 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting a World Model for Trajectory Following in a 3D Game
Apr 16, 2025



Imitation learning is a powerful tool for training agents by leveraging expert knowledge, and being able to replicate a given trajectory is an integral part of it. In complex environments, like modern 3D video games, distribution shift and stochasticity necessitate robust approaches beyond simple action replay. In this study, we apply Inverse Dynamics Models (IDM) with different encoders and policy heads to trajectory following in a modern 3D video game -- Bleeding Edge. Additionally, we investigate several future alignment strategies that address the distribution shift caused by the aleatoric uncertainty and imperfections of the agent. We measure both the trajectory deviation distance and the first significant deviation point between the reference and the agent's trajectory and show that the optimal configuration depends on the chosen setting. Our results show that in a diverse data setting, a GPT-style policy head with an encoder trained from scratch performs the best, DINOv2 encoder with the GPT-style policy head gives the best results in the low data regime, and both GPT-style and MLP-style policy heads had comparable results when pre-trained on a diverse setting and fine-tuned for a specific behaviour setting.
Scaling Laws for Pre-training Agents and World Models
Nov 07, 2024



The performance of embodied agents has been shown to improve by increasing model parameters, dataset size, and compute. This has been demonstrated in domains from robotics to video games, when generative learning objectives on offline datasets (pre-training) are used to model an agent's behavior (imitation learning) or their environment (world modeling). This paper characterizes the role of scale in these tasks more precisely. Going beyond the simple intuition that `bigger is better', we show that the same types of power laws found in language modeling (e.g. between loss and optimal model size), also arise in world modeling and imitation learning. However, the coefficients of these laws are heavily influenced by the tokenizer, task \& architecture -- this has important implications on the optimal sizing of models and data.
Visual Encoders for Data-Efficient Imitation Learning in Modern Video Games
Dec 04, 2023Video games have served as useful benchmarks for the decision making community, but going beyond Atari games towards training agents in modern games has been prohibitively expensive for the vast majority of the research community. Recent progress in the research, development and open release of large vision models has the potential to amortize some of these costs across the community. However, it is currently unclear which of these models have learnt representations that retain information critical for sequential decision making. Towards enabling wider participation in the research of gameplaying agents in modern games, we present a systematic study of imitation learning with publicly available visual encoders compared to the typical, task-specific, end-to-end training approach in Minecraft, Minecraft Dungeons and Counter-Strike: Global Offensive.
Navigates Like Me: Understanding How People Evaluate Human-Like AI in Video Games
Mar 02, 2023

We aim to understand how people assess human likeness in navigation produced by people and artificially intelligent (AI) agents in a video game. To this end, we propose a novel AI agent with the goal of generating more human-like behavior. We collect hundreds of crowd-sourced assessments comparing the human-likeness of navigation behavior generated by our agent and baseline AI agents with human-generated behavior. Our proposed agent passes a Turing Test, while the baseline agents do not. By passing a Turing Test, we mean that human judges could not quantitatively distinguish between videos of a person and an AI agent navigating. To understand what people believe constitutes human-like navigation, we extensively analyze the justifications of these assessments. This work provides insights into the characteristics that people consider human-like in the context of goal-directed video game navigation, which is a key step for further improving human interactions with AI agents.
Imitating Human Behaviour with Diffusion Models
Jan 25, 2023



Diffusion models have emerged as powerful generative models in the text-to-image domain. This paper studies their application as observation-to-action models for imitating human behaviour in sequential environments. Human behaviour is stochastic and multimodal, with structured correlations between action dimensions. Meanwhile, standard modelling choices in behaviour cloning are limited in their expressiveness and may introduce bias into the cloned policy. We begin by pointing out the limitations of these choices. We then propose that diffusion models are an excellent fit for imitating human behaviour, since they learn an expressive distribution over the joint action space. We introduce several innovations to make diffusion models suitable for sequential environments; designing suitable architectures, investigating the role of guidance, and developing reliable sampling strategies. Experimentally, diffusion models closely match human demonstrations in a simulated robotic control task and a modern 3D gaming environment.
