 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnthroNet: Conditional Generation of Humans via Anthropometrics
Sep 07, 2023We present a novel human body model formulated by an extensive set of anthropocentric measurements, which is capable of generating a wide range of human body shapes and poses. The proposed model enables direct modeling of specific human identities through a deep generative architecture, which can produce humans in any arbitrary pose. It is the first of its kind to have been trained end-to-end using only synthetically generated data, which not only provides highly accurate human mesh representations but also allows for precise anthropometry of the body. Moreover, using a highly diverse animation library, we articulated our synthetic humans' body and hands to maximize the diversity of the learnable priors for model training. Our model was trained on a dataset of $100k$ procedurally-generated posed human meshes and their corresponding anthropometric measurements. Our synthetic data generator can be used to generate millions of unique human identities and poses for non-commercial academic research purposes.
PSP-HDRI$+$: A Synthetic Dataset Generator for Pre-Training of Human-Centric Computer Vision Models
Jul 11, 2022
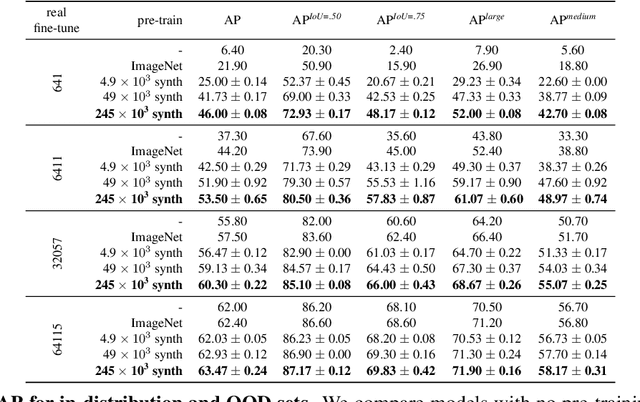
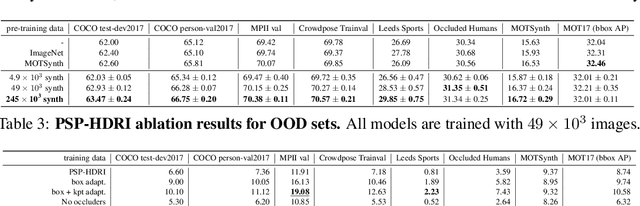

We introduce a new synthetic data generator PSP-HDRI$+$ that proves to be a superior pre-training alternative to ImageNet and other large-scale synthetic data counterparts. We demonstrate that pre-training with our synthetic data will yield a more general model that performs better than alternatives even when tested on out-of-distribution (OOD) sets. Furthermore, using ablation studies guided by person keypoint estimation metrics with an off-the-shelf model architecture, we show how to manipulate our synthetic data generator to further improve model performance.
PeopleSansPeople: A Synthetic Data Generator for Human-Centric Computer Vision
Dec 17, 2021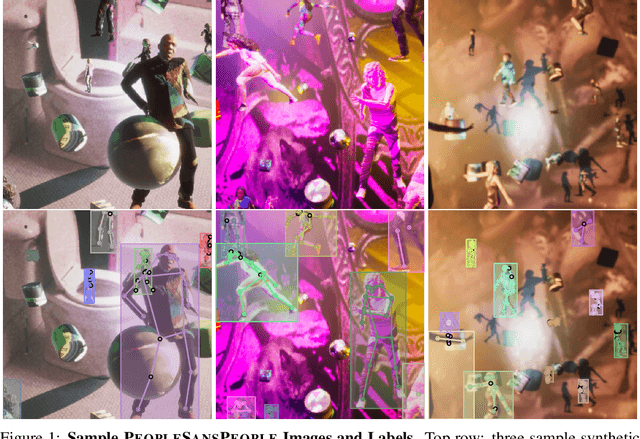



In recent years, person detection and human pose estimation have made great strides, helped by large-scale labeled datasets. However, these datasets had no guarantees or analysis of human activities, poses, or context diversity. Additionally, privacy, legal, safety, and ethical concerns may limit the ability to collect more human data. An emerging alternative to real-world data that alleviates some of these issues is synthetic data. However, creation of synthetic data generators is incredibly challenging and prevents researchers from exploring their usefulness. Therefore, we release a human-centric synthetic data generator PeopleSansPeople which contains simulation-ready 3D human assets, a parameterized lighting and camera system, and generates 2D and 3D bounding box, instance and semantic segmentation, and COCO pose labels. Using PeopleSansPeople, we performed benchmark synthetic data training using a Detectron2 Keypoint R-CNN variant [1]. We found that pre-training a network using synthetic data and fine-tuning on target real-world data (few-shot transfer to limited subsets of COCO-person train [2]) resulted in a keypoint AP of $60.37 \pm 0.48$ (COCO test-dev2017) outperforming models trained with the same real data alone (keypoint AP of $55.80$) and pre-trained with ImageNet (keypoint AP of $57.50$). This freely-available data generator should enable a wide range of research into the emerging field of simulation to real transfer learning in the critical area of human-centric computer vision.
