 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstrAct: Towards Action-Centric Understanding in Instructional Videos
Apr 09, 2026Understanding instructional videos requires recognizing fine-grained actions and modeling their temporal relations, which remains challenging for current Video Foundation Models (VFMs). This difficulty stems from noisy web supervision and a pervasive "static bias", where models rely on objects rather than motion cues. To address this, we propose InstrAction, a pretraining framework for instructional videos' action-centric representations. We first introduce a data-driven strategy, which filters noisy captions and generates action-centric hard negatives to disentangle actions from objects during contrastive learning. At the visual feature level, an Action Perceiver extracts motion-relevant tokens from redundant video encodings. Beyond contrastive learning, we introduce two auxiliary objectives: Dynamic Time Warping alignment (DTW-Align) for modeling sequential temporal structure, and Masked Action Modeling (MAM) for strengthening cross-modal grounding. Finally, we introduce the InstrAct Bench to evaluate action-centric understanding, where our method consistently outperforms state-of-the-art VFMs on semantic reasoning, procedural logic, and fine-grained retrieval tasks.
Stratified Avatar Generation from Sparse Observations
Jun 03, 2024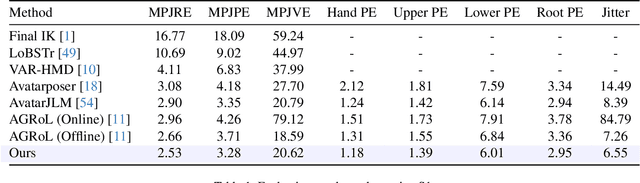
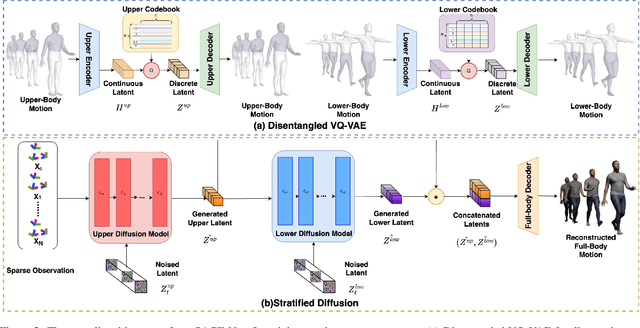
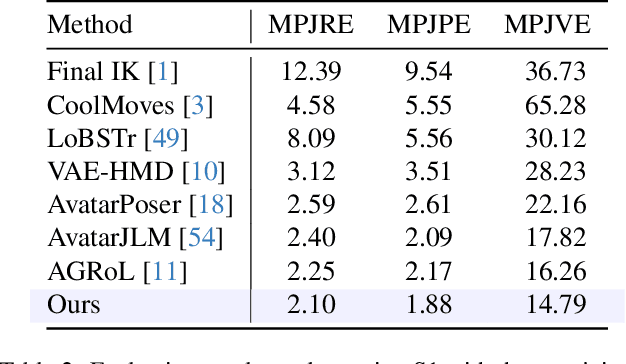
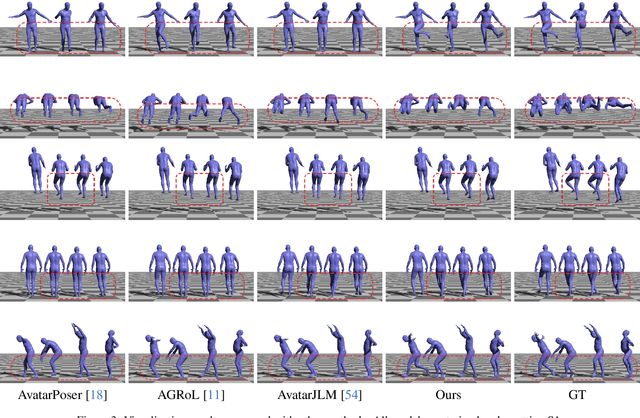
Estimating 3D full-body avatars from AR/VR devices is essential for creating immersive experiences in AR/VR applications. This task is challenging due to the limited input from Head Mounted Devices, which capture only sparse observations from the head and hands. Predicting the full-body avatars, particularly the lower body, from these sparse observations presents significant difficulties. In this paper, we are inspired by the inherent property of the kinematic tree defined in the Skinned Multi-Person Linear (SMPL) model, where the upper body and lower body share only one common ancestor node, bringing the potential of decoupled reconstruction. We propose a stratified approach to decouple the conventional full-body avatar reconstruction pipeline into two stages, with the reconstruction of the upper body first and a subsequent reconstruction of the lower body conditioned on the previous stage. To implement this straightforward idea, we leverage the latent diffusion model as a powerful probabilistic generator, and train it to follow the latent distribution of decoupled motions explored by a VQ-VAE encoder-decoder model. Extensive experiments on AMASS mocap dataset demonstrate our state-of-the-art performance in the reconstruction of full-body motions.
