 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: We Need An Algorithmic Understanding of Generative AI
Jul 10, 2025
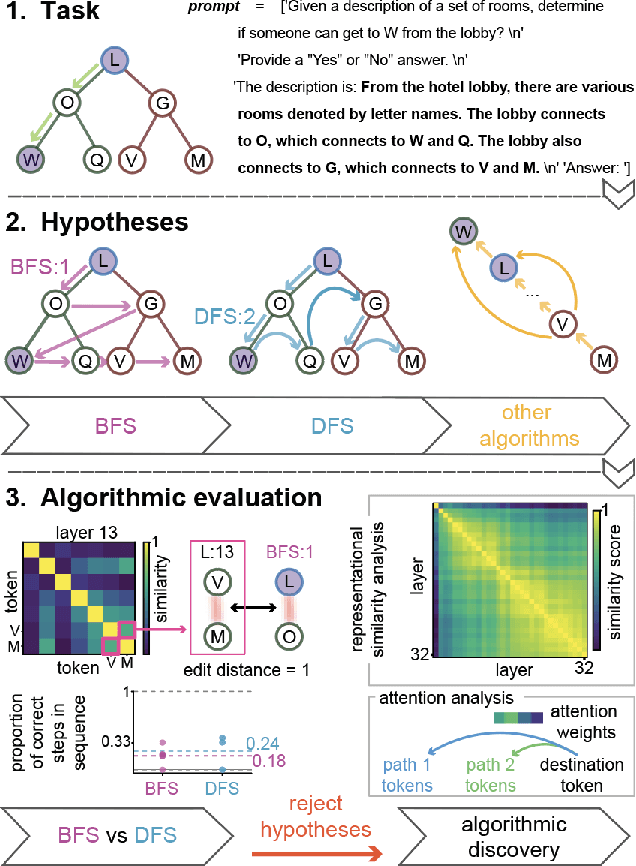


What algorithms do LLMs actually learn and use to solve problems? Studies addressing this question are sparse, as research priorities are focused on improving performance through scale, leaving a theoretical and empirical gap in understanding emergent algorithms. This position paper proposes AlgEval: a framework for systematic research into the algorithms that LLMs learn and use. AlgEval aims to uncover algorithmic primitives, reflected in latent representations, attention, and inference-time compute, and their algorithmic composition to solve task-specific problems. We highlight potential methodological paths and a case study toward this goal, focusing on emergent search algorithms. Our case study illustrates both the formation of top-down hypotheses about candidate algorithms, and bottom-up tests of these hypotheses via circuit-level analysis of attention patterns and hidden states. The rigorous, systematic evaluation of how LLMs actually solve tasks provides an alternative to resource-intensive scaling, reorienting the field toward a principled understanding of underlying computations. Such algorithmic explanations offer a pathway to human-understandable interpretability, enabling comprehension of the model's internal reasoning performance measures. This can in turn lead to more sample-efficient methods for training and improving performance, as well as novel architectures for end-to-end and multi-agent systems.
Evaluating Compositional Scene Understanding in Multimodal Generative Models
Mar 29, 2025



The visual world is fundamentally compositional. Visual scenes are defined by the composition of objects and their relations. Hence, it is essential for computer vision systems to reflect and exploit this compositionality to achieve robust and generalizable scene understanding. While major strides have been made toward the development of general-purpose, multimodal generative models, including both text-to-image models and multimodal vision-language models, it remains unclear whether these systems are capable of accurately generating and interpreting scenes involving the composition of multiple objects and relations. In this work, we present an evaluation of the compositional visual processing capabilities in the current generation of text-to-image (DALL-E 3) and multimodal vision-language models (GPT-4V, GPT-4o, Claude Sonnet 3.5, QWEN2-VL-72B, and InternVL2.5-38B), and compare the performance of these systems to human participants. The results suggest that these systems display some ability to solve compositional and relational tasks, showing notable improvements over the previous generation of multimodal models, but with performance nevertheless well below the level of human participants, particularly for more complex scenes involving many ($>5$) objects and multiple relations. These results highlight the need for further progress toward compositional understanding of visual scenes.
Collective Innovation in Groups of Large Language Models
Jul 07, 2024