On the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning
Nov 10, 2021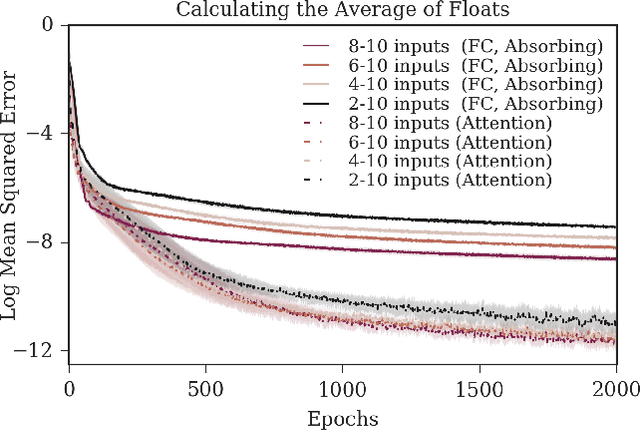
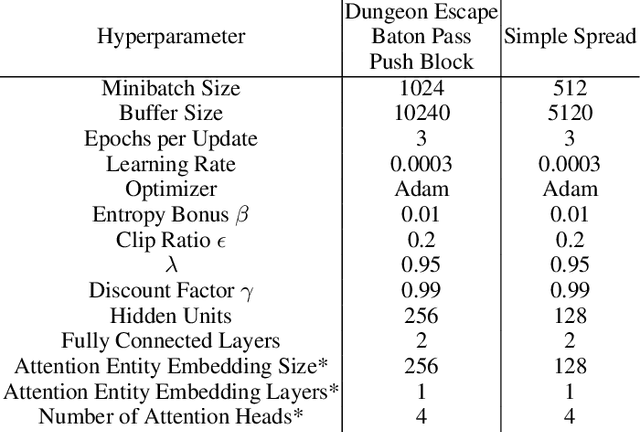

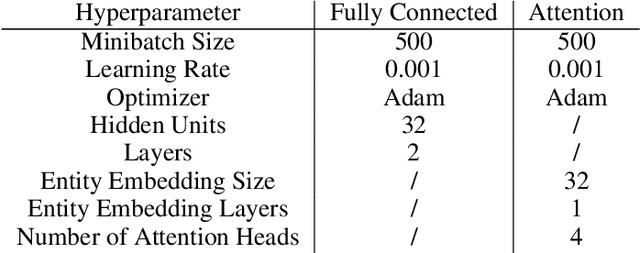
The creation and destruction of agents in cooperative multi-agent reinforcement learning (MARL) is a critically under-explored area of research. Current MARL algorithms often assume that the number of agents within a group remains fixed throughout an experiment. However, in many practical problems, an agent may terminate before their teammates. This early termination issue presents a challenge: the terminated agent must learn from the group's success or failure which occurs beyond its own existence. We refer to propagating value from rewards earned by remaining teammates to terminated agents as the Posthumous Credit Assignment problem. Current MARL methods handle this problem by placing these agents in an absorbing state until the entire group of agents reaches a termination condition. Although absorbing states enable existing algorithms and APIs to handle terminated agents without modification, practical training efficiency and resource use problems exist. In this work, we first demonstrate that sample complexity increases with the quantity of absorbing states in a toy supervised learning task for a fully connected network, while attention is more robust to variable size input. Then, we present a novel architecture for an existing state-of-the-art MARL algorithm which uses attention instead of a fully connected layer with absorbing states. Finally, we demonstrate that this novel architecture significantly outperforms the standard architecture on tasks in which agents are created or destroyed within episodes as well as standard multi-agent coordination tasks.
