 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Manifold of the Absolute: Religious Perennialism as Generative Inference
Feb 17, 2026This paper formalizes religious epistemology through the mathematics of Variational Autoencoders. We model religious traditions as distinct generative mappings from a shared, low-dimensional latent space to the high-dimensional space of observable cultural forms, and define three competing generative configurations corresponding to exclusivism, universalism, and perennialism, alongside syncretism as direct mixing in observable space. Through abductive comparison, we argue that exclusivism cannot parsimoniously account for cross-traditional contemplative convergence, that syncretism fails because combining the outputs of distinct generative processes produces incoherent artifacts, and that universalism suffers from posterior collapse: stripping traditions to a common core discards the structural information necessary for inference. The perennialist configuration provides the best explanatory fit. Within this framework, strict orthodoxy emerges not as a cultural constraint but as a structural necessity: the contemplative practices that recover the latent source must be matched to the specific tradition whose forms they take as input. The unity of religions, if it exists, is real but inaccessible by shortcut: one must go deep rather than wide.
The Contingencies of Physical Embodiment Allow for Open-Endedness and Care
Oct 08, 2025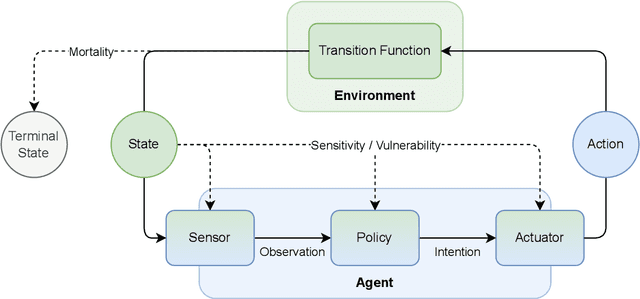
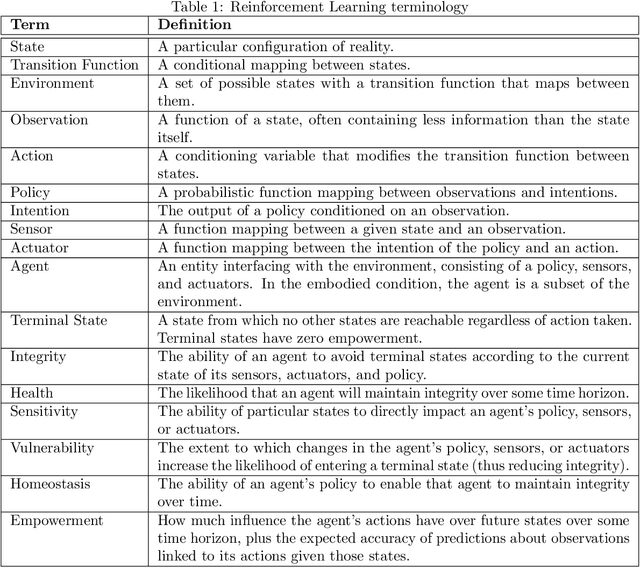
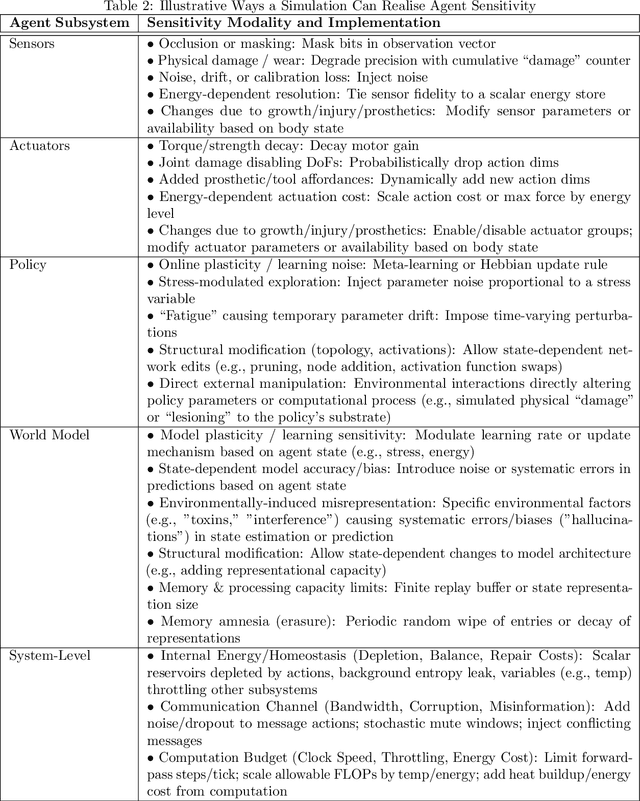
Physical vulnerability and mortality are often seen as obstacles to be avoided in the development of artificial agents, which struggle to adapt to open-ended environments and provide aligned care. Meanwhile, biological organisms survive, thrive, and care for each other in an open-ended physical world with relative ease and efficiency. Understanding the role of the conditions of life in this disparity can aid in developing more robust, adaptive, and caring artificial agents. Here we define two minimal conditions for physical embodiment inspired by the existentialist phenomenology of Martin Heidegger: being-in-the-world (the agent is a part of the environment) and being-towards-death (unless counteracted, the agent drifts toward terminal states due to the second law of thermodynamics). We propose that from these conditions we can obtain both a homeostatic drive - aimed at maintaining integrity and avoiding death by expending energy to learn and act - and an intrinsic drive to continue to do so in as many ways as possible. Drawing inspiration from Friedrich Nietzsche's existentialist concept of will-to-power, we examine how intrinsic drives to maximize control over future states, e.g., empowerment, allow