 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinding Visual Features Point by Point
May 25, 2026Despite success on standard benchmarks, vision language models display persistent failures on tasks involving processing of multi-object scenes, including many tasks that are relatively easy for humans. Recent work has found that these failures may stem from a basic inability to accurately bind object features in-context, a challenge that is referred to as the "binding problem" in cognitive science and neuroscience. The human visual system is thought to solve this binding problem via serial processing, attending to individual objects one at a time so as to avoid interference from other objects. Recent work has proposed "pointing" -- the use of explicit spatial coordinates to refer to objects -- as an analogous solution for vision language models, and found that it improves performance on challenging multi-object tasks. However, it is unclear $\textit{why}$ (i.e., on a mechanistic or representational level) this approach improves performance, and how directly this relates to serial processing in human vision. Here, we investigate this question. We find that learning to point-via-text induces an internal visual search routine, and we characterize the mechanisms that support this procedure. We also find that pointing behavior can be generalized to new tasks via fine-tuning, and that doing so eliminates binding errors and enables compositional generalization. These results provide a proof-of-principle that serial processing can solve the binding problem for vision language models just as it does for biological vision.
Evaluating Compositional Scene Understanding in Multimodal Generative Models
Mar 29, 2025



The visual world is fundamentally compositional. Visual scenes are defined by the composition of objects and their relations. Hence, it is essential for computer vision systems to reflect and exploit this compositionality to achieve robust and generalizable scene understanding. While major strides have been made toward the development of general-purpose, multimodal generative models, including both text-to-image models and multimodal vision-language models, it remains unclear whether these systems are capable of accurately generating and interpreting scenes involving the composition of multiple objects and relations. In this work, we present an evaluation of the compositional visual processing capabilities in the current generation of text-to-image (DALL-E 3) and multimodal vision-language models (GPT-4V, GPT-4o, Claude Sonnet 3.5, QWEN2-VL-72B, and InternVL2.5-38B), and compare the performance of these systems to human participants. The results suggest that these systems display some ability to solve compositional and relational tasks, showing notable improvements over the previous generation of multimodal models, but with performance nevertheless well below the level of human participants, particularly for more complex scenes involving many ($>5$) objects and multiple relations. These results highlight the need for further progress toward compositional understanding of visual scenes.
Understanding the Limits of Vision Language Models Through the Lens of the Binding Problem
Oct 31, 2024



Recent work has documented striking heterogeneity in the performance of state-of-the-art vision language models (VLMs), including both multimodal language models and text-to-image models. These models are able to describe and generate a diverse array of complex, naturalistic images, yet they exhibit surprising failures on basic multi-object reasoning tasks -- such as counting, localization, and simple forms of visual analogy -- that humans perform with near perfect accuracy. To better understand this puzzling pattern of successes and failures, we turn to theoretical accounts of the binding problem in cognitive science and neuroscience, a fundamental problem that arises when a shared set of representational resources must be used to represent distinct entities (e.g., to represent multiple objects in an image), necessitating the use of serial processing to avoid interference. We find that many of the puzzling failures of state-of-the-art VLMs can be explained as arising due to the binding problem, and that these failure modes are strikingly similar to the limitations exhibited by rapid, feedforward processing in the human brain.
Slot Abstractors: Toward Scalable Abstract Visual Reasoning
Mar 06, 2024



Abstract visual reasoning is a characteristically human ability, allowing the identification of relational patterns that are abstracted away from object features, and the systematic generalization of those patterns to unseen problems. Recent work has demonstrated strong systematic generalization in visual reasoning tasks involving multi-object inputs, through the integration of slot-based methods used for extracting object-centric representations coupled with strong inductive biases for relational abstraction. However, this approach was limited to problems containing a single rule, and was not scalable to visual reasoning problems containing a large number of objects. Other recent work proposed Abstractors, an extension of Transformers that incorporates strong relational inductive biases, thereby inheriting the Transformer's scalability and multi-head architecture, but it has yet to be demonstrated how this approach might be applied to multi-object visual inputs. Here we combine the strengths of the above approaches and propose Slot Abstractors, an approach to abstract visual reasoning that can be scaled to problems involving a large number of objects and multiple relations among them. The approach displays state-of-the-art performance across four abstract visual reasoning tasks.
The Relational Bottleneck as an Inductive Bias for Efficient Abstraction
Sep 12, 2023

