 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Interactive Training for Video Segmentation
Mar 27, 2026Interactive video segmentation often requires many user interventions for robust performance in challenging scenarios (e.g., occlusions, object separations, camouflage, etc.). Yet, even state-of-the-art models like SAM2 use corrections only for immediate fixes without learning from this feedback, leading to inefficient, repetitive user effort. To address this, we introduce Live Interactive Training (LIT), a novel framework for prompt-based visual systems where models also learn online from human corrections at inference time. Our primary instantiation, LIT-LoRA, implements this by continually updating a lightweight LoRA module on-the-fly. When a user provides a correction, this module is rapidly trained on that feedback, allowing the vision system to improve performance on subsequent frames of the same video. Leveraging the core principles of LIT, our LIT-LoRA implementation achieves an average 18-34% reduction in total corrections on challenging video segmentation benchmarks, with a negligible training overhead of ~0.5s per correction. We further demonstrate its generality by successfully adapting it to other segmentation models and extending it to CLIP-based fine-grained image classification. Our work highlights the promise of live adaptation to transform interactive tools and significantly reduce redundant human effort in complex visual tasks. Project: https://youngxinyu1802.github.io/projects/LIT/.
PanelNet: Understanding 360 Indoor Environment via Panel Representation
May 16, 2023Indoor 360 panoramas have two essential properties. (1) The panoramas are continuous and seamless in the horizontal direction. (2) Gravity plays an important role in indoor environment design. By leveraging these properties, we present PanelNet, a framework that understands indoor environments using a novel panel representation of 360 images. We represent an equirectangular projection (ERP) as consecutive vertical panels with corresponding 3D panel geometry. To reduce the negative impact of panoramic distortion, we incorporate a panel geometry embedding network that encodes both the local and global geometric features of a panel. To capture the geometric context in room design, we introduce Local2Global Transformer, which aggregates local information within a panel and panel-wise global context. It greatly improves the model performance with low training overhead. Our method outperforms existing methods on indoor 360 depth estimation and shows competitive results against state-of-the-art approaches on the task of indoor layout estimation and semantic segmentation.
Semi-supervised Dense Keypointsusing Unlabeled Multiview Images
Sep 20, 2021
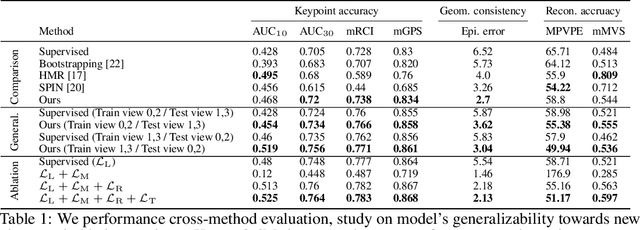


This paper presents a new end-to-end semi-supervised framework to learn a dense keypoint detector using unlabeled multiview images. A key challenge lies in finding the exact correspondences between the dense keypoints in multiple views since the inverse of keypoint mapping can be neither analytically derived nor differentiated. This limits applying existing multiview supervision approaches on sparse keypoint detection that rely on the exact correspondences. To address this challenge, we derive a new probabilistic epipolar constraint that encodes the two desired properties. (1) Soft correspondence: we define a matchability, which measures a likelihood of a point matching to the other image's corresponding point, thus relaxing the exact correspondences' requirement. (2) Geometric consistency: every point in the continuous correspondence fields must satisfy the multiview consistency collectively. We formulate a probabilistic epipolar constraint using a weighted average of epipolar errors through the matchability thereby generalizing the point-to-point geometric error to the field-to-field geometric error. This generalization facilitates learning a geometrically coherent dense keypoint detection model by utilizing a large number of unlabeled multiview images. Additionally, to prevent degenerative cases, we employ a distillation-based regularization by using a pretrained model. Finally, we design a new neural network architecture, made of twin networks, that effectively minimizes the probabilistic epipolar errors of all possible correspondences between two view images by building affinity matrices. Our method shows superior performance compared to existing methods, including non-differentiable bootstrapping in terms of keypoint accuracy, multiview consistency, and 3D reconstruction accuracy.