Semi-supervised Dense Keypointsusing Unlabeled Multiview Images
Sep 20, 2021
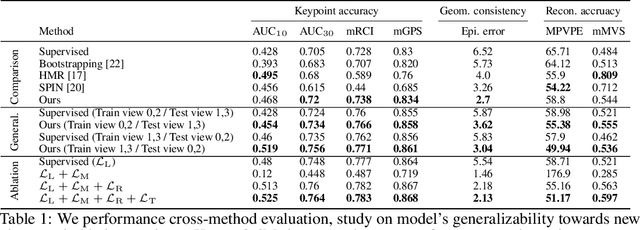


This paper presents a new end-to-end semi-supervised framework to learn a dense keypoint detector using unlabeled multiview images. A key challenge lies in finding the exact correspondences between the dense keypoints in multiple views since the inverse of keypoint mapping can be neither analytically derived nor differentiated. This limits applying existing multiview supervision approaches on sparse keypoint detection that rely on the exact correspondences. To address this challenge, we derive a new probabilistic epipolar constraint that encodes the two desired properties. (1) Soft correspondence: we define a matchability, which measures a likelihood of a point matching to the other image's corresponding point, thus relaxing the exact correspondences' requirement. (2) Geometric consistency: every point in the continuous correspondence fields must satisfy the multiview consistency collectively. We formulate a probabilistic epipolar constraint using a weighted average of epipolar errors through the matchability thereby generalizing the point-to-point geometric error to the field-to-field geometric error. This generalization facilitates learning a geometrically coherent dense keypoint detection model by utilizing a large number of unlabeled multiview images. Additionally, to prevent degenerative cases, we employ a distillation-based regularization by using a pretrained model. Finally, we design a new neural network architecture, made of twin networks, that effectively minimizes the probabilistic epipolar errors of all possible correspondences between two view images by building affinity matrices. Our method shows superior performance compared to existing methods, including non-differentiable bootstrapping in terms of keypoint accuracy, multiview consistency, and 3D reconstruction accuracy.
Unity Perception: Generate Synthetic Data for Computer Vision
Jul 19, 2021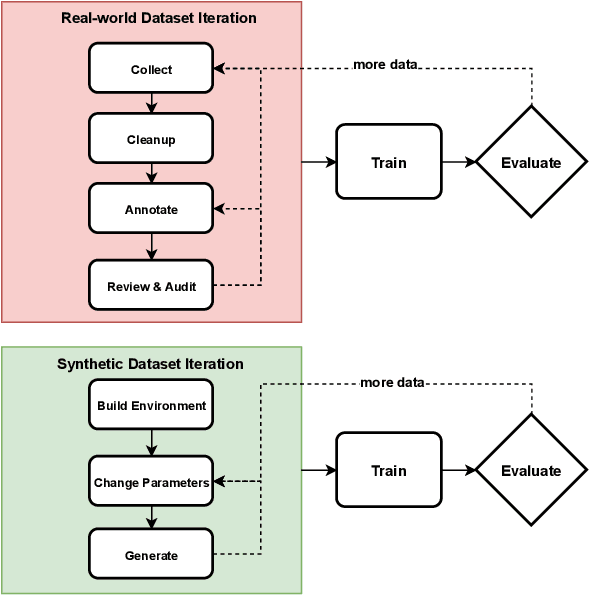


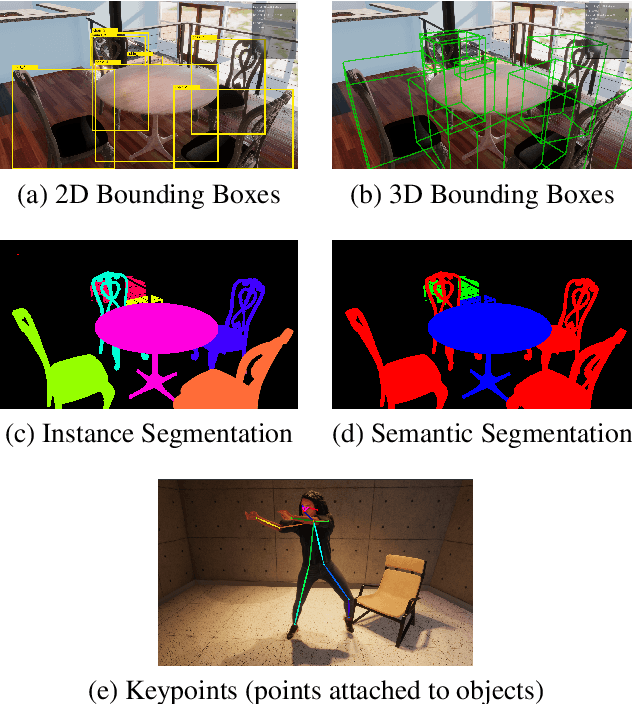