A central challenge for cognitive science is to explain how abstract concepts are acquired from limited experience. This effort has often been framed in terms of a dichotomy between empiricist and nativist approaches, most recently embodied by debates concerning deep neural networks and symbolic cognitive models. Here, we highlight a recently emerging line of work that suggests a novel reconciliation of these approaches, by exploiting an inductive bias that we term the relational bottleneck. We review a family of models that employ this approach to induce abstractions in a data-efficient manner, emphasizing their potential as candidate models for the acquisition of abstract concepts in the human mind and brain.
Systematic Visual Reasoning through Object-Centric Relational Abstraction
Jun 04, 2023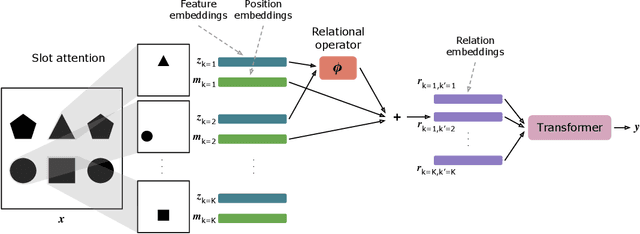



Human visual reasoning is characterized by an ability to identify abstract patterns from only a small number of examples, and to systematically generalize those patterns to novel inputs. This capacity depends in large part on our ability to represent complex visual inputs in terms of both objects and relations. Recent work in computer vision has introduced models with the capacity to extract object-centric representations, leading to the ability to process multi-object visual inputs, but falling short of the systematic generalization displayed by human reasoning. Other recent models have employed inductive biases for relational abstraction to achieve systematic generalization of learned abstract rules, but have generally assumed the presence of object-focused inputs. Here, we combine these two approaches, introducing Object-Centric Relational Abstraction (OCRA), a model that extracts explicit representations of both objects and abstract relations, and achieves strong systematic generalization in tasks involving complex visual displays.
Zero-shot visual reasoning through probabilistic analogical mapping
Sep 29, 2022
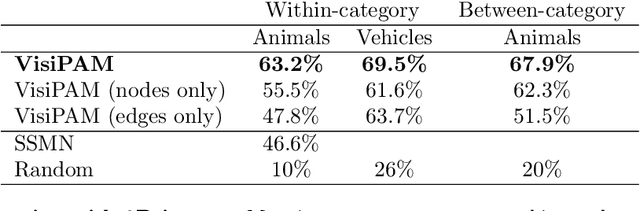


