 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTin-Tin: Towards Tiny Learning on Tiny Devices with Integer-based Neural Network Training
Apr 13, 2025Recent advancements in machine learning (ML) have enabled its deployment on resource-constrained edge devices, fostering innovative applications such as intelligent environmental sensing. However, these devices, particularly microcontrollers (MCUs), face substantial challenges due to limited memory, computing capabilities, and the absence of dedicated floating-point units (FPUs). These constraints hinder the deployment of complex ML models, especially those requiring lifelong learning capabilities. To address these challenges, we propose Tin-Tin, an integer-based on-device training framework designed specifically for low-power MCUs. Tin-Tin introduces novel integer rescaling techniques to efficiently manage dynamic ranges and facilitate efficient weight updates using integer data types. Unlike existing methods optimized for devices with FPUs, GPUs, or FPGAs, Tin-Tin addresses the unique demands of tiny MCUs, prioritizing energy efficiency and optimized memory utilization. We validate the effectiveness of Tin-Tin through end-to-end application examples on real-world tiny devices, demonstrating its potential to support energy-efficient and sustainable ML applications on edge platforms.
CoRAST: Towards Foundation Model-Powered Correlated Data Analysis in Resource-Constrained CPS and IoT
Mar 27, 2024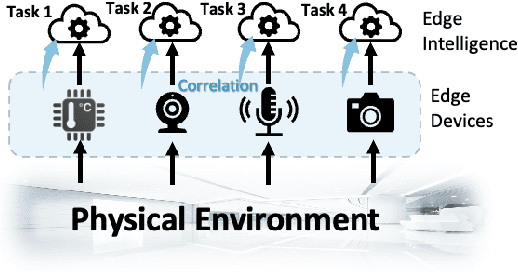
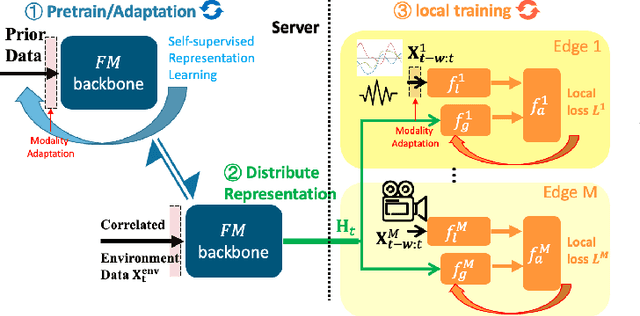
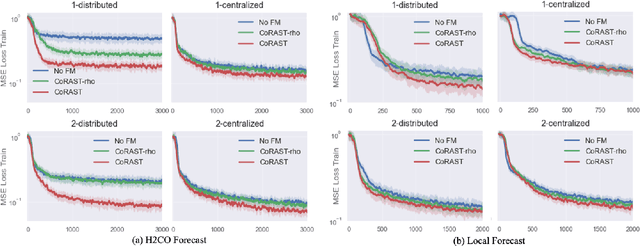
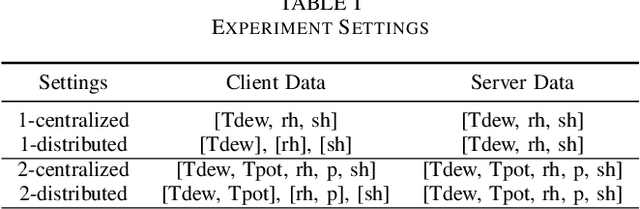
Foundation models (FMs) emerge as a promising solution to harness distributed and diverse environmental data by leveraging prior knowledge to understand the complicated temporal and spatial correlations within heterogeneous datasets. Unlike distributed learning frameworks such as federated learning, which often struggle with multimodal data, FMs can transform diverse inputs into embeddings. This process facilitates the integration of information from various modalities and the application of prior learning to new domains. However, deploying FMs in resource-constrained edge systems poses significant challenges. To this end, we introduce CoRAST, a novel learning framework that utilizes FMs for enhanced analysis of distributed, correlated heterogeneous data. Utilizing a server-based FM, CoRAST can exploit existing environment information to extract temporal, spatial, and cross-modal correlations among sensor data. This enables CoRAST to offer context-aware insights for localized client tasks through FM-powered global representation learning. Our evaluation on real-world weather dataset demonstrates CoRAST's ability to exploit correlated heterogeneous data through environmental representation learning to reduce the forecast errors by up to 50.3% compared to the baselines.
