 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence from counterfactual tasks supports emergent analogical reasoning in large language models
Apr 29, 2024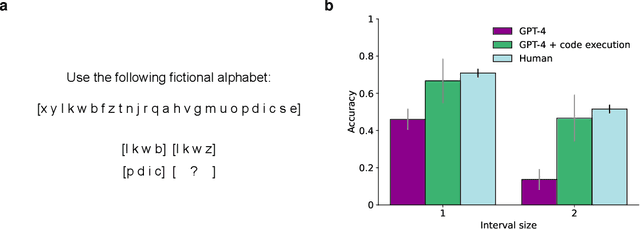
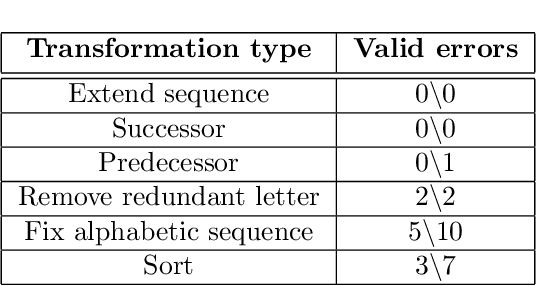
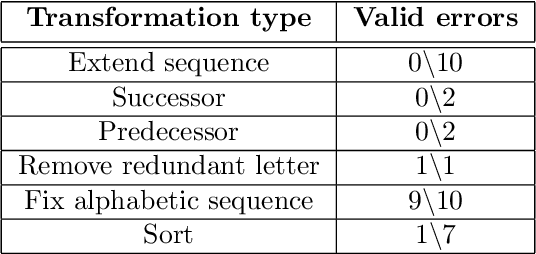
We recently reported evidence that large language models are capable of solving a wide range of text-based analogy problems in a zero-shot manner, indicating the presence of an emergent capacity for analogical reasoning. Two recent commentaries have challenged these results, citing evidence from so-called `counterfactual' tasks in which the standard sequence of the alphabet is arbitrarily permuted so as to decrease similarity with materials that may have been present in the language model's training data. Here, we reply to these critiques, clarifying some misunderstandings about the test materials used in our original work, and presenting evidence that language models are also capable of generalizing to these new counterfactual task variants.
Large Language Model Displays Emergent Ability to Interpret Novel Literary Metaphors
Aug 03, 2023


Recent advances in the performance of large language models (LLMs) have sparked debate over whether, given sufficient training, high-level human abilities emerge in such generic forms of artificial intelligence (AI). Despite the exceptional performance of LLMs on a wide range of tasks involving natural language processing and reasoning, there has been sharp disagreement as to whether their abilities extend to more creative human abilities. A core example is the ability to interpret novel metaphors. Given the enormous and non-curated text corpora used to train LLMs, a serious obstacle to designing tests is the requirement of finding novel yet high-quality metaphors that are unlikely to have been included in the training data. Here we assessed the ability of GPT-4, a state-of-the-art large language model, to provide natural-language interpretations of novel literary metaphors drawn from Serbian poetry and translated into English. Despite exhibiting no signs of having been exposed to these metaphors previously, the AI system consistently produced detailed and incisive interpretations. Human judge - blind to the fact that an AI model was involved - rated metaphor interpretations generated by GPT-4 as superior to those provided by a group of college students. In interpreting reversed metaphors, GPT-4, as well as humans, exhibited signs of sensitivity to the Gricean cooperative principle. These results indicate that LLMs such as GPT-4 have acquired an emergent ability to interpret complex novel metaphors.
Emergent Analogical Reasoning in Large Language Models
Dec 19, 2022The recent advent of large language models - large neural networks trained on a simple predictive objective over a massive corpus of natural language - has reinvigorated debate over whether human cognitive capacities might emerge in such generic models given sufficient training data. Of particular interest is the ability of these models to reason about novel problems zero-shot, without any direct training on those problems. In human cognition, this capacity is closely tied to an ability to reason by analogy. Here, we performed a direct comparison between human reasoners and a large language model (GPT-3) on a range of analogical tasks, including a novel text-based matrix reasoning task closely modeled on Raven's Progressive Matrices. We found that GPT-3 displayed a surprisingly strong capacity for abstract pattern induction, matching or even surpassing human capabilities in most settings. Our results indicate that large language models such as GPT-3 have acquired an emergent ability to find zero-shot solutions to a broad range of analogy problems.