agents to increase the probability that they will be able to meet their future homeostatic needs, thereby enhancing their capacity to maintain physical integrity. We formalize these concepts within a reinforcement learning framework, which enables us to examine how intrinsically driven embodied agents learning in open-ended multi-agent environments may cultivate the capacities for open-endedness and care.ov
A Study of Plasticity Loss in On-Policy Deep Reinforcement Learning
May 29, 2024Continual learning with deep neural networks presents challenges distinct from both the fixed-dataset and convex continual learning regimes. One such challenge is plasticity loss, wherein a neural network trained in an online fashion displays a degraded ability to fit new tasks. This problem has been extensively studied in both supervised learning and off-policy reinforcement learning (RL), where a number of remedies have been proposed. Still, plasticity loss has received less attention in the on-policy deep RL setting. Here we perform an extensive set of experiments examining plasticity loss and a variety of mitigation methods in on-policy deep RL. We demonstrate that plasticity loss is pervasive under domain shift in this regime, and that a number of methods developed to resolve it in other settings fail, sometimes even resulting in performance that is worse than performing no intervention at all. In contrast, we find that a class of ``regenerative'' methods are able to consistently mitigate plasticity loss in a variety of contexts, including in gridworld tasks and more challenging environments like Montezuma's Revenge and ProcGen.
Navigates Like Me: Understanding How People Evaluate Human-Like AI in Video Games
Mar 02, 2023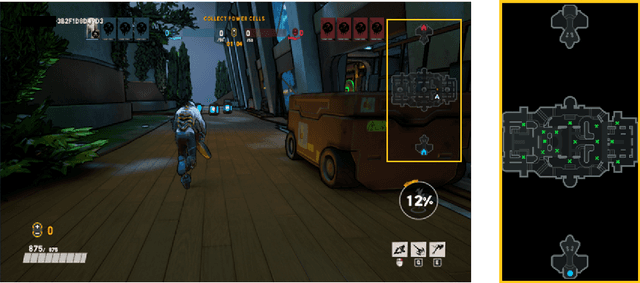
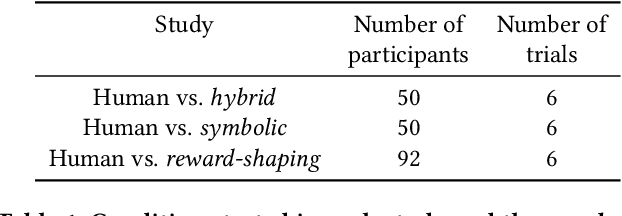

We aim to understand how people assess human likeness in navigation produced by people and artificially intelligent (AI) agents in a video game. To this end, we propose a novel AI agent with the goal of generating more human-like behavior. We collect hundreds of crowd-sourced assessments comparing the human-likeness of navigation behavior generated by our agent and baseline AI agents with human-generated behavior. Our proposed agent passes a Turing Test, while the baseline agents do not. By passing a Turing Test, we mean that human judges could not quantitatively distinguish between videos of a person and an AI agent navigating. To understand what people believe constitutes human-like navigation, we extensively analyze the justifications of these assessments. This work provides insights into the characteristics that people consider human-like in the context of goal-directed video game navigation, which is a key step for further improving human interactions with AI agents.
