 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Function Optimization Scheme for Image Classification
Sep 07, 2024Activation function has a significant impact on the dynamics, convergence, and performance of deep neural networks. The search for a consistent and high-performing activation function has always been a pursuit during deep learning model development. Existing state-of-the-art activation functions are manually designed with human expertise except for Swish. Swish was developed using a reinforcement learning-based search strategy. In this study, we propose an evolutionary approach for optimizing activation functions specifically for image classification tasks, aiming to discover functions that outperform current state-of-the-art options. Through this optimization framework, we obtain a series of high-performing activation functions denoted as Exponential Error Linear Unit (EELU). The developed activation functions are evaluated for image classification tasks from two perspectives: (1) five state-of-the-art neural network architectures, such as ResNet50, AlexNet, VGG16, MobileNet, and Compact Convolutional Transformer which cover computationally heavy to light neural networks, and (2) eight standard datasets, including CIFAR10, Imagenette, MNIST, Fashion MNIST, Beans, Colorectal Histology, CottonWeedID15, and TinyImageNet which cover from typical machine vision benchmark, agricultural image applications to medical image applications. Finally, we statistically investigate the generalization of the resultant activation functions developed through the optimization scheme. With a Friedman test, we conclude that the optimization scheme is able to generate activation functions that outperform the existing standard ones in 92.8% cases among 28 different cases studied, and $-x\cdot erf(e^{-x})$ is found to be the best activation function for image classification generated by the optimization scheme.
Cheems: Wonderful Matrices More Efficient and More Effective Architecture
Jul 25, 2024



Recent studies have shown that, relative position encoding performs well in selective state space model scanning algorithms, and the architecture that balances SSM and Attention enhances the efficiency and effectiveness of the algorithm, while the sparse activation of the mixture of experts reduces the training cost. I studied the effectiveness of using different position encodings in structured state space dual algorithms, and the more effective SSD-Attn internal and external function mixing method, and designed a more efficient cross domain mixture of experts. I found that the same matrix is very wonderful in different algorithms, which allows us to establish a new hybrid sparse architecture: Cheems. Compared with other hybrid architectures, it is more efficient and more effective in language modeling tasks.
PanelNet: Understanding 360 Indoor Environment via Panel Representation
May 16, 2023Indoor 360 panoramas have two essential properties. (1) The panoramas are continuous and seamless in the horizontal direction. (2) Gravity plays an important role in indoor environment design. By leveraging these properties, we present PanelNet, a framework that understands indoor environments using a novel panel representation of 360 images. We represent an equirectangular projection (ERP) as consecutive vertical panels with corresponding 3D panel geometry. To reduce the negative impact of panoramic distortion, we incorporate a panel geometry embedding network that encodes both the local and global geometric features of a panel. To capture the geometric context in room design, we introduce Local2Global Transformer, which aggregates local information within a panel and panel-wise global context. It greatly improves the model performance with low training overhead. Our method outperforms existing methods on indoor 360 depth estimation and shows competitive results against state-of-the-art approaches on the task of indoor layout estimation and semantic segmentation.