Reconstruct before Query: Continual Missing Modality Learning with Decomposed Prompt Collaboration
Mar 17, 2024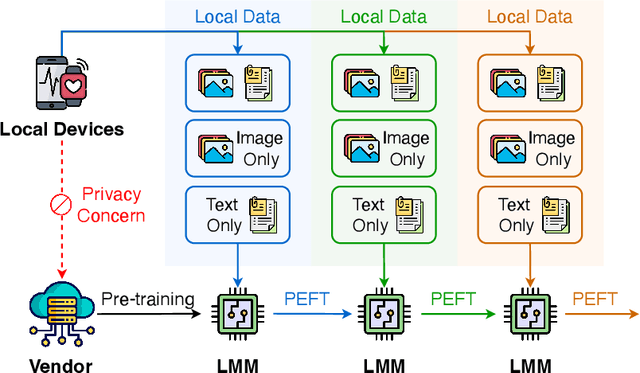



Pre-trained large multi-modal models (LMMs) exploit fine-tuning to adapt diverse user applications. Nevertheless, fine-tuning may face challenges due to deactivated sensors (e.g., cameras turned off for privacy or technical issues), yielding modality-incomplete data and leading to inconsistency in training data and the data for inference. Additionally, continuous training leads to catastrophic forgetting, diluting the knowledge in pre-trained LMMs. To overcome these challenges, we introduce a novel task, Continual Missing Modality Learning (CMML), to investigate how models can generalize when data of certain modalities is missing during continual fine-tuning. Our preliminary benchmarks reveal that existing methods suffer from a significant performance drop in CMML, even with the aid of advanced continual learning techniques. Therefore, we devise a framework termed Reconstruct before Query (RebQ). It decomposes prompts into modality-specific ones and breaks them into components stored in pools accessible via a key-query mechanism, which facilitates ParameterEfficient Fine-Tuning and enhances knowledge transferability for subsequent tasks. Meanwhile, our RebQ leverages extensive multi-modal knowledge from pre-trained LMMs to reconstruct the data of missing modality. Comprehensive experiments demonstrate that RebQ effectively reconstructs the missing modality information and retains pre-trained knowledge. Specifically, compared with the baseline, RebQ improves average precision from 20.00 to 50.92 and decreases average forgetting from 75.95 to 8.56. Code and datasets are available on https://github.com/Tree-Shu-Zhao/RebQ.pytorch
NEUCORE: Neural Concept Reasoning for Composed Image Retrieval
Oct 02, 2023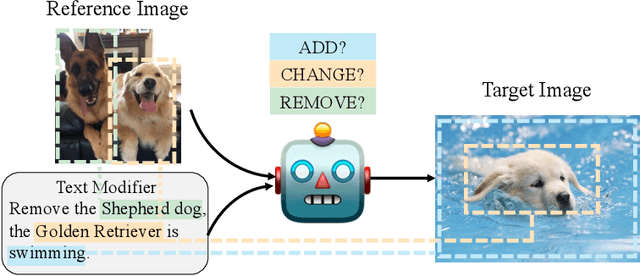

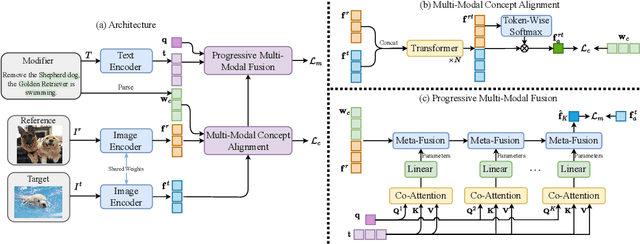
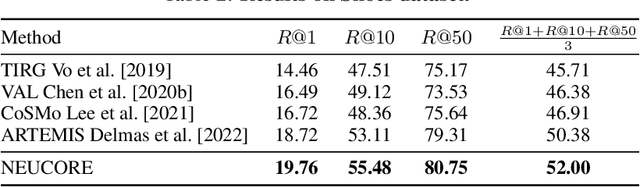
Composed image retrieval which combines a reference image and a text modifier to identify the desired target image is a challenging task, and requires the model to comprehend both vision and language modalities and their interactions. Existing approaches focus on holistic multi-modal interaction modeling, and ignore the composed and complimentary property between the reference image and text modifier. In order to better utilize the complementarity of multi-modal inputs for effective information fusion and retrieval, we move the multi-modal understanding to fine-granularity at concept-level, and learn the multi-modal concept alignment to identify the visual location in reference or target images corresponding to text modifier. Toward the end, we propose a NEUral COncept REasoning (NEUCORE) model which incorporates multi-modal concept alignment and progressive multimodal fusion over aligned concepts. Specifically, considering that text modifier may refer to semantic concepts not existing in the reference image and requiring to be added into the target image, we learn the multi-modal concept alignment between the text modifier and the concatenation of reference and target images, under multiple-instance learning framework with image and sentence level weak supervision. Furthermore, based on aligned concepts, to form discriminative fusion features of the input modalities for accurate target image retrieval, we propose a progressive fusion strategy with unified execution architecture instantiated by the attended language semantic concepts. Our proposed approach is evaluated on three datasets and achieves state-of-the-art results.