We introduce the Unity Perception package which aims to simplify and accelerate the process of generating synthetic datasets for computer vision tasks by offering an easy-to-use and highly customizable toolset. This open-source package extends the Unity Editor and engine components to generate perfectly annotated examples for several common computer vision tasks. Additionally, it offers an extensible Randomization framework that lets the user quickly construct and configure randomized simulation parameters in order to introduce variation into the generated datasets. We provide an overview of the provided tools and how they work, and demonstrate the value of the generated synthetic datasets by training a 2D object detection model. The model trained with mostly synthetic data outperforms the model trained using only real data.
Technology Readiness Levels for Machine Learning Systems
Jan 11, 2021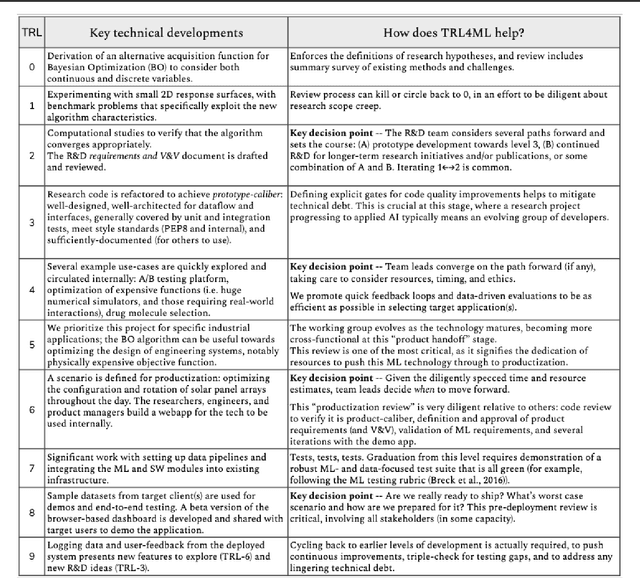

The development and deployment of machine learning (ML) systems can be executed easily with modern tools, but the process is typically rushed and means-to-an-end. The lack of diligence can lead to technical debt, scope creep and misaligned objectives, model misuse and failures, and expensive consequences. Engineering systems, on the other hand, follow well-defined processes and testing standards to streamline development for high-quality, reliable results. The extreme is spacecraft systems, where mission critical measures and robustness are ingrained in the development process. Drawing on experience in both spacecraft engineering and ML (from research through product across domain areas), we have developed a proven systems engineering approach for machine learning development and deployment. Our "Machine Learning Technology Readiness Levels" (MLTRL) framework defines a principled process to ensure robust, reliable, and responsible systems while being streamlined for ML workflows, including key distinctions from traditional software engineering. Even more, MLTRL defines a lingua franca for people across teams and organizations to work collaboratively on artificial intelligence and machine learning technologies. Here we describe the framework and elucidate it with several real world use-cases of developing ML methods from basic research through productization and deployment, in areas such as medical diagnostics, consumer computer vision, satellite imagery, and particle physics.