Weakly-Supervised Temporal Action Detection for Fine-Grained Videos with Hierarchical Atomic Actions
Jul 24, 2022
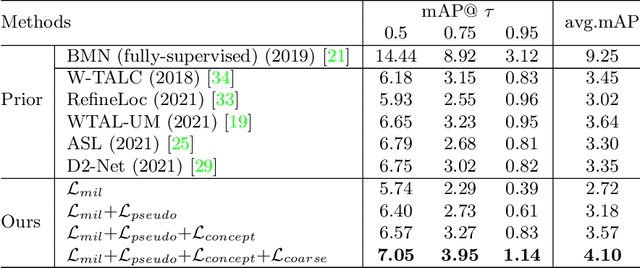
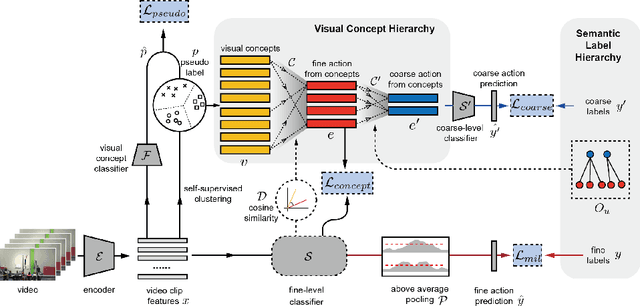
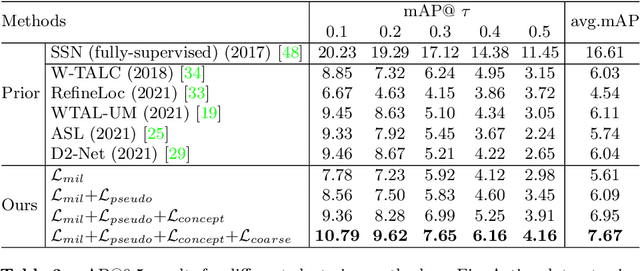
Action understanding has evolved into the era of fine granularity, as most human behaviors in real life have only minor differences. To detect these fine-grained actions accurately in a label-efficient way, we tackle the problem of weakly-supervised fine-grained temporal action detection in videos for the first time. Without the careful design to capture subtle differences between fine-grained actions, previous weakly-supervised models for general action detection cannot perform well in the fine-grained setting. We propose to model actions as the combinations of reusable atomic actions which are automatically discovered from data through self-supervised clustering, in order to capture the commonality and individuality of fine-grained actions. The learnt atomic actions, represented by visual concepts, are further mapped to fine and coarse action labels leveraging the semantic label hierarchy. Our approach constructs a visual representation hierarchy of four levels: clip level, atomic action level, fine action class level and coarse action class level, with supervision at each level. Extensive experiments on two large-scale fine-grained video datasets, FineAction and FineGym, show the benefit of our proposed weakly-supervised model for fine-grained action detection, and it achieves state-of-the-art results.
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 17, 2022
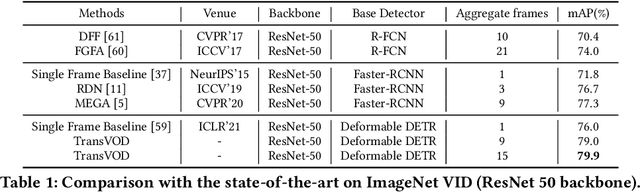
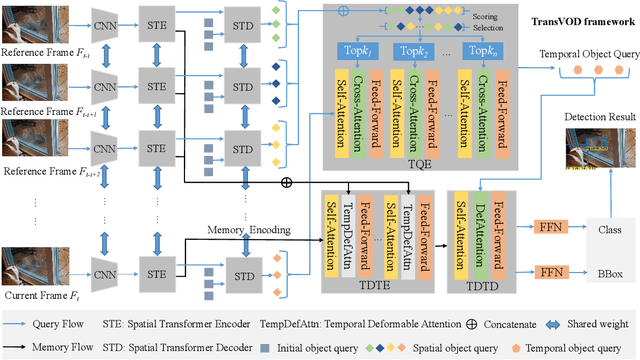

Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
End-to-End Video Object Detection with Spatial-Temporal Transformers
May 23, 2021Recently, DETR and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, an end-to-end video object detection model based on a spatial-temporal Transformer architecture. The goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow, recurrent neural networks, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS or Tubelet rescoring, which keeps the pipeline simple and clean. In particular, we present temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal Transformer consists of three components: Temporal Deformable Transformer Encoder (TDTE) to encode the multiple frame spatial details, Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. TransVOD yields comparable results performance on the benchmark of ImageNet VID. We hope our TransVOD can provide a new perspective for video object detection. Code will be made publicly available at https://github.com/SJTU-LuHe/TransVOD.