 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning
Nov 10, 2021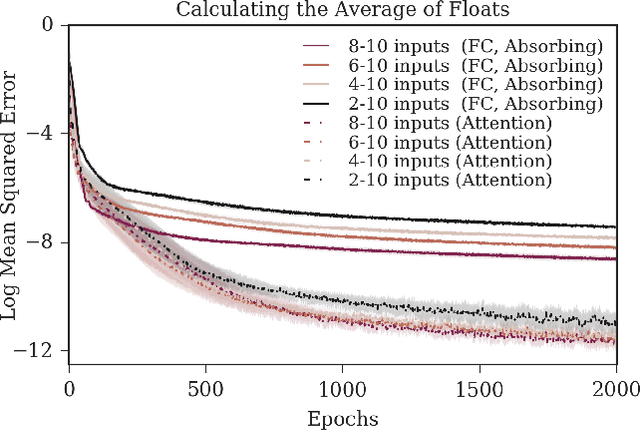
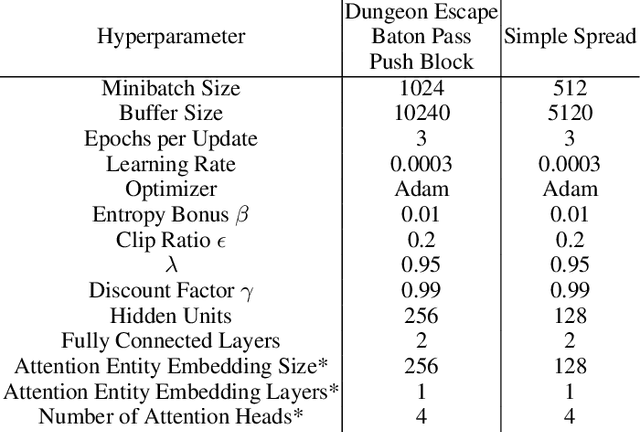

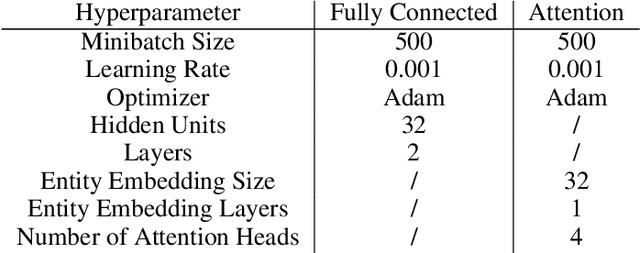
The creation and destruction of agents in cooperative multi-agent reinforcement learning (MARL) is a critically under-explored area of research. Current MARL algorithms often assume that the number of agents within a group remains fixed throughout an experiment. However, in many practical problems, an agent may terminate before their teammates. This early termination issue presents a challenge: the terminated agent must learn from the group's success or failure which occurs beyond its own existence. We refer to propagating value from rewards earned by remaining teammates to terminated agents as the Posthumous Credit Assignment problem. Current MARL methods handle this problem by placing these agents in an absorbing state until the entire group of agents reaches a termination condition. Although absorbing states enable existing algorithms and APIs to handle terminated agents without modification, practical training efficiency and resource use problems exist. In this work, we first demonstrate that sample complexity increases with the quantity of absorbing states in a toy supervised learning task for a fully connected network, while attention is more robust to variable size input. Then, we present a novel architecture for an existing state-of-the-art MARL algorithm which uses attention instead of a fully connected layer with absorbing states. Finally, we demonstrate that this novel architecture significantly outperforms the standard architecture on tasks in which agents are created or destroyed within episodes as well as standard multi-agent coordination tasks.