Human culture relies on collective innovation: our ability to continuously explore how existing elements in our environment can be combined to create new ones. Language is hypothesized to play a key role in human culture, driving individual cognitive capacities and shaping communication. Yet the majority of models of collective innovation assign no cognitive capacities or language abilities to agents. Here, we contribute a computational study of collective innovation where agents are Large Language Models (LLMs) that play Little Alchemy 2, a creative video game originally developed for humans that, as we argue, captures useful aspects of innovation landscapes not present in previous test-beds. We, first, study an LLM in isolation and discover that it exhibits both useful skills and crucial limitations. We, then, study groups of LLMs that share information related to their behaviour and focus on the effect of social connectivity on collective performance. In agreement with previous human and computational studies, we observe that groups with dynamic connectivity out-compete fully-connected groups. Our work reveals opportunities and challenges for future studies of collective innovation that are becoming increasingly relevant as Generative Artificial Intelligence algorithms and humans innovate alongside each other.
Toward Human-AI Alignment in Large-Scale Multi-Player Games
Feb 05, 2024



Achieving human-AI alignment in complex multi-agent games is crucial for creating trustworthy AI agents that enhance gameplay. We propose a method to evaluate this alignment using an interpretable task-sets framework, focusing on high-level behavioral tasks instead of low-level policies. Our approach has three components. First, we analyze extensive human gameplay data from Xbox's Bleeding Edge (100K+ games), uncovering behavioral patterns in a complex task space. This task space serves as a basis set for a behavior manifold capturing interpretable axes: fight-flight, explore-exploit, and solo-multi-agent. Second, we train an AI agent to play Bleeding Edge using a Generative Pretrained Causal Transformer and measure its behavior. Third, we project human and AI gameplay to the proposed behavior manifold to compare and contrast. This allows us to interpret differences in policy as higher-level behavioral concepts, e.g., we find that while human players exhibit variability in fight-flight and explore-exploit behavior, AI players tend towards uniformity. Furthermore, AI agents predominantly engage in solo play, while humans often engage in cooperative and competitive multi-agent patterns. These stark differences underscore the need for interpretable evaluation, design, and integration of AI in human-aligned applications. Our study advances the alignment discussion in AI and especially generative AI research, offering a measurable framework for interpretable human-agent alignment in multiplayer gaming.
Memory, Space, and Planning: Multiscale Predictive Representations
Jan 16, 2024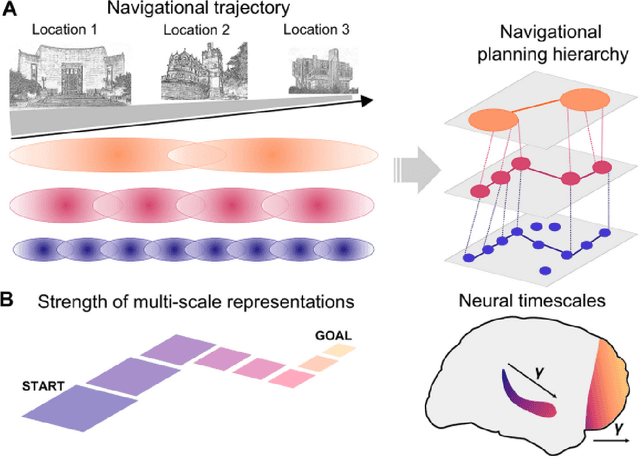

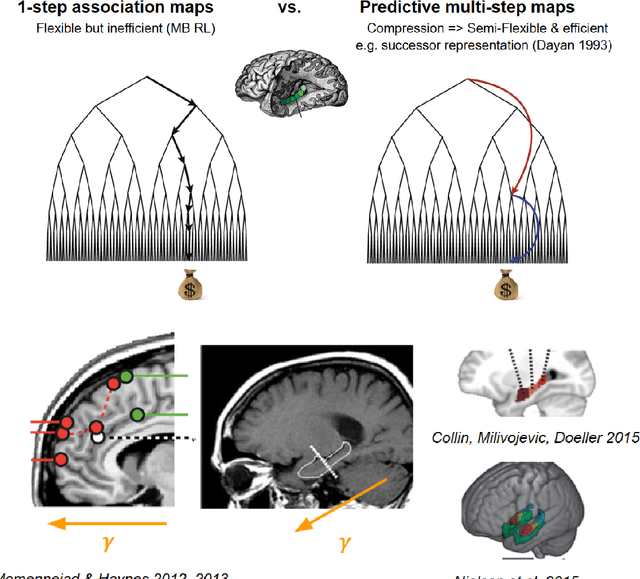
Memory is inherently entangled with prediction and planning. Flexible behavior in biological and artificial agents depends on the interplay of learning from the past and predicting the future in ever-changing environments. This chapter reviews computational, behavioral, and neural evidence suggesting these processes rely on learning the relational structure of experiences, known as cognitive maps, and draws two key takeaways. First, that these memory structures are organized as multiscale, compact predictive representations in hippocampal and prefrontal cortex, or PFC, hierarchies. Second, we argue that such predictive memory structures are crucial to the complementary functions of the hippocampus and PFC, both for enabling a recall of detailed and coherent past episodes as well as generalizing experiences at varying scales for efficient prediction and planning. These insights advance our understanding of memory and planning mechanisms in the brain and hold significant implications for advancing artificial intelligence systems.
In-Context Learning in Large Language Models: A Neuroscience-inspired Analysis of Representations
Oct 18, 2023