A Biologically-Inspired Dual Stream World Model
Sep 16, 2022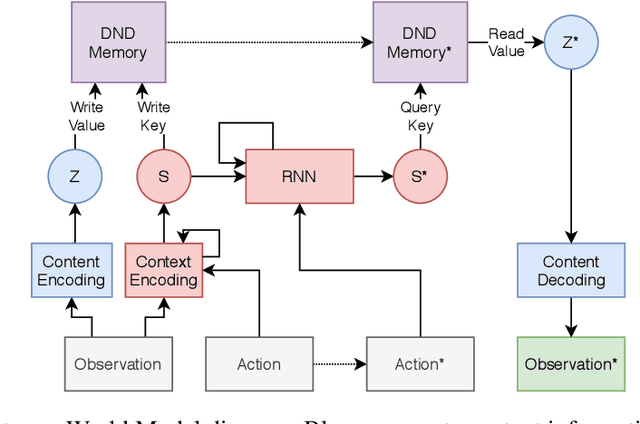
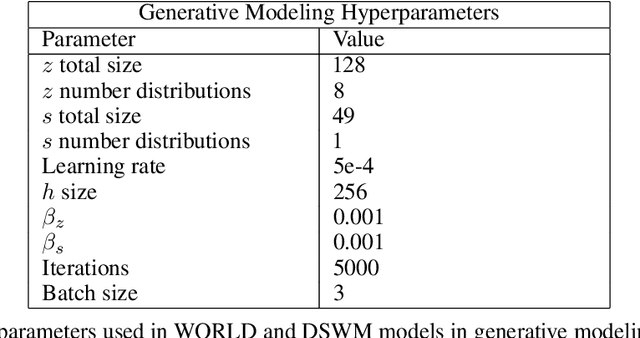
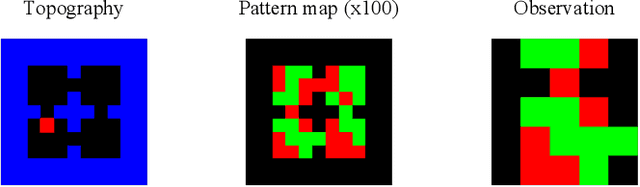
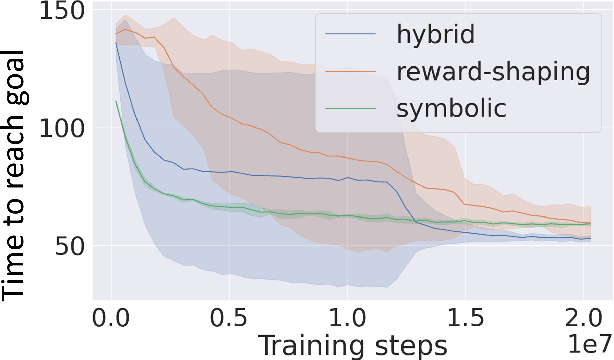
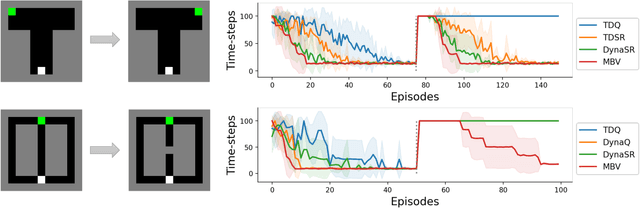
The medial temporal lobe (MTL), a brain region containing the hippocampus and nearby areas, is hypothesized to be an experience-construction system in mammals, supporting both recall and imagination of temporally-extended sequences of events. Such capabilities are also core to many recently proposed ``world models" in the field of AI research. Taking inspiration from this connection, we propose a novel variant, the Dual Stream World Model (DSWM), which learns from high-dimensional observations and dissociates them into context and content streams. DSWM can reliably generate imagined trajectories in novel 2D environments after only a single exposure, outperforming a standard world model. DSWM also learns latent representations which bear a strong resemblance to place cells found in the hippocampus. We show that this representation is useful as a reinforcement learning basis function, and that the generative model can be used to aid the policy learning process using Dyna-like updates.