Autonomous Curiosity for Real-Time Training Onboard Robotic Agents
Aug 29, 2021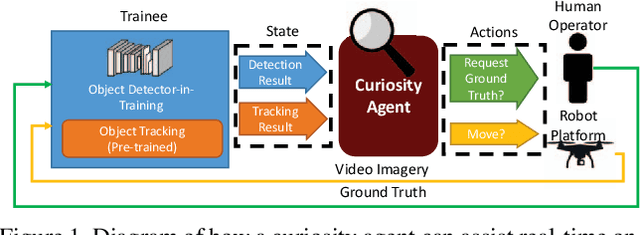
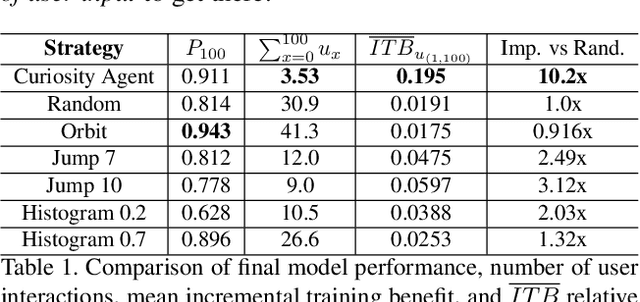
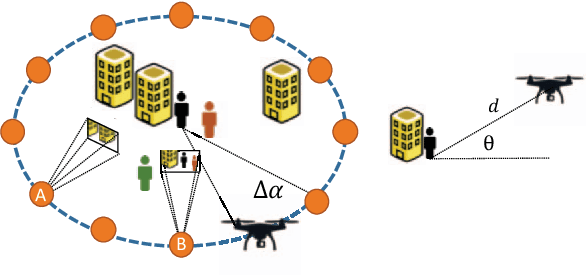
Learning requires both study and curiosity. A good learner is not only good at extracting information from the data given to it, but also skilled at finding the right new information to learn from. This is especially true when a human operator is required to provide the ground truth - such a source should only be queried sparingly. In this work, we address the problem of curiosity as it relates to online, real-time, human-in-the-loop training of an object detection algorithm onboard a robotic platform, one where motion produces new views of the subject. We propose a deep reinforcement learning approach that decides when to ask the human user for ground truth, and when to move. Through a series of experiments, we demonstrate that our agent learns a movement and request policy that is at least 3x more effective at using human user interactions to train an object detector than untrained approaches, and is generalizable to a variety of subjects and environments.
* 10 pages, 9 figures. Accepted in IEEE Winter Conference on Applications of Computer Vision (WACV), 2019. arXiv admin note: text overlap with arXiv:1902.01569
Learning to Learn in Simulation
Feb 05, 2019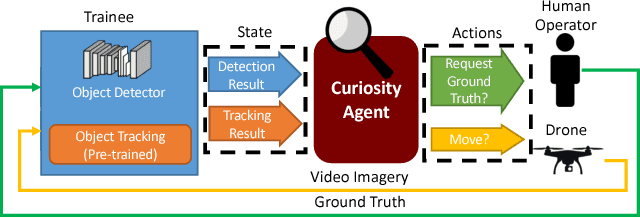
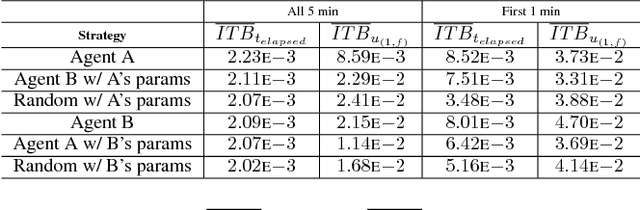
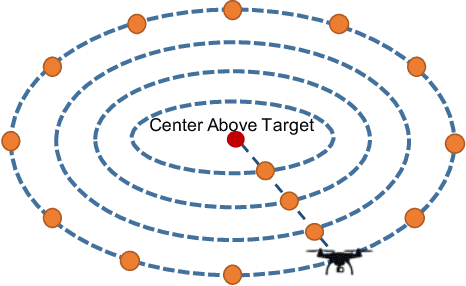
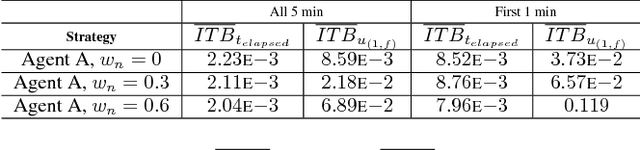
Deep learning often requires the manual collection and annotation of a training set. On robotic platforms, can we partially automate this task by training the robot to be curious, i.e., to seek out beneficial training information in the environment? In this work, we address the problem of curiosity as it relates to online, real-time, human-in-the-loop training of an object detection algorithm onboard a drone, where motion is constrained to two dimensions. We use a 3D simulation environment and deep reinforcement learning to train a curiosity agent to, in turn, train the object detection model. This agent could have one of two conflicting objectives: train as quickly as possible, or train with minimal human input. We outline a reward function that allows the curiosity agent to learn either of these objectives, while taking into account some of the physical characteristics of the drone platform on which it is meant to run. In addition, We show that we can weigh the importance of achieving these objectives by adjusting a parameter in the reward function.