Zero-shot visual reasoning through probabilistic analogical mapping
Sep 29, 2022
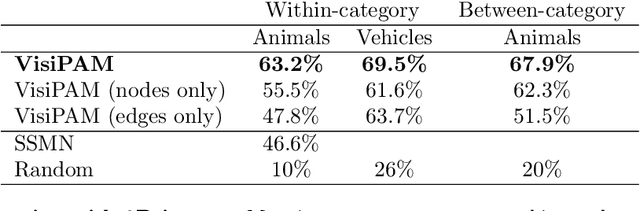


Human reasoning is grounded in an ability to identify highly abstract commonalities governing superficially dissimilar visual inputs. Recent efforts to develop algorithms with this capacity have largely focused on approaches that require extensive direct training on visual reasoning tasks, and yield limited generalization to problems with novel content. In contrast, a long tradition of research in cognitive science has focused on elucidating the computational principles underlying human analogical reasoning; however, this work has generally relied on manually constructed representations. Here we present visiPAM (visual Probabilistic Analogical Mapping), a model of visual reasoning that synthesizes these two approaches. VisiPAM employs learned representations derived directly from naturalistic visual inputs, coupled with a similarity-based mapping operation derived from cognitive theories of human reasoning. We show that without any direct training, visiPAM outperforms a state-of-the-art deep learning model on an analogical mapping task. In addition, visiPAM closely matches the pattern of human performance on a novel task involving mapping of 3D objects across disparate categories.
Visual analogy: Deep learning versus compositional models
May 14, 2021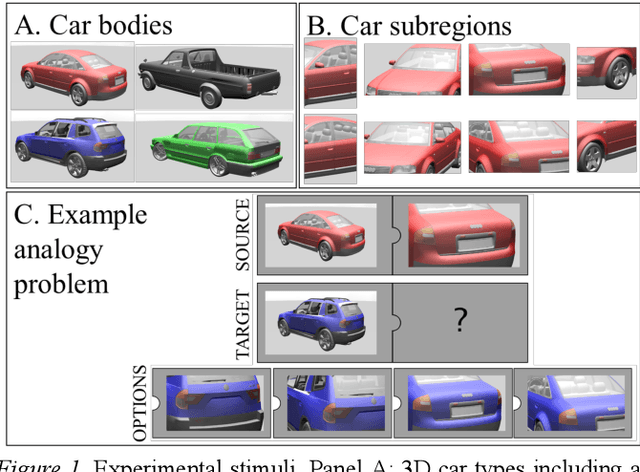
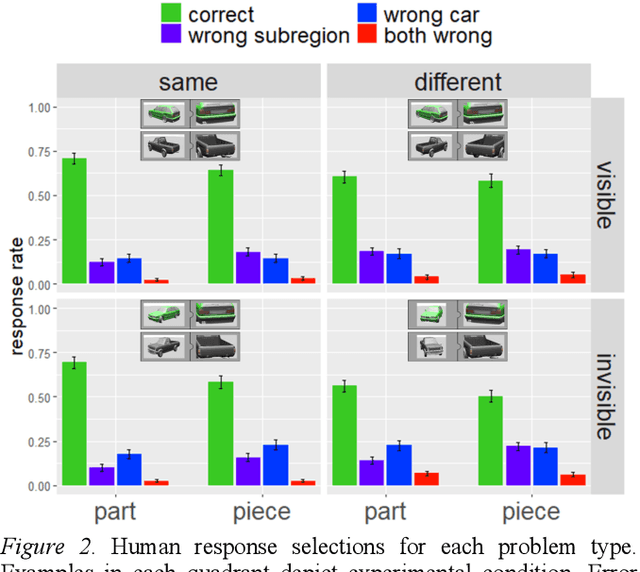
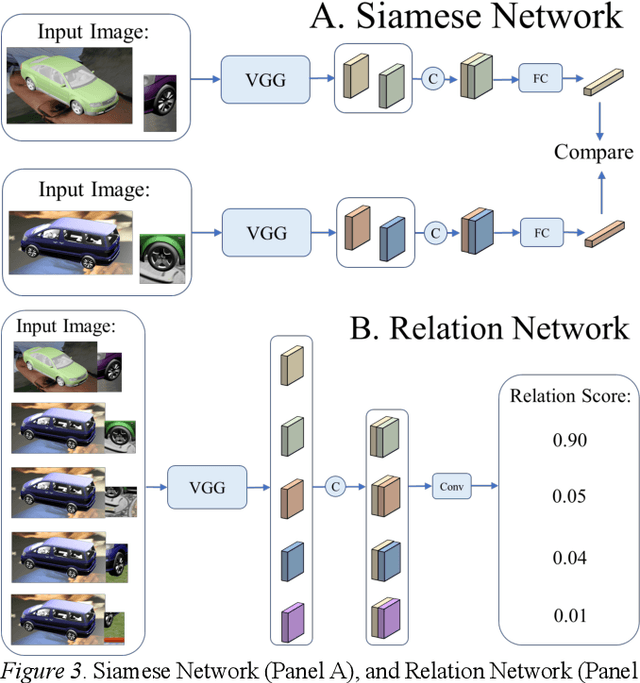
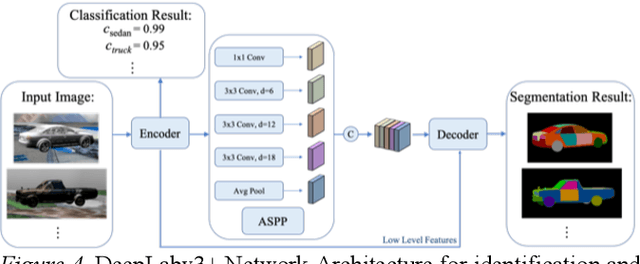