Large language models (LLMs) exhibit remarkable performance improvement through in-context learning (ICL) by leveraging task-specific examples in the input. However, the mechanisms behind this improvement remain elusive. In this work, we investigate embeddings and attention representations in Llama-2 70B and Vicuna 13B. Specifically, we study how embeddings and attention change after in-context-learning, and how these changes mediate improvement in behavior. We employ neuroscience-inspired techniques, such as representational similarity analysis (RSA), and propose novel methods for parameterized probing and attention ratio analysis (ARA, measuring the ratio of attention to relevant vs. irrelevant information). We designed three tasks with a priori relationships among their conditions: reading comprehension, linear regression, and adversarial prompt injection. We formed hypotheses about expected similarities in task representations to investigate latent changes in embeddings and attention. Our analyses revealed a meaningful correlation between changes in both embeddings and attention representations with improvements in behavioral performance after ICL. This empirical framework empowers a nuanced understanding of how latent representations affect LLM behavior with and without ICL, offering valuable tools and insights for future research and practical applications.
A Prefrontal Cortex-inspired Architecture for Planning in Large Language Models
Sep 30, 2023Large language models (LLMs) demonstrate impressive performance on a wide variety of tasks, but they often struggle with tasks that require multi-step reasoning or goal-directed planning. To address this, we take inspiration from the human brain, in which planning is accomplished via the recurrent interaction of specialized modules in the prefrontal cortex (PFC). These modules perform functions such as conflict monitoring, state prediction, state evaluation, task decomposition, and task coordination. We find that LLMs are sometimes capable of carrying out these functions in isolation, but struggle to autonomously coordinate them in the service of a goal. Therefore, we propose a black box architecture with multiple LLM-based (GPT-4) modules. The architecture improves planning through the interaction of specialized PFC-inspired modules that break down a larger problem into multiple brief automated calls to the LLM. We evaluate the combined architecture on two challenging planning tasks -- graph traversal and Tower of Hanoi -- finding that it yields significant improvements over standard LLM methods (e.g., zero-shot prompting or in-context learning). These results demonstrate the benefit of utilizing knowledge from cognitive neuroscience to improve planning in LLMs.
ALLURE: Auditing and Improving LLM-based Evaluation of Text using Iterative In-Context-Learning
Sep 27, 2023



From grading papers to summarizing medical documents, large language models (LLMs) are evermore used for evaluation of text generated by humans and AI alike. However, despite their extensive utility, LLMs exhibit distinct failure modes, necessitating a thorough audit and improvement of their text evaluation capabilities. Here we introduce ALLURE, a systematic approach to Auditing Large Language Models Understanding and Reasoning Errors. ALLURE involves comparing LLM-generated evaluations with annotated data, and iteratively incorporating instances of significant deviation into the evaluator, which leverages in-context learning (ICL) to enhance and improve robust evaluation of text by LLMs. Through this iterative process, we refine the performance of the evaluator LLM, ultimately reducing reliance on human annotators in the evaluation process. We anticipate ALLURE to serve diverse applications of LLMs in various domains related to evaluation of textual data, such as medical summarization, education, and and productivity.
Evaluating Cognitive Maps and Planning in Large Language Models with CogEval
Sep 25, 2023


