 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning
Paper and Code
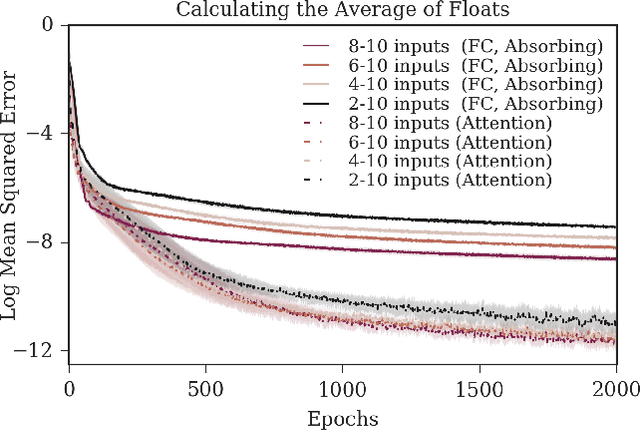
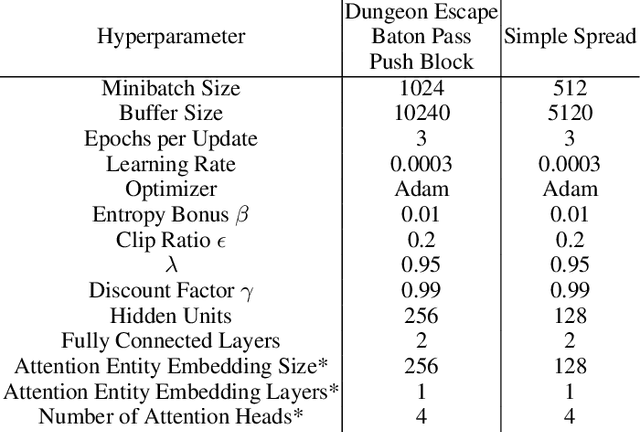

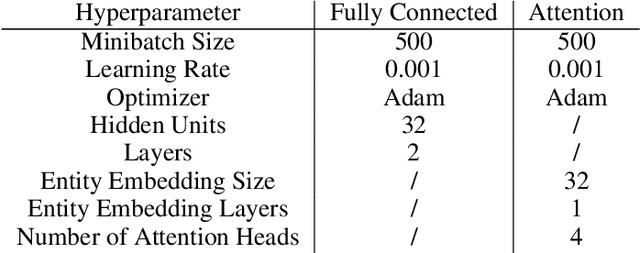
The creation and destruction of agents in cooperative multi-agent reinforcement learning (MARL) is a critically under-explored area of research. Current MARL algorithms often assume that the number of agents within a group remains fixed throughout an experiment. However, in many practical problems, an agent may terminate before their teammates. This early termination issue presents a challenge: the terminated agent must learn from the group's success or failure which occurs beyond its own existence. We refer to propagating value from rewards earned by remaining teammates to terminated agents as the Posthumous Credit Assignment problem. Current MARL methods handle this problem by placing these agents in an absorbing state until the entire group of agents reaches a termination condition. Although absorbing states enable existing algorithms and APIs to handle terminated agents without modification, practical training efficiency and resource use problems exist. In this work, we first demonstrate that sample complexity increases with the quantity of absorbing states in a toy supervised learning task for a fully connected network, while attention is more robust to variable size input. Then, we present a novel architecture for an existing state-of-the-art MARL algorithm which uses attention instead of a fully connected layer with absorbing states. Finally, we demonstrate that this novel architecture significantly outperforms the standard architecture on tasks in which agents are created or destroyed within episodes as well as standard multi-agent coordination tasks.