Less is More: Toward Zero-Shot Local Scene Graph Generation via Foundation Models
Oct 02, 2023Humans inherently recognize objects via selective visual perception, transform specific regions from the visual field into structured symbolic knowledge, and reason their relationships among regions based on the allocation of limited attention resources in line with humans' goals. While it is intuitive for humans, contemporary perception systems falter in extracting structural information due to the intricate cognitive abilities and commonsense knowledge required. To fill this gap, we present a new task called Local Scene Graph Generation. Distinct from the conventional scene graph generation task, which encompasses generating all objects and relationships in an image, our proposed task aims to abstract pertinent structural information with partial objects and their relationships for boosting downstream tasks that demand advanced comprehension and reasoning capabilities. Correspondingly, we introduce zEro-shot Local scEne GrAph geNeraTion (ELEGANT), a framework harnessing foundation models renowned for their powerful perception and commonsense reasoning, where collaboration and information communication among foundation models yield superior outcomes and realize zero-shot local scene graph generation without requiring labeled supervision. Furthermore, we propose a novel open-ended evaluation metric, Entity-level CLIPScorE (ECLIPSE), surpassing previous closed-set evaluation metrics by transcending their limited label space, offering a broader assessment. Experiment results show that our approach markedly outperforms baselines in the open-ended evaluation setting, and it also achieves a significant performance boost of up to 24.58% over prior methods in the close-set setting, demonstrating the effectiveness and powerful reasoning ability of our proposed framework.
CircleNet: Reciprocating Feature Adaptation for Robust Pedestrian Detection
Dec 12, 2022Pedestrian detection in the wild remains a challenging problem especially when the scene contains significant occlusion and/or low resolution of the pedestrians to be detected. Existing methods are unable to adapt to these difficult cases while maintaining acceptable performance. In this paper we propose a novel feature learning model, referred to as CircleNet, to achieve feature adaptation by mimicking the process humans looking at low resolution and occluded objects: focusing on it again, at a finer scale, if the object can not be identified clearly for the first time. CircleNet is implemented as a set of feature pyramids and uses weight sharing path augmentation for better feature fusion. It targets at reciprocating feature adaptation and iterative object detection using multiple top-down and bottom-up pathways. To take full advantage of the feature adaptation capability in CircleNet, we design an instance decomposition training strategy to focus on detecting pedestrian instances of various resolutions and different occlusion levels in each cycle. Specifically, CircleNet implements feature ensemble with the idea of hard negative boosting in an end-to-end manner. Experiments on two pedestrian detection datasets, Caltech and CityPersons, show that CircleNet improves the performance of occluded and low-resolution pedestrians with significant margins while maintaining good performance on normal instances.