* Published in ICLR 2023
UniMASK: Unified Inference in Sequential Decision Problems
Nov 20, 2022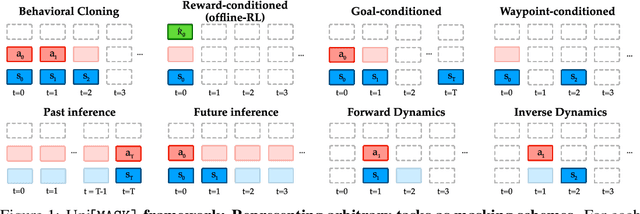
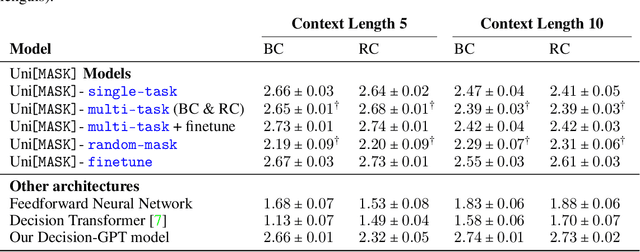
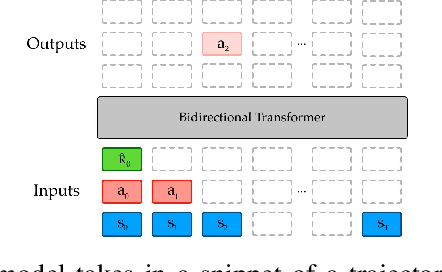
Randomly masking and predicting word tokens has been a successful approach in pre-training language models for a variety of downstream tasks. In this work, we observe that the same idea also applies naturally to sequential decision-making, where many well-studied tasks like behavior cloning, offline reinforcement learning, inverse dynamics, and waypoint conditioning correspond to different sequence maskings over a sequence of states, actions, and returns. We introduce the UniMASK framework, which provides a unified way to specify models which can be trained on many different sequential decision-making tasks. We show that a single UniMASK model is often capable of carrying out many tasks with performance similar to or better than single-task models. Additionally, after fine-tuning, our UniMASK models consistently outperform comparable single-task models. Our code is publicly available at https://github.com/micahcarroll/uniMASK.
Go-Explore Complex 3D Game Environments for Automated Reachability Testing
Sep 01, 2022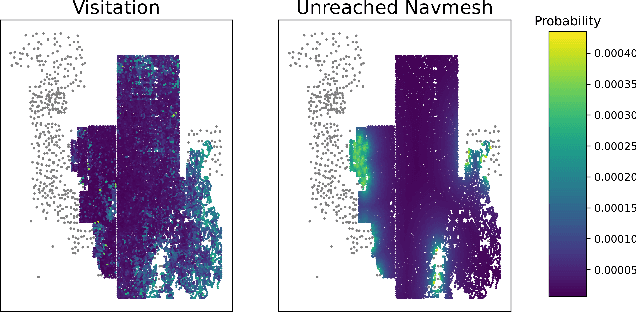
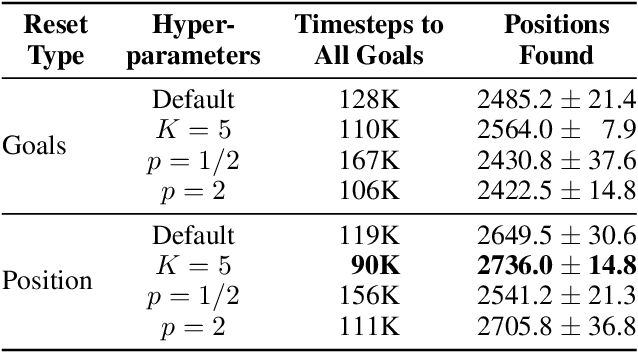

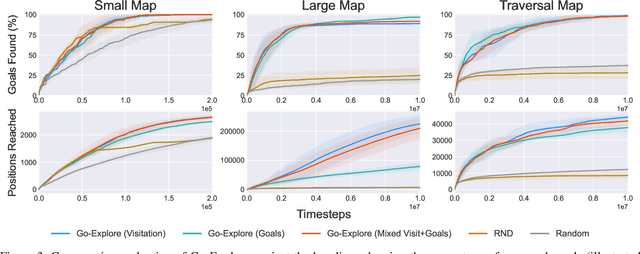
Modern AAA video games feature huge game levels and maps which are increasingly hard for level testers to cover exhaustively. As a result, games often ship with catastrophic bugs such as the player falling through the floor or being stuck in walls. We propose an approach specifically targeted at reachability bugs in simulated 3D environments based on the powerful exploration algorithm, Go-Explore, which saves unique checkpoints across the map and then identifies promising ones to explore from. We show that when coupled with simple heuristics derived from the game's navigation mesh, Go-Explore finds challenging bugs and comprehensively explores complex environments without the need for human demonstration or knowledge of the game dynamics. Go-Explore vastly outperforms more complicated baselines including reinforcement learning with intrinsic curiosity in both covering the navigation mesh and number of unique positions across the map discovered. Finally, due to our use of parallel agents, our algorithm can fully cover a vast 1.5km x 1.5km game world within 10 hours on a single machine making it extremely promising for continuous testing suites.