ClickBAIT-v2: Training an Object Detector in Real-Time
Mar 27, 2018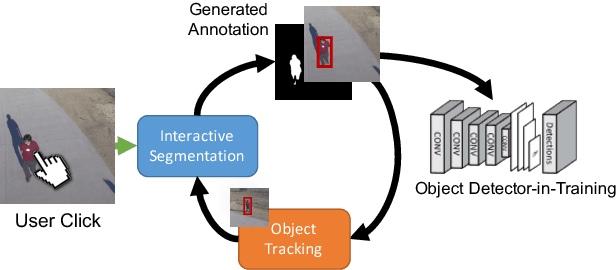


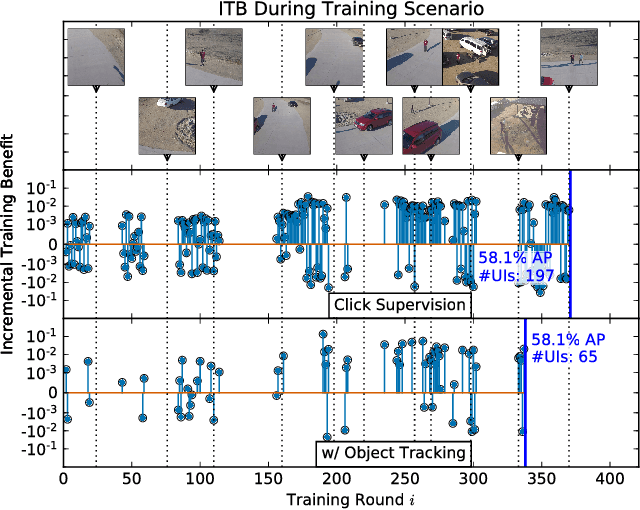
Modern deep convolutional neural networks (CNNs) for image classification and object detection are often trained offline on large static datasets. Some applications, however, will require training in real-time on live video streams with a human-in-the-loop. We refer to this class of problem as time-ordered online training (ToOT). These problems will require a consideration of not only the quantity of incoming training data, but the human effort required to annotate and use it. We demonstrate and evaluate a system tailored to training an object detector on a live video stream with minimal input from a human operator. We show that we can obtain bounding box annotation from weakly-supervised single-point clicks through interactive segmentation. Furthermore, by exploiting the time-ordered nature of the video stream through object tracking, we can increase the average training benefit of human interactions by 3-4 times.