Weakly-Supervised Temporal Action Detection for Fine-Grained Videos with Hierarchical Atomic Actions
Jul 24, 2022
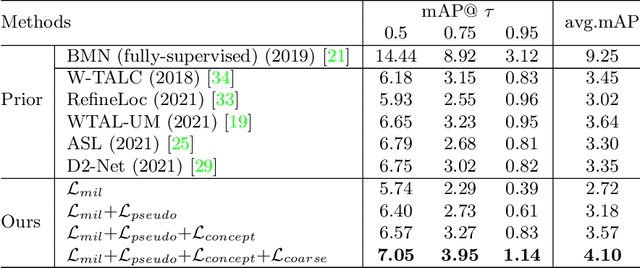
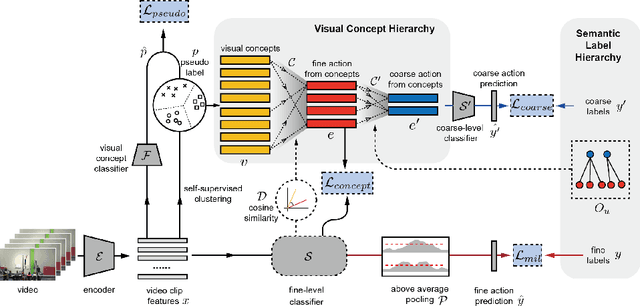
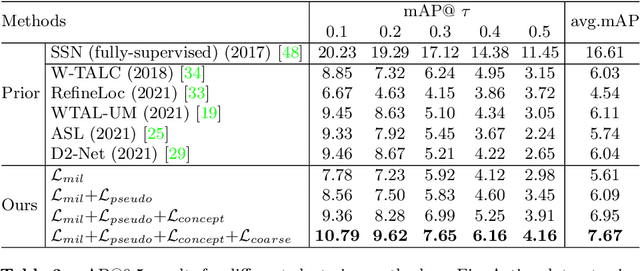
Action understanding has evolved into the era of fine granularity, as most human behaviors in real life have only minor differences. To detect these fine-grained actions accurately in a label-efficient way, we tackle the problem of weakly-supervised fine-grained temporal action detection in videos for the first time. Without the careful design to capture subtle differences between fine-grained actions, previous weakly-supervised models for general action detection cannot perform well in the fine-grained setting. We propose to model actions as the combinations of reusable atomic actions which are automatically discovered from data through self-supervised clustering, in order to capture the commonality and individuality of fine-grained actions. The learnt atomic actions, represented by visual concepts, are further mapped to fine and coarse action labels leveraging the semantic label hierarchy. Our approach constructs a visual representation hierarchy of four levels: clip level, atomic action level, fine action class level and coarse action class level, with supervision at each level. Extensive experiments on two large-scale fine-grained video datasets, FineAction and FineGym, show the benefit of our proposed weakly-supervised model for fine-grained action detection, and it achieves state-of-the-art results.
Disentangled Action Recognition with Knowledge Bases
Jul 04, 2022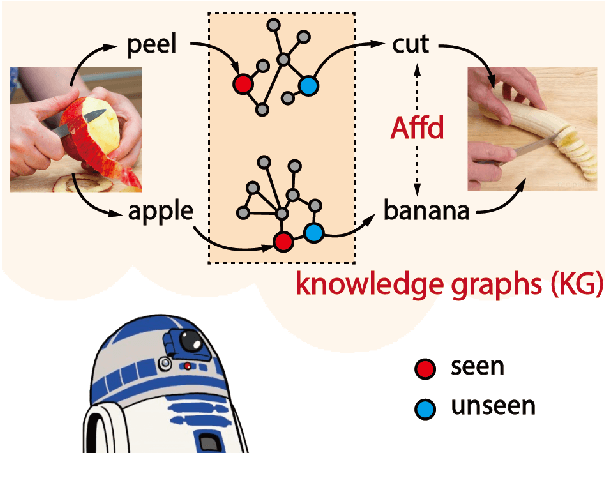
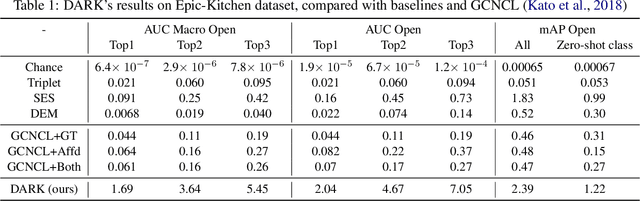
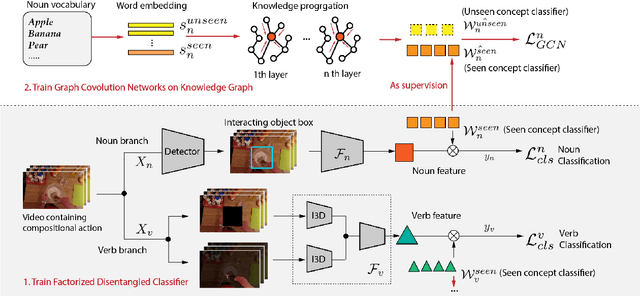
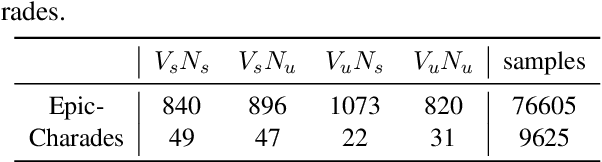
Action in video usually involves the interaction of human with objects. Action labels are typically composed of various combinations of verbs and nouns, but we may not have training data for all possible combinations. In this paper, we aim to improve the generalization ability of the compositional action recognition model to novel verbs or novel nouns that are unseen during training time, by leveraging the power of knowledge graphs. Previous work utilizes verb-noun compositional action nodes in the knowledge graph, making it inefficient to scale since the number of compositional action nodes grows quadratically with respect to the number of verbs and