Towards Flexible Inference in Sequential Decision Problems via Bidirectional Transformers
Apr 28, 2022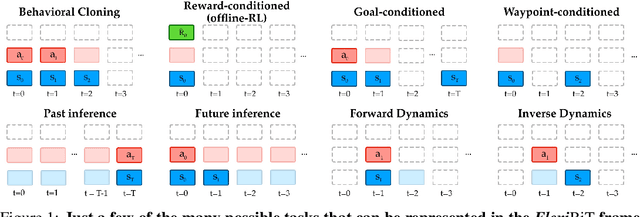
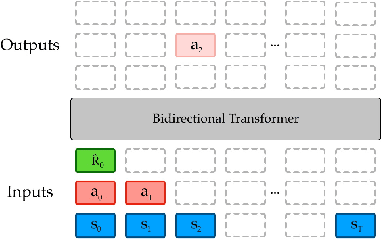
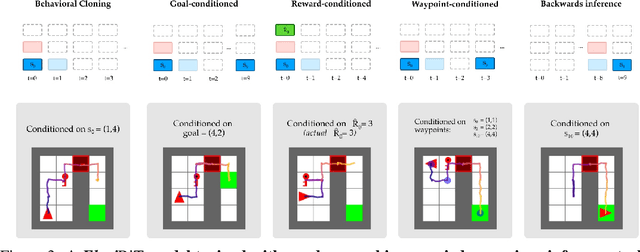
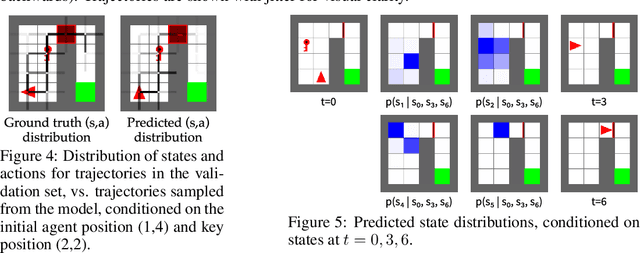
Randomly masking and predicting word tokens has been a successful approach in pre-training language models for a variety of downstream tasks. In this work, we observe that the same idea also applies naturally to sequential decision making, where many well-studied tasks like behavior cloning, offline RL, inverse dynamics, and waypoint conditioning correspond to different sequence maskings over a sequence of states, actions, and returns. We introduce the FlexiBiT framework, which provides a unified way to specify models which can be trained on many different sequential decision making tasks. We show that a single FlexiBiT model is simultaneously capable of carrying out many tasks with performance similar to or better than specialized models. Additionally, we show that performance can be further improved by fine-tuning our general model on specific tasks of interest.
