 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot Learning of Visual Compositional Concepts through Probabilistic Schema Induction
May 14, 2025The ability to learn new visual concepts from limited examples is a hallmark of human cognition. While traditional category learning models represent each example as an unstructured feature vector, compositional concept learning is thought to depend on (1) structured representations of examples (e.g., directed graphs consisting of objects and their relations) and (2) the identification of shared relational structure across examples through analogical mapping. Here, we introduce Probabilistic Schema Induction (PSI), a prototype model that employs deep learning to perform analogical mapping over structured representations of only a handful of examples, forming a compositional concept called a schema. In doing so, PSI relies on a novel conception of similarity that weighs object-level similarity and relational similarity, as well as a mechanism for amplifying relations relevant to classification, analogous to selective attention parameters in traditional models. We show that PSI produces human-like learning performance and outperforms two controls: a prototype model that uses unstructured feature vectors extracted from a deep learning model, and a variant of PSI with weaker structured representations. Notably, we find that PSI's human-like performance is driven by an adaptive strategy that increases relational similarity over object-level similarity and upweights the contribution of relations that distinguish classes. These findings suggest that structured representations and analogical mapping are critical to modeling rapid human-like learning of compositional visual concepts, and demonstrate how deep learning can be leveraged to create psychological models.
Evaluating Compositional Scene Understanding in Multimodal Generative Models
Mar 29, 2025The visual world is fundamentally compositional. Visual scenes are defined by the composition of objects and their relations. Hence, it is essential for computer vision systems to reflect and exploit this compositionality to achieve robust and generalizable scene understanding. While major strides have been made toward the development of general-purpose, multimodal generative models, including both text-to-image models and multimodal vision-language models, it remains unclear whether these systems are capable of accurately generating and interpreting scenes involving the composition of multiple objects and relations. In this work, we present an evaluation of the compositional visual processing capabilities in the current generation of text-to-image (DALL-E 3) and multimodal vision-language models (GPT-4V, GPT-4o, Claude Sonnet 3.5, QWEN2-VL-72B, and InternVL2.5-38B), and compare the performance of these systems to human participants. The results suggest that these systems display some ability to solve compositional and relational tasks, showing notable improvements over the previous generation of multimodal models, but with performance nevertheless well below the level of human participants, particularly for more complex scenes involving many ($>5$) objects and multiple relations. These results highlight the need for further progress toward compositional understanding of visual scenes.
Neuro-Symbolic Fusion of Wi-Fi Sensing Data for Passive Radar with Inter-Modal Knowledge Transfer
Jul 01, 2024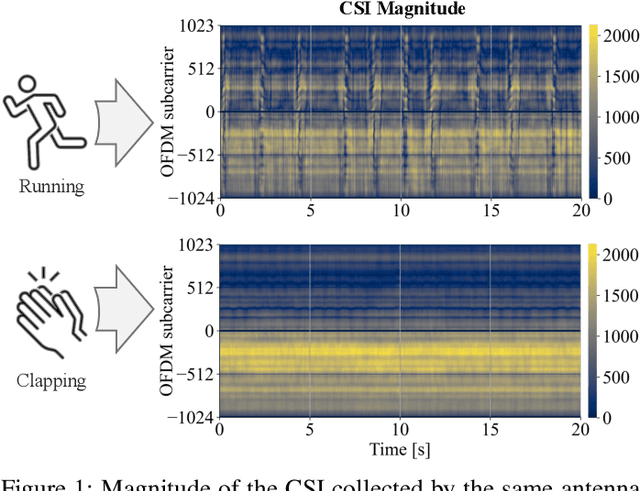
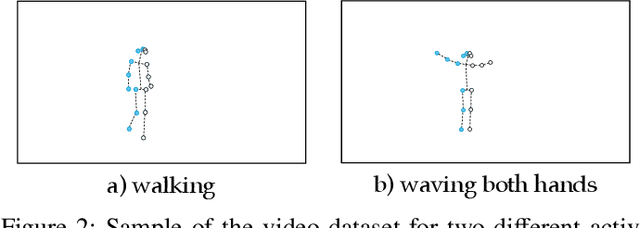
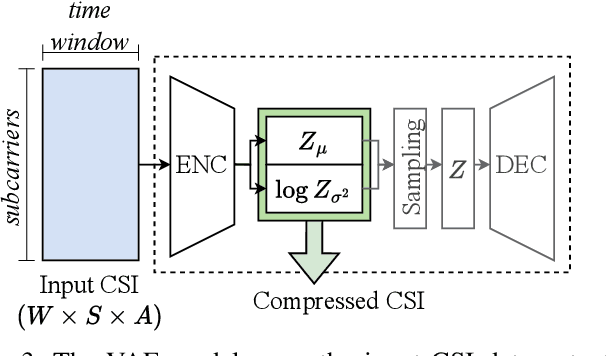
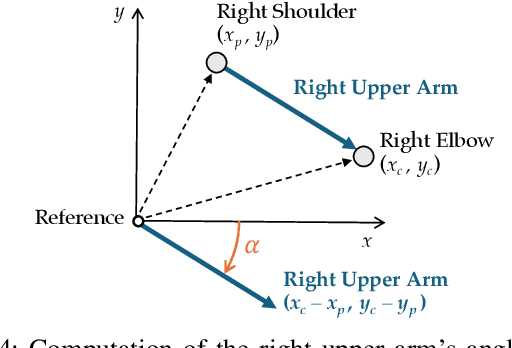
Wi-Fi devices, akin to passive radars, can discern human activities within indoor settings due to the human body's interaction with electromagnetic signals. Current Wi-Fi sensing applications predominantly employ data-driven learning techniques to associate the fluctuations in the physical properties of the communication channel with the human activity causing them. However, these techniques often lack the desired flexibility and transparency. This paper introduces DeepProbHAR, a neuro-symbolic architecture for Wi-Fi sensing, providing initial evidence that Wi-Fi signals can differentiate between simple movements, such as leg or arm movements, which are integral to human activities like running or walking. The neuro-symbolic approach affords gathering such evidence without needing additional specialised data collection or labelling. The training of DeepProbHAR is facilitated by declarative domain knowledge obtained from a camera feed and by fusing signals from various antennas of the Wi-Fi receivers. DeepProbHAR achieves results comparable to the state-of-the-art in human activity recognition. Moreover, as a by-product of the learning process, DeepProbHAR generates specialised classifiers for simple movements that match the accuracy of models trained on finely labelled datasets, which would be particularly costly.
Hybrid Spiking Neural Network Fine-tuning for Hippocampus Segmentation
Feb 14, 2023