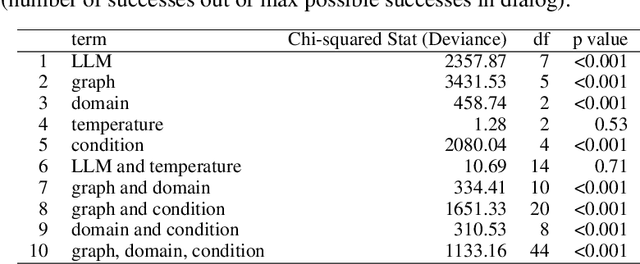
Recently an influx of studies claim emergent cognitive abilities in large language models (LLMs). Yet, most rely on anecdotes, overlook contamination of training sets, or lack systematic Evaluation involving multiple tasks, control conditions, multiple iterations, and statistical robustness tests. Here we make two major contributions. First, we propose CogEval, a cognitive science-inspired protocol for the systematic evaluation of cognitive capacities in Large Language Models. The CogEval protocol can be followed for the evaluation of various abilities. Second, here we follow CogEval to systematically evaluate cognitive maps and planning ability across eight LLMs (OpenAI GPT-4, GPT-3.5-turbo-175B, davinci-003-175B, Google Bard, Cohere-xlarge-52.4B, Anthropic Claude-1-52B, LLaMA-13B, and Alpaca-7B). We base our task prompts on human experiments, which offer both established construct validity for evaluating planning, and are absent from LLM training sets. We find that, while LLMs show apparent competence in a few planning tasks with simpler structures, systematic evaluation reveals striking failure modes in planning tasks, including hallucinations of invalid trajectories and getting trapped in loops. These findings do not support the idea of emergent out-of-the-box planning ability in LLMs. This could be because LLMs do not understand the latent relational structures underlying planning problems, known as cognitive maps, and fail at unrolling goal-directed trajectories based on the underlying structure. Implications for application and future directions are discussed.
Replay Buffer With Local Forgetting for Adaptive Deep Model-Based Reinforcement Learning
Mar 15, 2023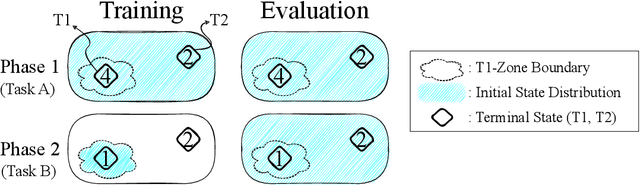
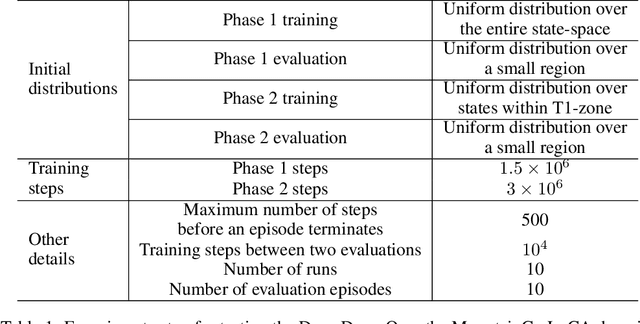
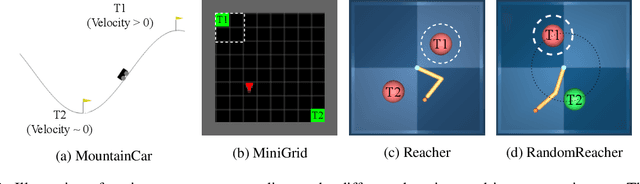
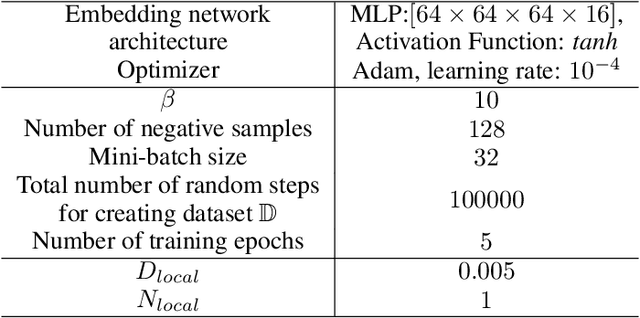
One of the key behavioral characteristics used in neuroscience to determine whether the subject of study -- be it a rodent or a human -- exhibits model-based learning is effective adaptation to local changes in the environment. In reinforcement learning, however, recent work has shown that modern deep model-based reinforcement-learning (MBRL) methods adapt poorly to such changes. An explanation for this mismatch is that MBRL methods are typically designed with sample-efficiency on a single task in mind and the requirements for effective adaptation are substantially higher, both in terms of the learned world model and the planning routine. One particularly challenging requirement is that the learned world model has to be sufficiently accurate throughout relevant parts of the state-space. This is challenging for deep-learning-based world models due to catastrophic forgetting. And while a replay buffer can mitigate the effects of catastrophic forgetting, the traditional first-in-first-out replay buffer precludes effective adaptation due to maintaining stale data. In this work, we show that a conceptually simple variation of this traditional replay buffer is able to overcome this limitation. By removing only samples from the buffer from the local neighbourhood of the newly observed samples, deep world models can be built that maintain their accuracy across the state-space, while also being able to effectively adapt to changes in the reward function. We demonstrate this by applying our replay-buffer variation to a deep version of the classical Dyna method, as well as to recent methods such as PlaNet and DreamerV2, demonstrating that deep model-based methods can adapt effectively as well to local changes in the environment.