nouns. To address this issue, we propose our approach: Disentangled Action Recognition with Knowledge-bases (DARK), which leverages the inherent compositionality of actions. DARK trains a factorized model by first extracting disentangled feature representations for verbs and nouns, and then predicting classification weights using relations in external knowledge graphs. The type constraint between verb and noun is extracted from external knowledge bases and finally applied when composing actions. DARK has better scalability in the number of objects and verbs, and achieves state-of-the-art performance on the Charades dataset. We further propose a new benchmark split based on the Epic-kitchen dataset which is an order of magnitude bigger in the numbers of classes and samples, and benchmark various models on this benchmark.
Syntax Controlled Knowledge Graph-to-Text Generation with Order and Semantic Consistency
Jul 02, 2022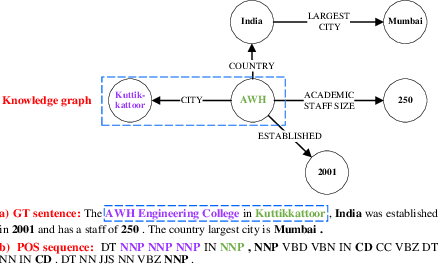
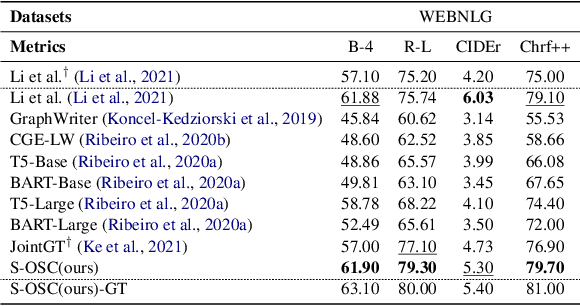
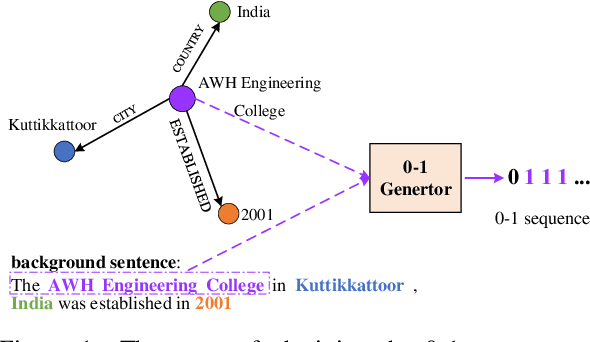
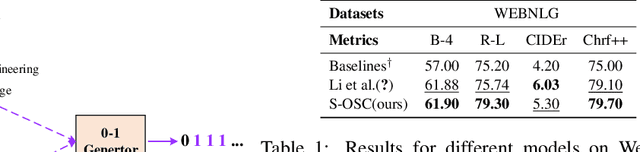
The knowledge graph (KG) stores a large amount of structural knowledge, while it is not easy for direct human understanding. Knowledge graph-to-text (KG-to-text) generation aims to generate easy-to-understand sentences from the KG, and at the same time, maintains semantic consistency between generated sentences and the KG. Existing KG-to-text generation methods phrase this task as a sequence-to-sequence generation task with linearized KG as input and consider the consistency issue of the generated texts and KG through a simple selection between decoded sentence word and KG node word at each time step. However, the linearized KG order is commonly obtained through a heuristic search without data-driven optimization. In this paper, we optimize the knowledge description order prediction under the order supervision extracted from the caption and further enhance the consistency of the generated sentences and KG through syntactic and semantic regularization. We incorporate the Part-of-Speech (POS) syntactic tags to constrain the positions to copy words from the KG and employ a semantic context scoring function to evaluate the semantic fitness for each word in its local context when decoding each word in the generated sentence. Extensive experiments are conducted on two datasets, WebNLG and DART, and achieve state-of-the-art performances.