Human reasoning is grounded in an ability to identify highly abstract commonalities governing superficially dissimilar visual inputs. Recent efforts to develop algorithms with this capacity have largely focused on approaches that require extensive direct training on visual reasoning tasks, and yield limited generalization to problems with novel content. In contrast, a long tradition of research in cognitive science has focused on elucidating the computational principles underlying human analogical reasoning; however, this work has generally relied on manually constructed representations. Here we present visiPAM (visual Probabilistic Analogical Mapping), a model of visual reasoning that synthesizes these two approaches. VisiPAM employs learned representations derived directly from naturalistic visual inputs, coupled with a similarity-based mapping operation derived from cognitive theories of human reasoning. We show that without any direct training, visiPAM outperforms a state-of-the-art deep learning model on an analogical mapping task. In addition, visiPAM closely matches the pattern of human performance on a novel task involving mapping of 3D objects across disparate categories.
Emergent Symbols through Binding in External Memory
Dec 29, 2020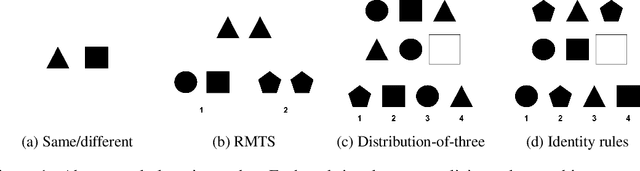
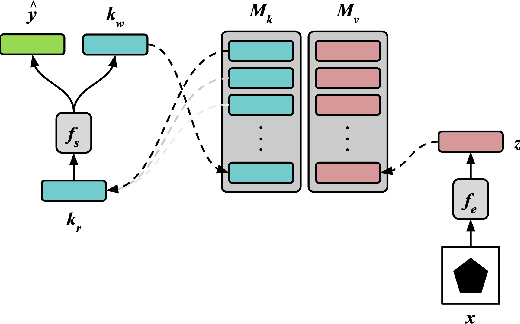
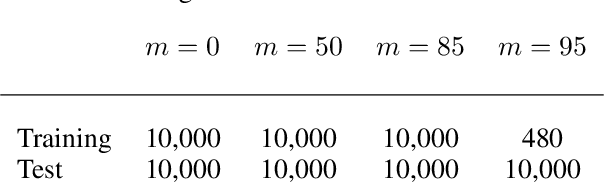
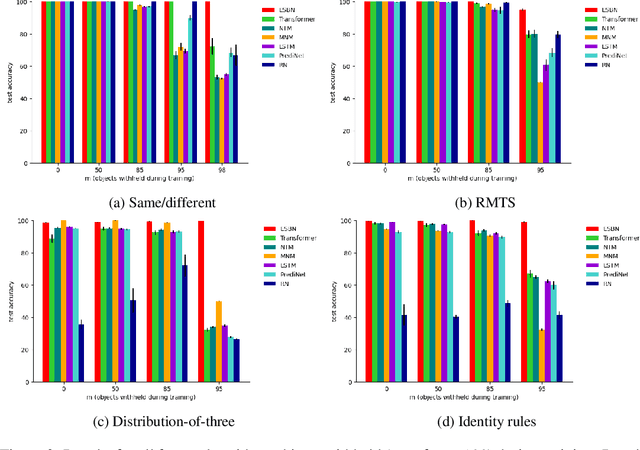
A key aspect of human intelligence is the ability to infer abstract rules directly from high-dimensional sensory data, and to do so given only a limited amount of training experience. Deep neural network algorithms have proven to be a powerful tool for learning directly from high-dimensional data, but currently lack this capacity for data-efficient induction of abstract rules, leading some to argue that symbol-processing mechanisms will be necessary to account for this capacity. In this work, we take a step toward bridging this gap by introducing the Emergent Symbol Binding Network (ESBN), a recurrent network augmented with an external memory that enables a form of variable-binding and indirection. This binding mechanism allows symbol-like representations to emerge through the learning process without the need to explicitly incorporate symbol-processing machinery, enabling the ESBN to learn rules in a manner that is abstracted away from the particular entities to which those rules apply. Across a series of tasks, we show that this architecture displays nearly perfect generalization of learned rules to novel entities given only a limited number of training examples, and outperforms a number of other competitive neural network architectures.