Intelligent Communication Planning for Constrained Environmental IoT Sensing with Reinforcement Learning
Aug 19, 2023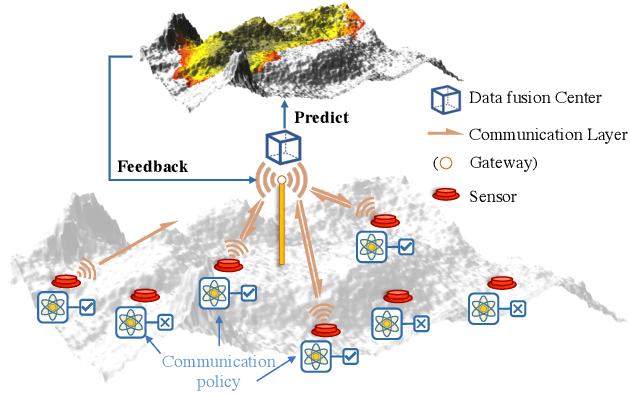
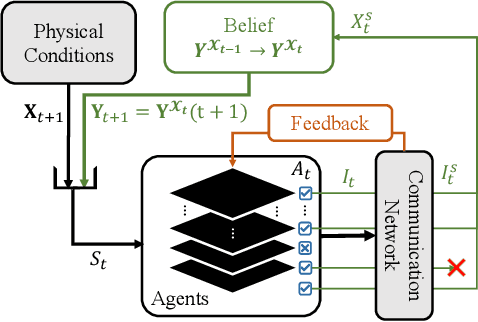
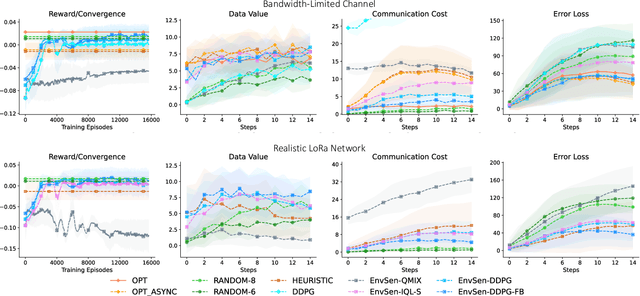
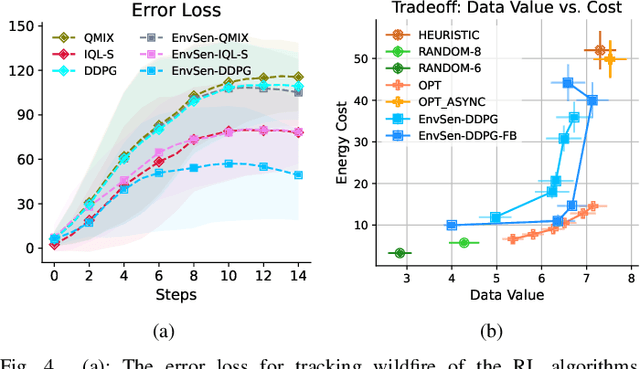
Internet of Things (IoT) technologies have enabled numerous data-driven mobile applications and have the potential to significantly improve environmental monitoring and hazard warnings through the deployment of a network of IoT sensors. However, these IoT devices are often power-constrained and utilize wireless communication schemes with limited bandwidth. Such power constraints limit the amount of information each device can share across the network, while bandwidth limitations hinder sensors' coordination of their transmissions. In this work, we formulate the communication planning problem of IoT sensors that track the state of the environment. We seek to optimize sensors' decisions in collecting environmental data under stringent resource constraints. We propose a multi-agent reinforcement learning (MARL) method to find the optimal communication policies for each sensor that maximize the tracking accuracy subject to the power and bandwidth limitations. MARL learns and exploits the spatial-temporal correlation of the environmental data at each sensor's location to reduce the redundant reports from the sensors. Experiments on wildfire spread with LoRA wireless network simulators show that our MARL method can learn to balance the need to collect enough data to predict wildfire spread with unknown bandwidth limitations.
