pass through the backbone network. As such, our MB-FCN model saves computation and thus is more efficient, compared to previous methods that make multiple passes. For each branch, the specific skip connections of the convolutional feature maps at different layers are exploited to represent faces in specific scale ranges. Specifically, small faces can be represented with both shallow fine-grained and deep powerful coarse features. With this representation, superior improvement in performance is registered for the task of detecting small faces. We test our MB-FCN detector on two public face detection benchmarks, including FDDB and WIDER FACE. Extensive experiments show that our detector outperforms state-of-the-art methods on all these datasets in general and by a substantial margin on the most challenging among them (e.g. WIDER FACE Hard subset). Also, MB-FCN runs at 15 FPS on a GPU for images of size 640 x 480 with no assumption on the minimum detectable face size.