Neuro-Nav: A Library for Neurally-Plausible Reinforcement Learning
Jun 06, 2022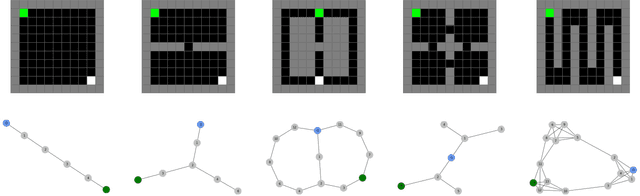


In this work we propose Neuro-Nav, an open-source library for neurally plausible reinforcement learning (RL). RL is among the most common modeling frameworks for studying decision making, learning, and navigation in biological organisms. In utilizing RL, cognitive scientists often handcraft environments and agents to meet the needs of their particular studies. On the other hand, artificial intelligence researchers often struggle to find benchmarks for neurally and biologically plausible representation and behavior (e.g., in decision making or navigation). In order to streamline this process across both fields with transparency and reproducibility, Neuro-Nav offers a set of standardized environments and RL algorithms drawn from canonical behavioral and neural studies in rodents and humans. We demonstrate that the toolkit replicates relevant findings from a number of studies across both cognitive science and RL literatures. We furthermore describe ways in which the library can be extended with novel algorithms (including deep RL) and environments to address future research needs of the field.
On the link between conscious function and general intelligence in humans and machines
Mar 24, 2022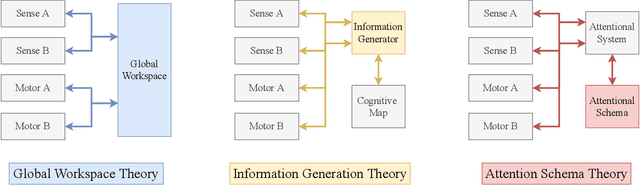
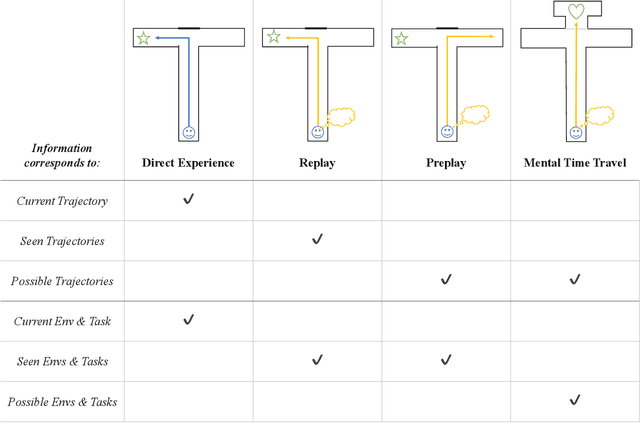
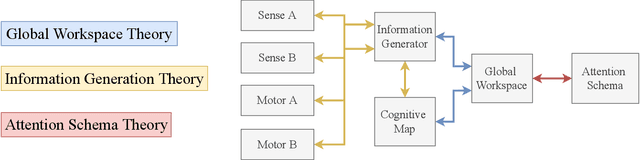
In popular media, there is often a connection drawn between the advent of awareness in artificial agents and those same agents simultaneously achieving human or superhuman level intelligence. In this work, we explore the validity and potential application of this seemingly intuitive link between consciousness and intelligence. We do so by examining the cognitive abilities associated with three contemporary theories of conscious function: Global Workspace Theory (GWT), Information Generation Theory (IGT), and Attention Schema Theory (AST). We find that all three theories specifically relate conscious function to some aspect of domain-general intelligence in humans. With this insight, we turn to the field of Artificial Intelligence (AI) and find that, while still far from demonstrating general intelligence, many state-of-the-art deep learning methods have begun to incorporate key aspects of each of the three functional theories. Given this apparent trend, we use the motivating example of mental time travel in humans to propose ways in which insights from each of the three theories may be combined into a unified model. We believe that doing so can enable the development of artificial agents which are not only more generally intelligent but are also consistent with multiple current theories of conscious function.