A Memory-Augmented Neural Network Model of Abstract Rule Learning
Dec 15, 2020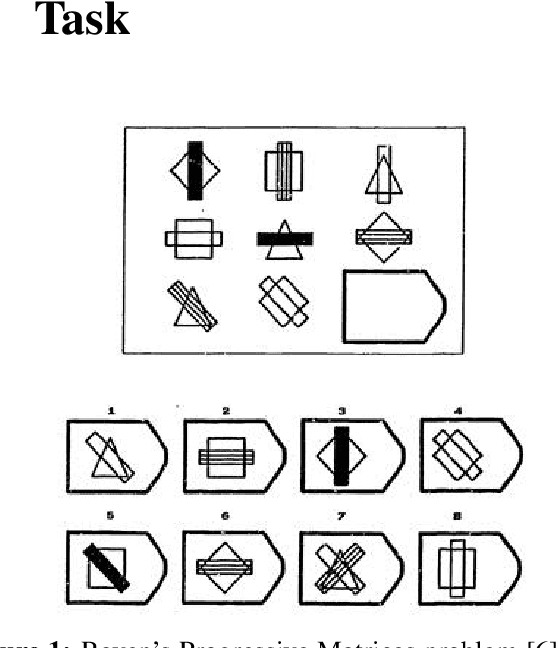
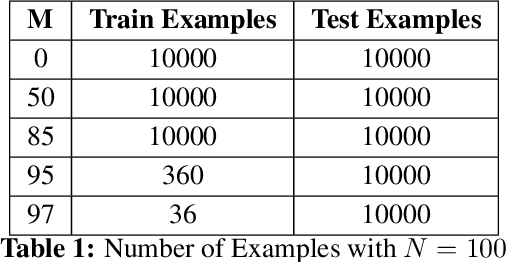
Human intelligence is characterized by a remarkable ability to infer abstract rules from experience and apply these rules to novel domains. As such, designing neural network algorithms with this capacity is an important step toward the development of deep learning systems with more human-like intelligence. However, doing so is a major outstanding challenge, one that some argue will require neural networks to use explicit symbol-processing mechanisms. In this work, we focus on neural networks' capacity for arbitrary role-filler binding, the ability to associate abstract "roles" to context-specific "fillers," which many have argued is an important mechanism underlying the ability to learn and apply rules abstractly. Using a simplified version of Raven's Progressive Matrices, a hallmark test of human intelligence, we introduce a sequential formulation of a visual problem-solving task that requires this form of binding. Further, we introduce the Emergent Symbol Binding Network (ESBN), a recurrent neural network model that learns to use an external memory as a binding mechanism. This mechanism enables symbol-like variable representations to emerge through the ESBN's training process without the need for explicit symbol-processing machinery. We empirically demonstrate that the ESBN successfully learns the underlying abstract rule structure of our task and perfectly generalizes this rule structure to novel fillers.
Learning Representations that Support Extrapolation
Jul 09, 2020
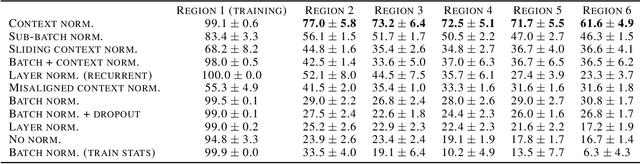
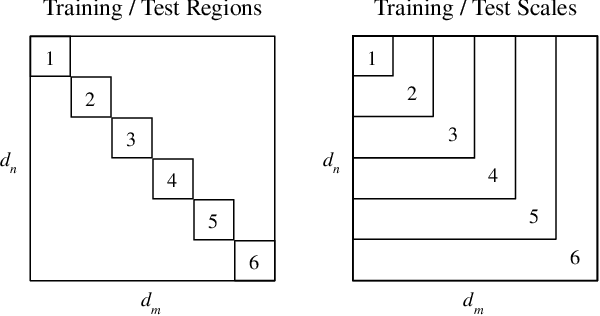

Extrapolation -- the ability to make inferences that go beyond the scope of one's experiences -- is a hallmark of human intelligence. By contrast, the generalization exhibited by contemporary neural network algorithms is largely limited to interpolation between data points in their training corpora. In this paper, we consider the challenge of learning representations that support extrapolation. We introduce a novel visual analogy benchmark that allows the graded evaluation of extrapolation as a function of distance from the convex domain defined by the training data. We also introduce a simple technique, context normalization, that encourages representations that emphasize the relations between objects. We find that this technique enables a significant improvement in the ability to extrapolate, considerably outperforming a number of competitive techniques.