 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo AI Models Perform Human-like Abstract Reasoning Across Modalities?
Oct 02, 2025OpenAI's o3-preview reasoning model exceeded human accuracy on the ARC-AGI benchmark, but does that mean state-of-the-art models recognize and reason with the abstractions that the task creators intended? We investigate models' abstraction abilities on ConceptARC. We evaluate models under settings that vary the input modality (textual vs. visual), whether the model is permitted to use external Python tools, and, for reasoning models, the amount of reasoning effort. In addition to measuring output accuracy, we perform fine-grained evaluation of the natural-language rules that models generate to explain their solutions. This dual evaluation lets us assess whether models solve tasks using the abstractions ConceptARC was designed to elicit, rather than relying on surface-level patterns. Our results show that, while some models using text-based representations match human output accuracy, the best models' rules are often based on surface-level ``shortcuts'' and capture intended abstractions far less often than humans. Thus their capabilities for general abstract reasoning may be overestimated by evaluations based on accuracy alone. In the visual modality, AI models' output accuracy drops sharply, yet our rule-level analysis reveals that models might be underestimated, as they still exhibit a substantial share of rules that capture intended abstractions, but are often unable to correctly apply these rules. In short, our results show that models still lag humans in abstract reasoning, and that using accuracy alone to evaluate abstract reasoning on ARC-like tasks may overestimate abstract-reasoning capabilities in textual modalities and underestimate it in visual modalities. We believe that our evaluation framework offers a more faithful picture of multimodal models' abstract reasoning abilities and a more principled way to track progress toward human-like, abstraction-centered intelligence.
Evaluating Compositional Scene Understanding in Multimodal Generative Models
Mar 29, 2025The visual world is fundamentally compositional. Visual scenes are defined by the composition of objects and their relations. Hence, it is essential for computer vision systems to reflect and exploit this compositionality to achieve robust and generalizable scene understanding. While major strides have been made toward the development of general-purpose, multimodal generative models, including both text-to-image models and multimodal vision-language models, it remains unclear whether these systems are capable of accurately generating and interpreting scenes involving the composition of multiple objects and relations. In this work, we present an evaluation of the compositional visual processing capabilities in the current generation of text-to-image (DALL-E 3) and multimodal vision-language models (GPT-4V, GPT-4o, Claude Sonnet 3.5, QWEN2-VL-72B, and InternVL2.5-38B), and compare the performance of these systems to human participants. The results suggest that these systems display some ability to solve compositional and relational tasks, showing notable improvements over the previous generation of multimodal models, but with performance nevertheless well below the level of human participants, particularly for more complex scenes involving many ($>5$) objects and multiple relations. These results highlight the need for further progress toward compositional understanding of visual scenes.
Synthetic Data Generation with LLM for Improved Depression Prediction
Nov 26, 2024Automatic detection of depression is a rapidly growing field of research at the intersection of psychology and machine learning. However, with its exponential interest comes a growing concern for data privacy and scarcity due to the sensitivity of such a topic. In this paper, we propose a pipeline for Large Language Models (LLMs) to generate synthetic data to improve the performance of depression prediction models. Starting from unstructured, naturalistic text data from recorded transcripts of clinical interviews, we utilize an open-source LLM to generate synthetic data through chain-of-thought prompting. This pipeline involves two key steps: the first step is the generation of the synopsis and sentiment analysis based on the original transcript and depression score, while the second is the generation of the synthetic synopsis/sentiment analysis based on the summaries generated in the first step and a new depression score. Not only was the synthetic data satisfactory in terms of fidelity and privacy-preserving metrics, it also balanced the distribution of severity in the training dataset, thereby significantly enhancing the model's capability in predicting the intensity of the patient's depression. By leveraging LLMs to generate synthetic data that can be augmented to limited and imbalanced real-world datasets, we demonstrate a novel approach to addressing data scarcity and privacy concerns commonly faced in automatic depression detection, all while maintaining the statistical integrity of the original dataset. This approach offers a robust framework for future mental health research and applications.