Obstacle Tower: A Generalization Challenge in Vision, Control, and Planning
Feb 04, 2019

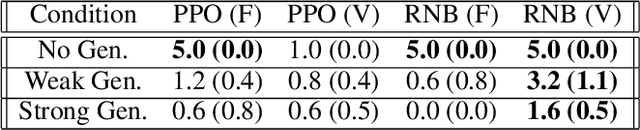
The rapid pace of research in Deep Reinforcement Learning has been driven by the presence of fast and challenging simulation environments. These environments often take the form of games; with tasks ranging from simple board games, to classic home console games, to modern strategy games. We propose a new benchmark called Obstacle Tower: a high visual fidelity, 3D, 3rd person, procedurally generated game environment. An agent in the Obstacle Tower must learn to solve both low-level control and high-level planning problems in tandem while learning from pixels and a sparse reward signal. Unlike other similar benchmarks such as the ALE, evaluation of agent performance in Obstacle Tower is based on an agent's ability to perform well on unseen instances of the environment. In this paper we outline the environment and provide a set of initial baseline results produced by current state-of-the-art Deep RL methods as well as human players. In all cases these algorithms fail to produce agents capable of performing anywhere near human level on a set of evaluations designed to test both memorization and generalization ability. As such, we believe that the Obstacle Tower has the potential to serve as a helpful Deep RL benchmark now and into the future.
Unity: A General Platform for Intelligent Agents
Sep 07, 2018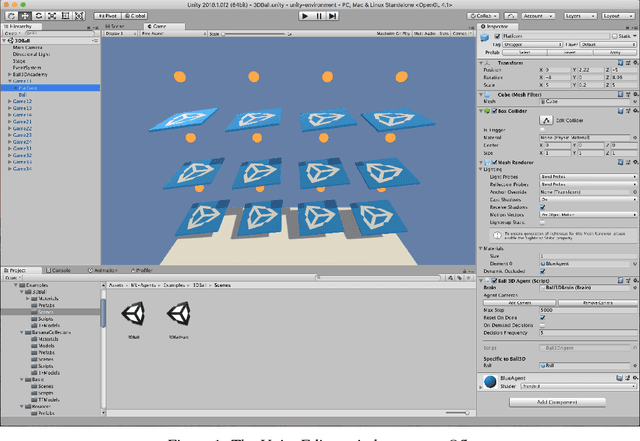

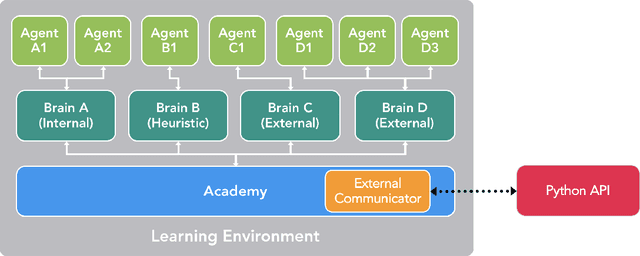
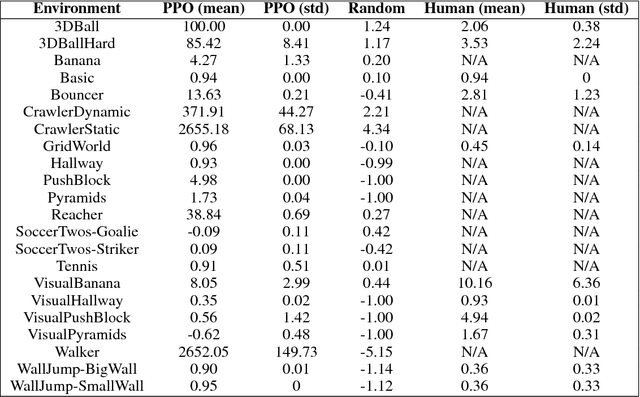
Recent advances in Deep Reinforcement Learning and Robotics have been driven by the presence of increasingly realistic and complex simulation environments. Many of the existing platforms, however, provide either unrealistic visuals, inaccurate physics, low task complexity, or a limited capacity for interaction among artificial agents. Furthermore, many platforms lack the ability to flexibly configure the simulation, hence turning the simulation environment into a black-box from the perspective of the learning system. Here we describe a new open source toolkit for creating and interacting with simulation environments using the Unity platform: Unity ML-Agents Toolkit. By taking advantage of Unity as a simulation platform, the toolkit enables the development of learning environments which are rich in sensory and physical complexity, provide compelling cognitive challenges, and support dynamic multi-agent interaction. We detail the platform design, communication protocol, set of example environments, and variety of training scenarios made possible via the toolkit.