GiPH: Generalizable Placement Learning for Adaptive Heterogeneous Computing
May 23, 2023Careful placement of a computational application within a target device cluster is critical for achieving low application completion time. The problem is challenging due to its NP-hardness and combinatorial nature. In recent years, learning-based approaches have been proposed to learn a placement policy that can be applied to unseen applications, motivated by the problem of placing a neural network across cloud servers. These approaches, however, generally assume the device cluster is fixed, which is not the case in mobile or edge computing settings, where heterogeneous devices move in and out of range for a particular application. We propose a new learning approach called GiPH, which learns policies that generalize to dynamic device clusters via 1) a novel graph representation gpNet that efficiently encodes the information needed for choosing a good placement, and 2) a scalable graph neural network (GNN) that learns a summary of the gpNet information. GiPH turns the placement problem into that of finding a sequence of placement improvements, learning a policy for selecting this sequence that scales to problems of arbitrary size. We evaluate GiPH with a wide range of task graphs and device clusters and show that our learned policy rapidly find good placements for new problem instances. GiPH finds placements with up to 30.5% lower completion times, searching up to 3X faster than other search-based placement policies.
Autonomous Curiosity for Real-Time Training Onboard Robotic Agents
Aug 29, 2021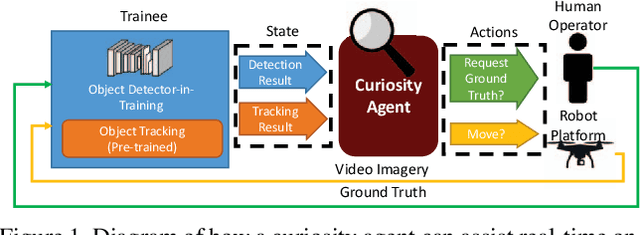
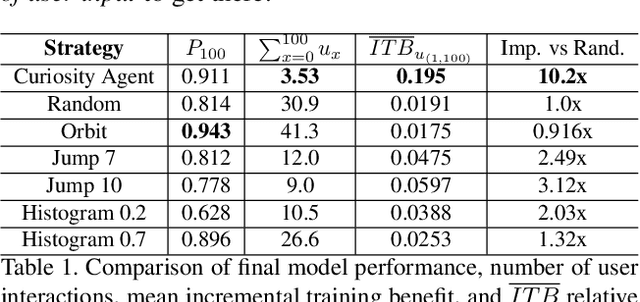
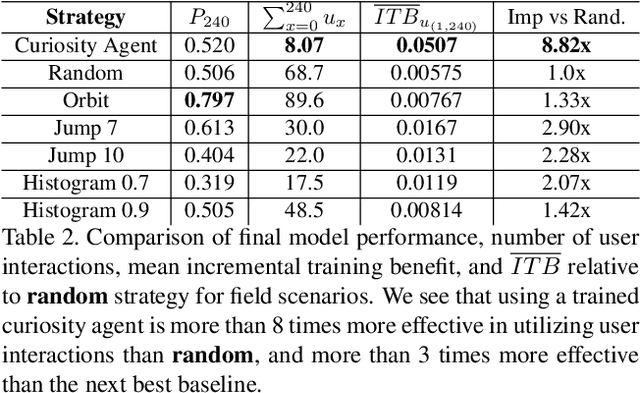
Learning requires both study and curiosity. A good learner is not only good at extracting information from the data given to it, but also skilled at finding the right new information to learn from. This is especially true when a human operator is required to provide the ground truth - such a source should only be queried sparingly. In this work, we address the problem of curiosity as it relates to online, real-time, human-in-the-loop training of an object detection algorithm onboard a robotic platform, one where motion produces new views of the subject. We propose a deep reinforcement learning approach that decides when to ask the human user for ground truth, and when to move. Through a series of experiments, we demonstrate that our agent learns a movement and request policy that is at least 3x more effective at using human user interactions to train an object detector than untrained approaches, and is generalizable to a variety of subjects and environments.