Zero-shot visual reasoning through probabilistic analogical mapping
Sep 29, 2022
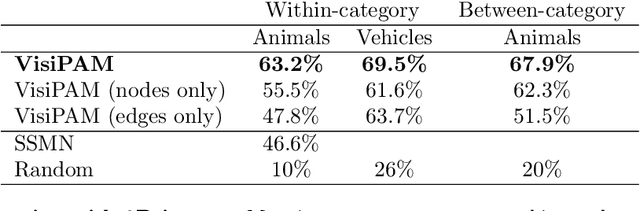


Human reasoning is grounded in an ability to identify highly abstract commonalities governing superficially dissimilar visual inputs. Recent efforts to develop algorithms with this capacity have largely focused on approaches that require extensive direct training on visual reasoning tasks, and yield limited generalization to problems with novel content. In contrast, a long tradition of research in cognitive science has focused on elucidating the computational principles underlying human analogical reasoning; however, this work has generally relied on manually constructed representations. Here we present visiPAM (visual Probabilistic Analogical Mapping), a model of visual reasoning that synthesizes these two approaches. VisiPAM employs learned representations derived directly from naturalistic visual inputs, coupled with a similarity-based mapping operation derived from cognitive theories of human reasoning. We show that without any direct training, visiPAM outperforms a state-of-the-art deep learning model on an analogical mapping task. In addition, visiPAM closely matches the pattern of human performance on a novel task involving mapping of 3D objects across disparate categories.
Visual analogy: Deep learning versus compositional models
May 14, 2021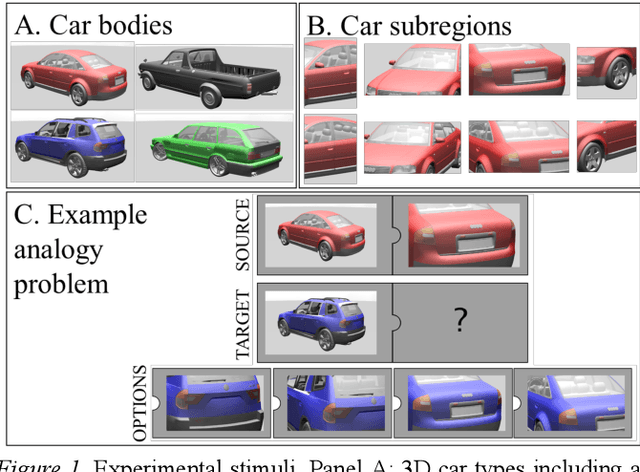
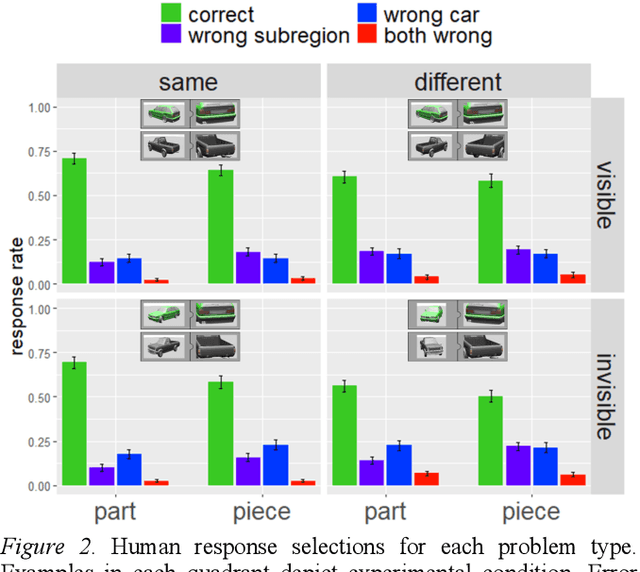
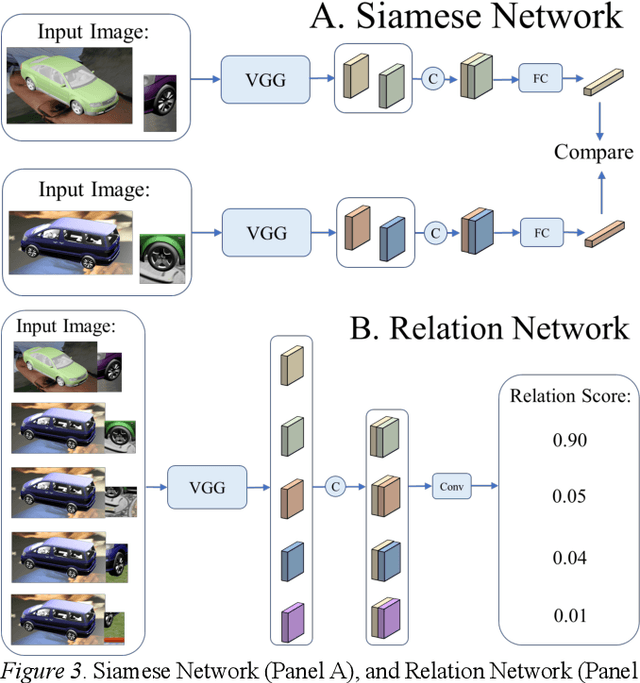