Temporal Action Detection with Multi-level Supervision
Nov 24, 2020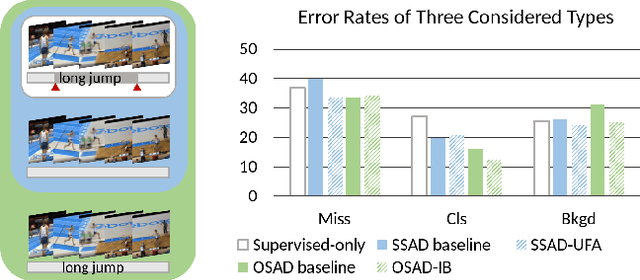
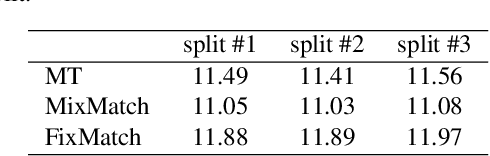
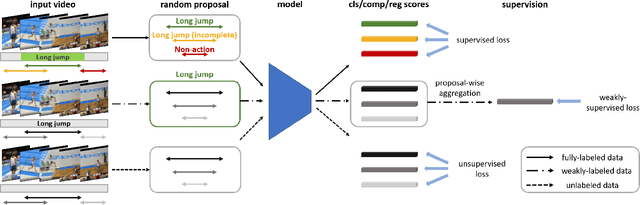
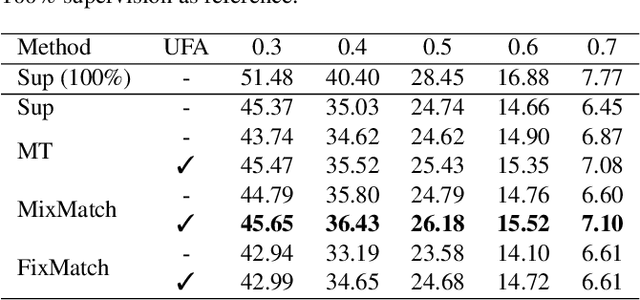
Training temporal action detection in videos requires large amounts of labeled data, yet such annotation is expensive to collect. Incorporating unlabeled or weakly-labeled data to train action detection model could help reduce annotation cost. In this work, we first introduce the Semi-supervised Action Detection (SSAD) task with a mixture of labeled and unlabeled data and analyze different types of errors in the proposed SSAD baselines which are directly adapted from the semi-supervised classification task. To alleviate the main error of action incompleteness (i.e., missing parts of actions) in SSAD baselines, we further design an unsupervised foreground attention (UFA) module utilizing the "independence" between foreground and background motion. Then we incorporate weakly-labeled data into SSAD and propose Omni-supervised Action Detection (OSAD) with three levels of supervision. An information bottleneck (IB) suppressing the scene information in non-action frames while preserving the action information is designed to help overcome the accompanying action-context confusion problem in OSAD baselines. We extensively benchmark against the baselines for SSAD and OSAD on our created data splits in THUMOS14 and ActivityNet1.2, and demonstrate the effectiveness of the proposed UFA and IB methods. Lastly, the benefit of our full OSAD-IB model under limited annotation budgets is shown by exploring the optimal annotation strategy for labeled, unlabeled and weakly-labeled data.