Is analogical reasoning a task that must be learned to solve from scratch by applying deep learning models to massive numbers of reasoning problems? Or are analogies solved by computing similarities between structured representations of analogs? We address this question by comparing human performance on visual analogies created using images of familiar three-dimensional objects (cars and their subregions) with the performance of alternative computational models. Human reasoners achieved above-chance accuracy for all problem types, but made more errors in several conditions (e.g., when relevant subregions were occluded). We compared human performance to that of two recent deep learning models (Siamese Network and Relation Network) directly trained to solve these analogy problems, as well as to that of a compositional model that assesses relational similarity between part-based representations. The compositional model based on part representations, but not the deep learning models, generated qualitative performance similar to that of human reasoners.
Probabilistic Analogical Mapping with Semantic Relation Networks
Mar 30, 2021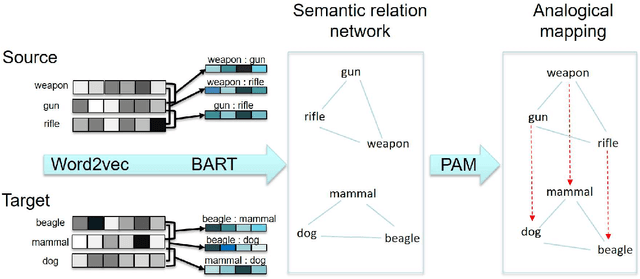
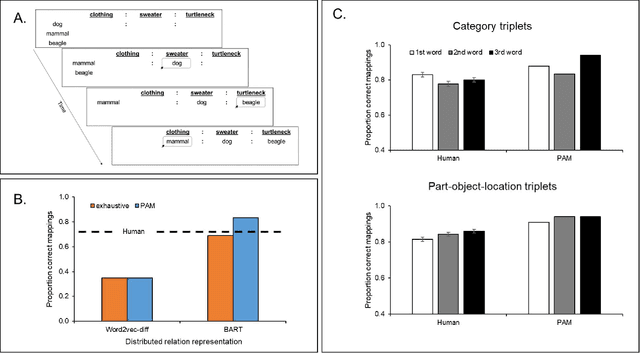

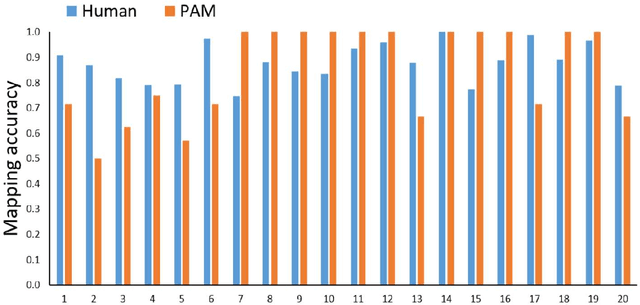
The human ability to flexibly reason with cross-domain analogies depends on mechanisms for identifying relations between concepts and for mapping concepts and their relations across analogs. We present a new computational model of analogical mapping, based on semantic relation networks constructed from distributed representations of individual concepts and of relations between concepts. Through comparisons with human performance in a new analogy experiment with 1,329 participants, as well as in four classic studies, we demonstrate that the model accounts for a broad range of phenomena involving analogical mapping by both adults and children. The key insight is that rich semantic representations of individual concepts and relations, coupled with a generic prior favoring isomorphic mappings, yield human-like analogical mapping.