 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Curiosity for Real-Time Training Onboard Robotic Agents
Paper and Code
Aug 29, 2021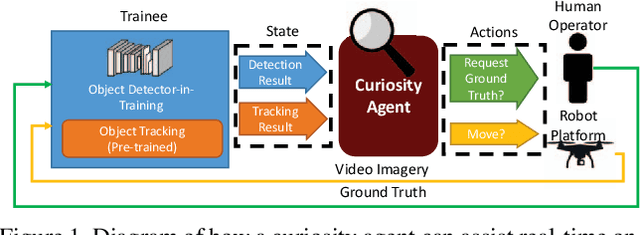
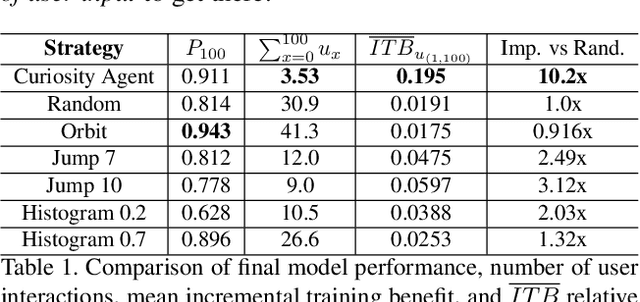
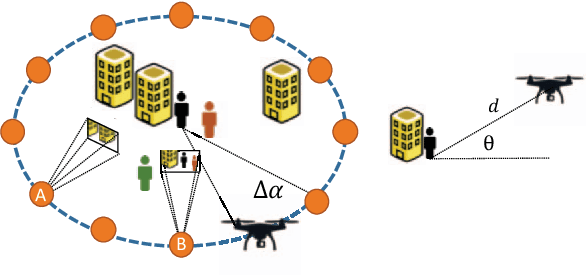
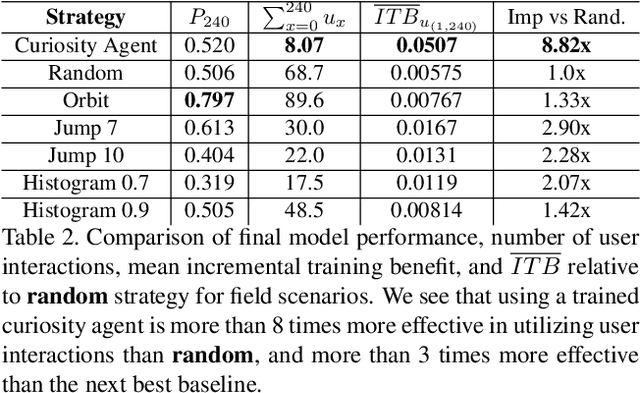
Learning requires both study and curiosity. A good learner is not only good at extracting information from the data given to it, but also skilled at finding the right new information to learn from. This is especially true when a human operator is required to provide the ground truth - such a source should only be queried sparingly. In this work, we address the problem of curiosity as it relates to online, real-time, human-in-the-loop training of an object detection algorithm onboard a robotic platform, one where motion produces new views of the subject. We propose a deep reinforcement learning approach that decides when to ask the human user for ground truth, and when to move. Through a series of experiments, we demonstrate that our agent learns a movement and request policy that is at least 3x more effective at using human user interactions to train an object detector than untrained approaches, and is generalizable to a variety of subjects and environments.