ClickBAIT: Click-based Accelerated Incremental Training of Convolutional Neural Networks
Sep 15, 2017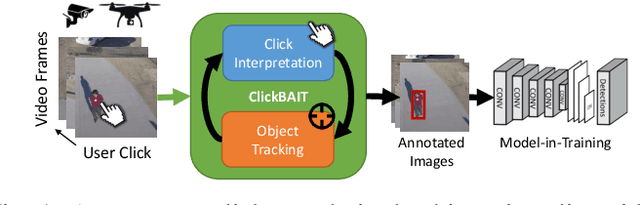
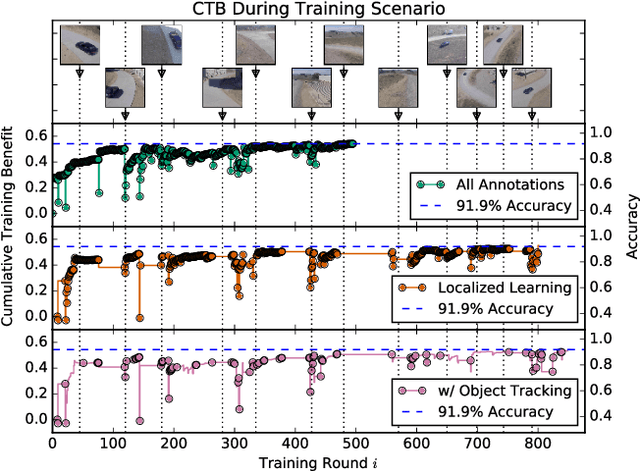
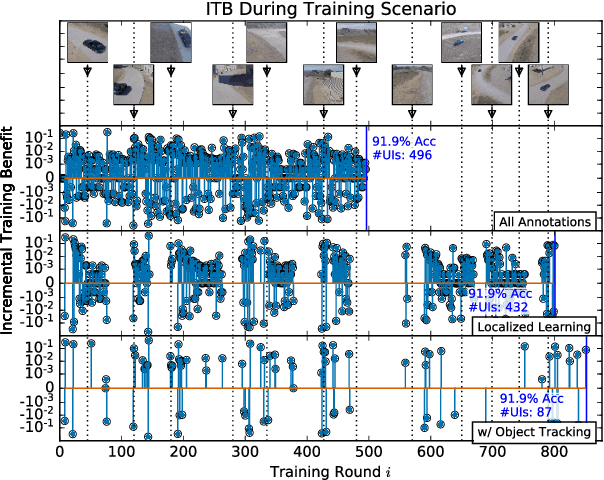
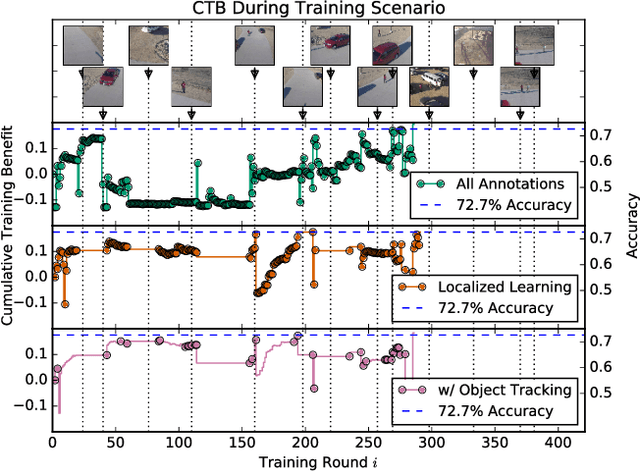
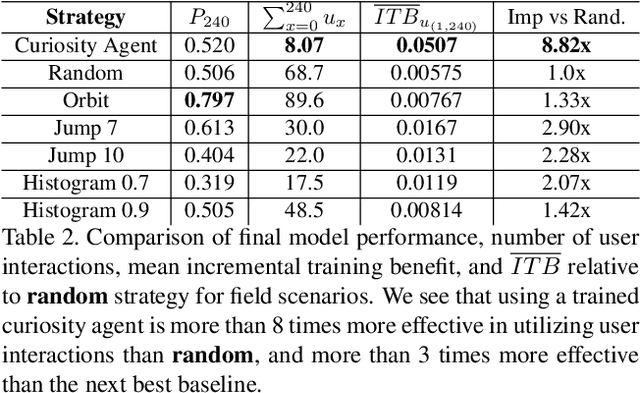
Today's general-purpose deep convolutional neural networks (CNN) for image classification and object detection are trained offline on large static datasets. Some applications, however, will require training in real-time on live video streams with a human-in-the-loop. We refer to this class of problem as Time-ordered Online Training (ToOT) - these problems will require a consideration of not only the quantity of incoming training data, but the human effort required to tag and use it. In this paper, we define training benefit as a metric to measure the effectiveness of a sequence in using each user interaction. We demonstrate and evaluate a system tailored to performing ToOT in the field, capable of training an image classifier on a live video stream through minimal input from a human operator. We show that by exploiting the time-ordered nature of the video stream through optical flow-based object tracking, we can increase the effectiveness of human actions by about 8 times.