Is analogical reasoning a task that must be learned to solve from scratch by applying deep learning models to massive numbers of reasoning problems? Or are analogies solved by computing similarities between structured representations of analogs? We address this question by comparing human performance on visual analogies created using images of familiar three-dimensional objects (cars and their subregions) with the performance of alternative computational models. Human reasoners achieved above-chance accuracy for all problem types, but made more errors in several conditions (e.g., when relevant subregions were occluded). We compared human performance to that of two recent deep learning models (Siamese Network and Relation Network) directly trained to solve these analogy problems, as well as to that of a compositional model that assesses relational similarity between part-based representations. The compositional model based on part representations, but not the deep learning models, generated qualitative performance similar to that of human reasoners.
Domain Adaptive Relational Reasoning for 3D Multi-Organ Segmentation
May 18, 2020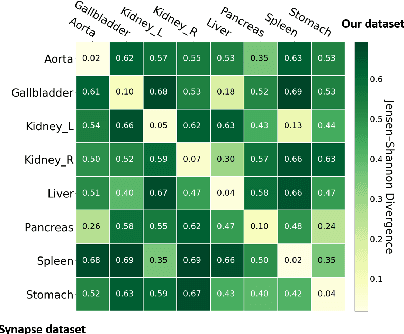
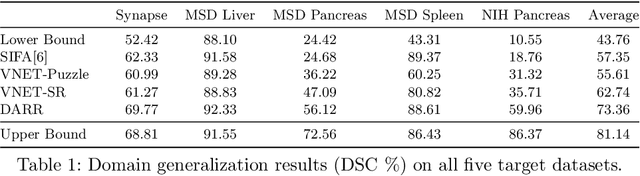
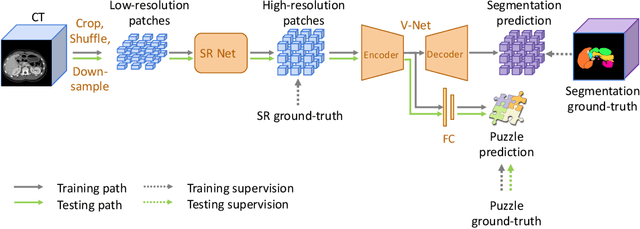
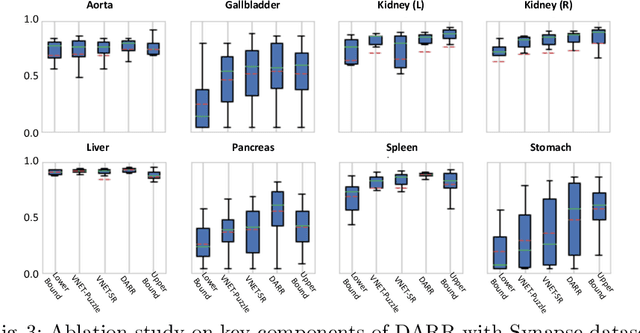
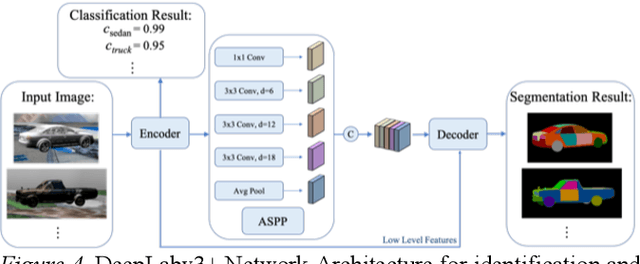
In this paper, we present a novel unsupervised domain adaptation (UDA) method, named Domain Adaptive Relational Reasoning (DARR), to generalize 3D multi-organ segmentation models to medical data collected from different scanners and/or protocols (domains). Our method is inspired by the fact that the spatial relationship between internal structures in medical images is relatively fixed, e.g., a spleen is always located at the tail of a pancreas, which serves as a latent variable to transfer the knowledge shared across multiple domains. We formulate the spatial