* 10 pages, 9 figures. Accepted in IEEE Winter Conference on Applications of Computer Vision (WACV), 2019. arXiv admin note: text overlap with arXiv:1902.01569
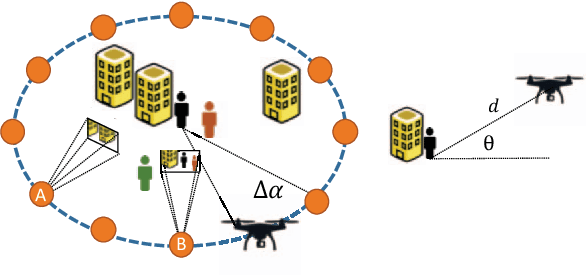
Learning to Learn in Simulation
Feb 05, 2019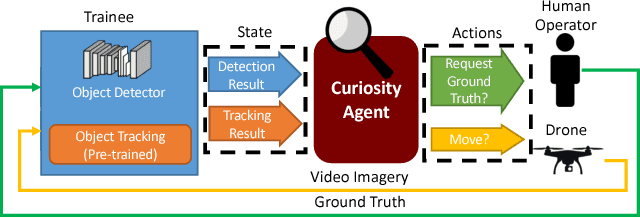
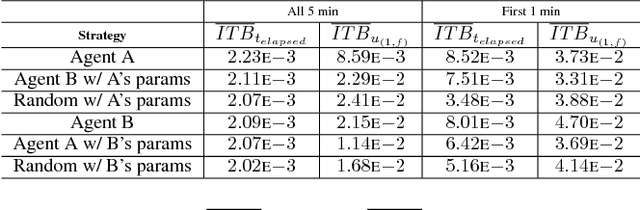
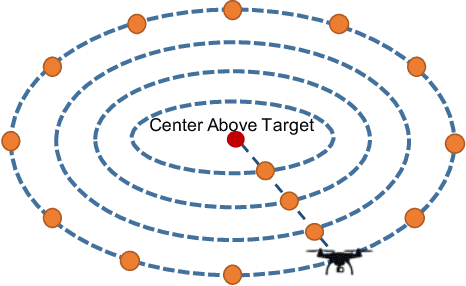
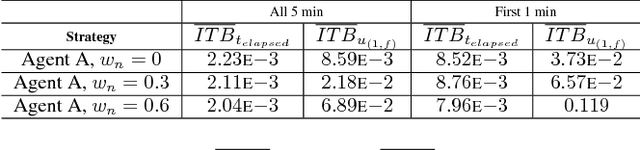
Deep learning often requires the manual collection and annotation of a training set. On robotic platforms, can we partially automate this task by training the robot to be curious, i.e., to seek out beneficial training information in the environment? In this work, we address the problem of curiosity as it relates to online, real-time, human-in-the-loop training of an object detection algorithm onboard a drone, where motion is constrained to two dimensions. We use a 3D simulation environment and deep reinforcement learning to train a curiosity agent to, in turn, train the object detection model. This agent could have one of two conflicting objectives: train as quickly as possible, or train with minimal human input. We outline a reward function that allows the curiosity agent to learn either of these objectives, while taking into account some of the physical characteristics of the drone platform on which it is meant to run. In addition, We show that we can weigh the importance of achieving these objectives by adjusting a parameter in the reward function.
ClickBAIT-v2: Training an Object Detector in Real-Time
Mar 27, 2018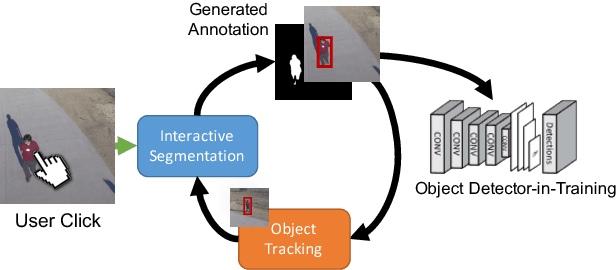


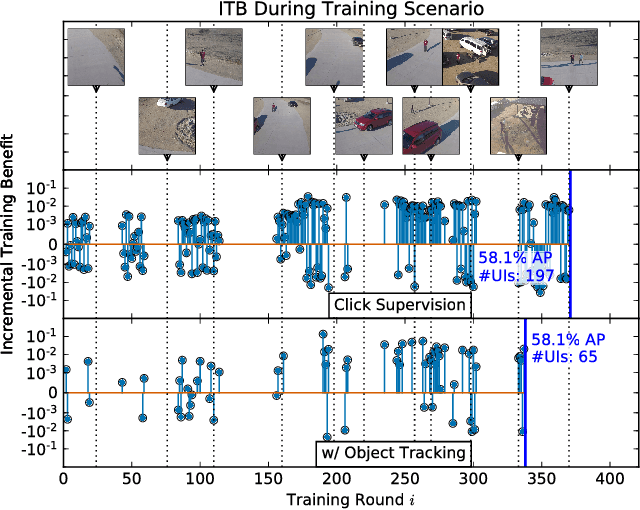
Modern deep convolutional neural networks (CNNs) for image classification and object detection are often trained offline on large static datasets. Some applications, however, will require training in real-time on live video streams with a human-in-the-loop. We refer to this class of problem as time-ordered online training (ToOT). These problems will require a consideration of not only the quantity of incoming training data, but the human effort required to annotate and use it. We demonstrate and evaluate a system tailored to training an object detector on a live video stream with minimal input from a human operator. We show that we can obtain bounding box annotation from weakly-supervised single-point clicks through interactive segmentation. Furthermore, by exploiting the time-ordered nature of the video stream through object tracking, we can increase the average training benefit of human interactions by 3-4 times.