Navigation Turing Test (NTT): Learning to Evaluate Human-Like Navigation
May 20, 2021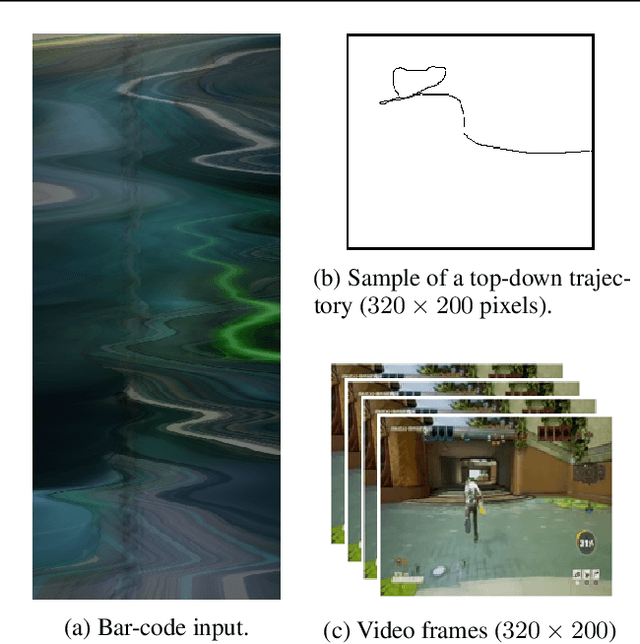
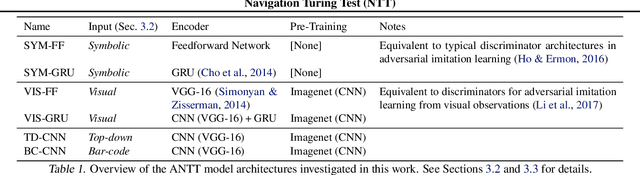
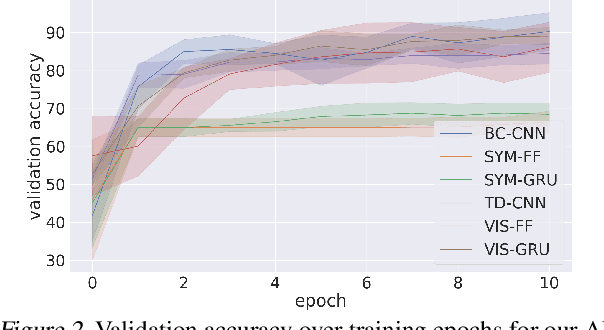
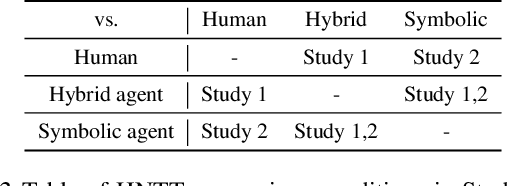
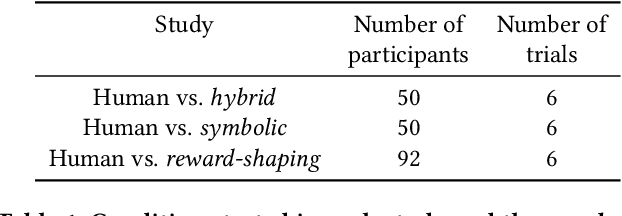
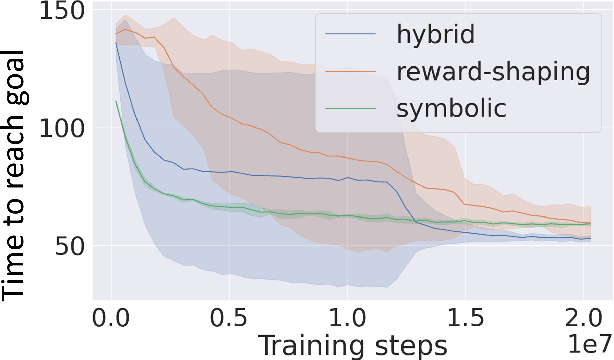
A key challenge on the path to developing agents that learn complex human-like behavior is the need to quickly and accurately quantify human-likeness. While human assessments of such behavior can be highly accurate, speed and scalability are limited. We address these limitations through a novel automated Navigation Turing Test (ANTT) that learns to predict human judgments of human-likeness. We demonstrate the effectiveness of our automated NTT on a navigation task in a complex 3D environment. We investigate six classification models to shed light on the types of architectures best suited to this task, and validate them against data collected through a human NTT. Our best models achieve high accuracy when distinguishing true human and agent behavior. At the same time, we show that predicting finer-grained human assessment of agents' progress towards human-like behavior remains unsolved. Our work takes an important step towards agents that more effectively learn complex human-like behavior.