relationship by solving a jigsaw puzzle task, i.e., recovering a CT scan from its shuffled patches, and jointly train it with the organ segmentation task. To guarantee the transferability of the learned spatial relationship to multiple domains, we additionally introduce two schemes: 1) Employing a super-resolution network also jointly trained with the segmentation model to standardize medical images from different domain to a certain spatial resolution; 2) Adapting the spatial relationship for a test image by test-time jigsaw puzzle training. Experimental results show that our method improves the performance by 29.60\% DSC on target datasets on average without using any data from the target domain during training.
Attack-Resistant Federated Learning with Residual-based Reweighting
Dec 24, 2019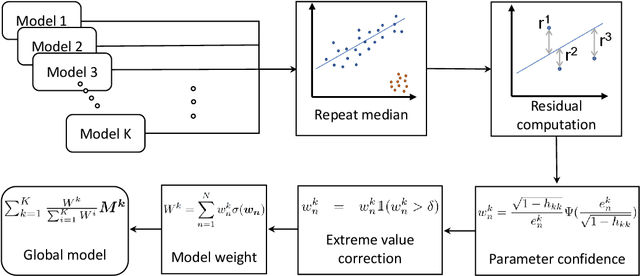
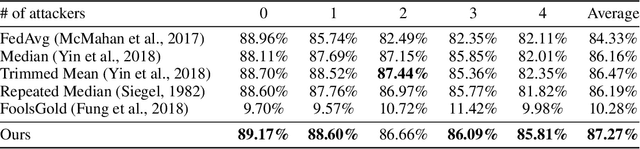

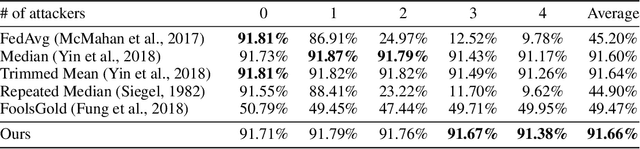
Federated learning has a variety of applications in multiple domains by utilizing private training data stored on different devices. However, the aggregation process in federated learning is highly vulnerable to adversarial attacks so that the global model may behave abnormally under attacks. To tackle this challenge, we present a novel aggregation algorithm with residual-based reweighting to defend federated learning. Our aggregation algorithm combines repeated median regression with the reweighting scheme in iteratively reweighted least squares. Our experiments show that our aggregation algorithm outperforms other alternative algorithms in the presence of label-flipping, backdoor, and Gaussian noise attacks. We also provide theoretical guarantees for our aggregation algorithm.