ClickBAIT: Click-based Accelerated Incremental Training of Convolutional Neural Networks
Sep 15, 2017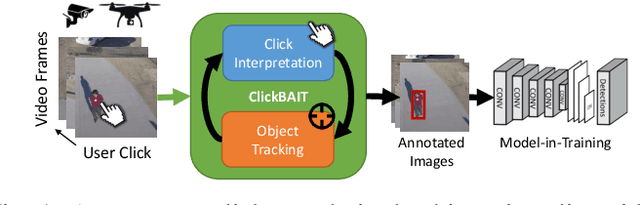
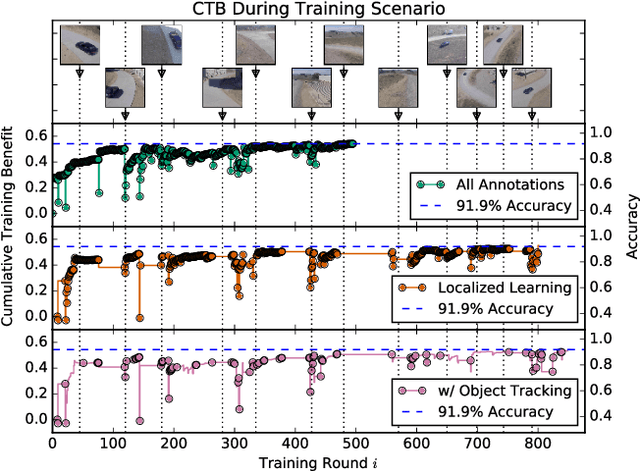
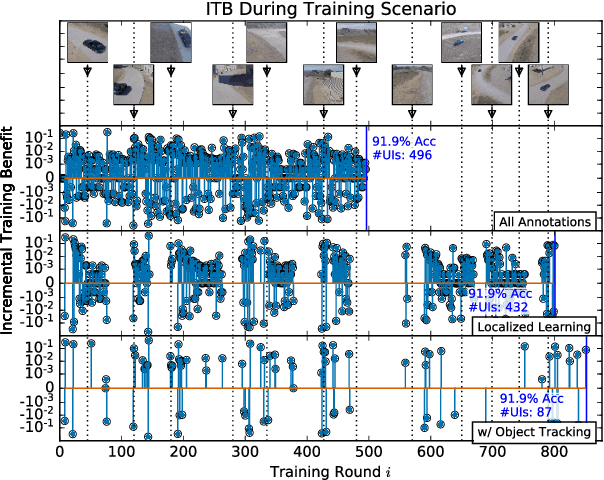
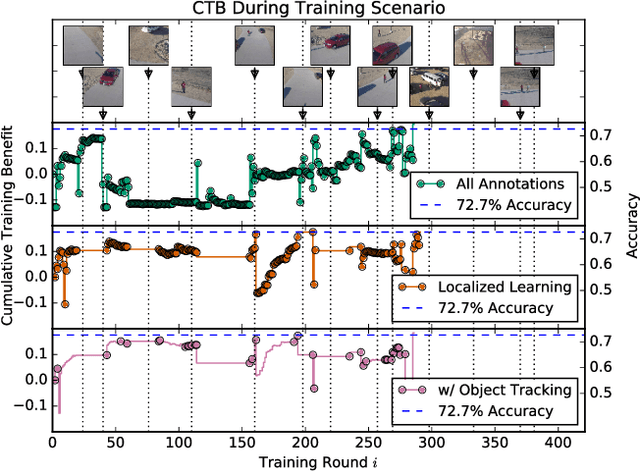
Today's general-purpose deep convolutional neural networks (CNN) for image classification and object detection are trained offline on large static datasets. Some applications, however, will require training in real-time on live video streams with a human-in-the-loop. We refer to this class of problem as Time-ordered Online Training (ToOT) - these problems will require a consideration of not only the quantity of incoming training data, but the human effort required to tag and use it. In this paper, we define training benefit as a metric to measure the effectiveness of a sequence in using each user interaction. We demonstrate and evaluate a system tailored to performing ToOT in the field, capable of training an image classifier on a live video stream through minimal input from a human operator. We show that by exploiting the time-ordered nature of the video stream through optical flow-based object tracking, we can increase the effectiveness of human actions by about 8 times.