 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Use and Misuse of Absorbing States in Multi-agent Reinforcement Learning
Nov 10, 2021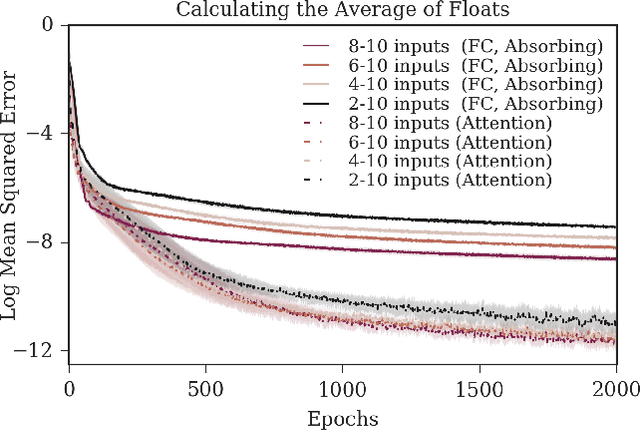
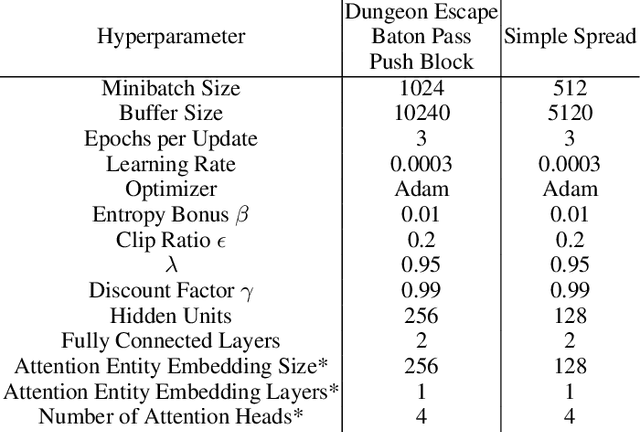

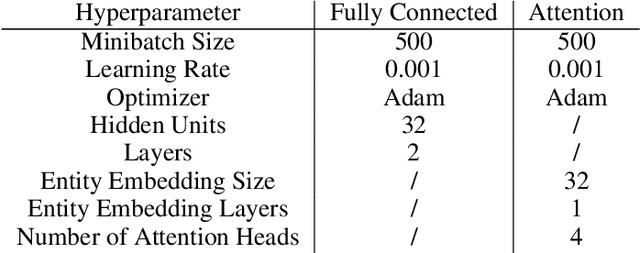
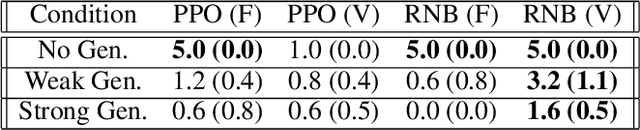
The creation and destruction of agents in cooperative multi-agent reinforcement learning (MARL) is a critically under-explored area of research. Current MARL algorithms often assume that the number of agents within a group remains fixed throughout an experiment. However, in many practical problems, an agent may terminate before their teammates. This early termination issue presents a challenge: the terminated agent must learn from the group's success or failure which occurs beyond its own existence. We refer to propagating value from rewards earned by remaining teammates to terminated agents as the Posthumous Credit Assignment problem. Current MARL methods handle this problem by placing these agents in an absorbing state until the entire group of agents reaches a termination condition. Although absorbing states enable existing algorithms and APIs to handle terminated agents without modification, practical training efficiency and resource use problems exist. In this work, we first demonstrate that sample complexity increases with the quantity of absorbing states in a toy supervised learning task for a fully connected network, while attention is more robust to variable size input. Then, we present a novel architecture for an existing state-of-the-art MARL algorithm which uses attention instead of a fully connected layer with absorbing states. Finally, we demonstrate that this novel architecture significantly outperforms the standard architecture on tasks in which agents are created or destroyed within episodes as well as standard multi-agent coordination tasks.
Obstacle Tower: A Generalization Challenge in Vision, Control, and Planning
Feb 04, 2019
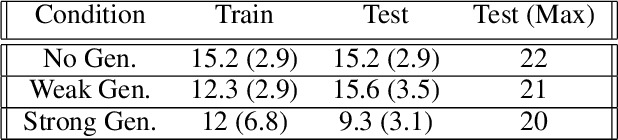

The rapid pace of research in Deep Reinforcement Learning has been driven by the presence of fast and challenging simulation environments. These environments often take the form of games; with tasks ranging from simple board games, to classic home console games, to modern strategy games. We propose a new benchmark called Obstacle Tower: a high visual fidelity, 3D, 3rd person, procedurally generated game environment. An agent in the Obstacle Tower must learn to solve both low-level control and high-level planning problems in tandem while learning from pixels and a sparse reward signal. Unlike other similar benchmarks such as the ALE, evaluation of agent performance in Obstacle Tower is based on an agent's ability to perform well on unseen instances of the environment. In this paper we outline the environment and provide a set of initial baseline results produced by current state-of-the-art Deep RL methods as well as human players. In all cases these algorithms fail to produce agents capable of performing anywhere near human level on a set of evaluations designed to test both memorization and generalization ability. As such, we believe that the Obstacle Tower has the potential to serve as a helpful Deep RL benchmark now and into the future.
Unity: A General Platform for Intelligent Agents
Sep 07, 2018

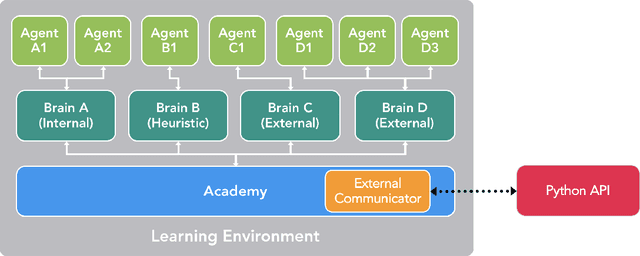
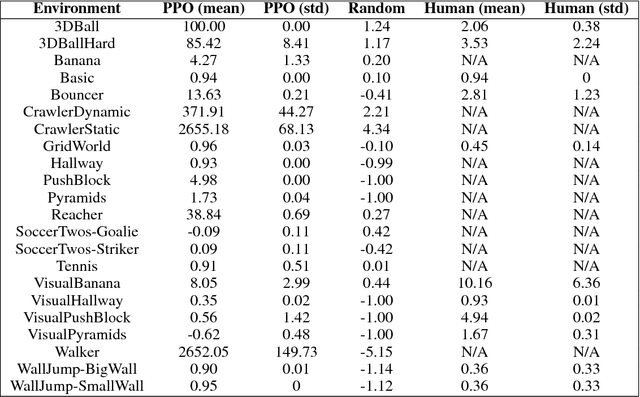
Recent advances in Deep Reinforcement Learning and Robotics have been driven by the presence of increasingly realistic and complex simulation environments. Many of the existing platforms, however, provide either unrealistic visuals, inaccurate physics, low task complexity, or a limited capacity for interaction among artificial agents. Furthermore, many platforms lack the ability to flexibly configure the simulation, hence turning the simulation environment into a black-box from the perspective of the learning system. Here we describe a new open source toolkit for creating and interacting with simulation environments using the Unity platform: Unity ML-Agents Toolkit. By taking advantage of Unity as a simulation platform, the toolkit enables the development of learning environments which are rich in sensory and physical complexity, provide compelling cognitive challenges, and support dynamic multi-agent interaction. We detail the platform design, communication protocol, set of example environments, and variety of training scenarios made possible via the toolkit.