Over the past decade, artificial neural networks (ANNs) have made tremendous advances, in part due to the increased availability of annotated data. However, ANNs typically require significant power and memory consumptions to reach their full potential. Spiking neural networks (SNNs) have recently emerged as a low-power alternative to ANNs due to their sparsity nature. SNN, however, are not as easy to train as ANNs. In this work, we propose a hybrid SNN training scheme and apply it to segment human hippocampi from magnetic resonance images. Our approach takes ANN-SNN conversion as an initialization step and relies on spike-based backpropagation to fine-tune the network. Compared with the conversion and direct training solutions, our method has advantages in both segmentation accuracy and training efficiency. Experiments demonstrate the effectiveness of our model in achieving the design goals.
Evaluating the temporal understanding of neural networks on event-based action recognition with DVS-Gesture-Chain
Sep 29, 2022

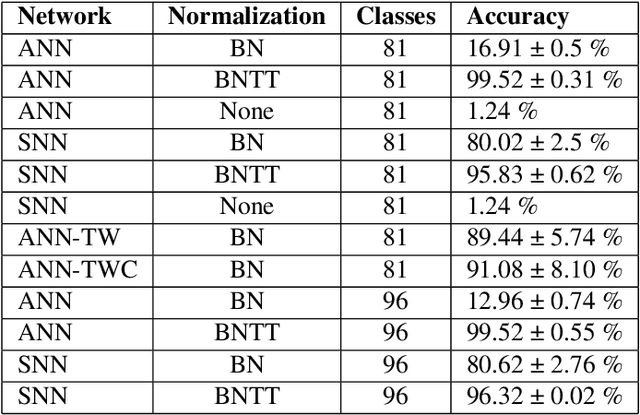

Enabling artificial neural networks (ANNs) to have temporal understanding in visual tasks is an essential requirement in order to achieve complete perception of video sequences. A wide range of benchmark datasets is available to allow for the evaluation of such capabilities when using conventional frame-based video sequences. In contrast, evaluating them for systems targeting neuromorphic data is still a challenge due to the lack of appropriate datasets. In this work we define a new benchmark task for action recognition in event-based video sequences, DVS-Gesture-Chain (DVS-GC), which is based on the temporal combination of multiple gestures from the widely used DVS-Gesture dataset. This methodology allows to create datasets that are arbitrarily complex in the temporal dimension. Using our newly defined task, we evaluate the spatio-temporal understanding of different feed-forward convolutional ANNs and convolutional Spiking Neural Networks (SNNs). Our study proves how the original DVS Gesture benchmark could be solved by networks without temporal understanding, unlike the new DVS-GC which demands an understanding of the ordering of events. From there, we provide a study showing how certain elements such as spiking neurons or time-dependent weights allow for temporal understanding in feed-forward networks without the need for recurrent connections. Code available at: https://github.com/VicenteAlex/DVS-Gesture-Chain
Zero-shot visual reasoning through probabilistic analogical mapping
Sep 29, 2022
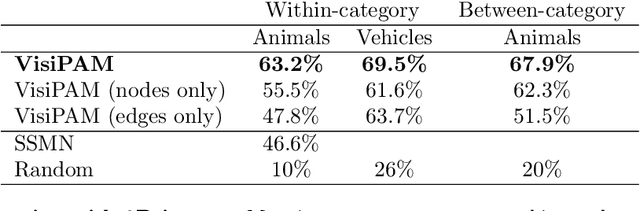


Human reasoning is grounded in an ability to identify highly abstract commonalities governing superficially dissimilar visual inputs. Recent efforts to develop algorithms with this capacity have largely focused on approaches that require extensive direct training on visual reasoning tasks, and yield limited generalization to problems with novel content. In contrast, a long tradition of research in cognitive science has focused on elucidating the computational principles underlying human analogical reasoning; however, this work has generally relied on manually constructed representations. Here we present visiPAM (visual Probabilistic Analogical Mapping), a model of visual reasoning that synthesizes these two approaches. VisiPAM employs learned representations derived directly from naturalistic visual inputs, coupled with a similarity-based mapping operation derived from cognitive theories of human reasoning. We show that without any direct training, visiPAM outperforms a state-of-the-art deep learning model on an analogical mapping task. In addition, visiPAM closely matches the pattern of human performance on a novel task involving mapping of 3D objects across disparate categories.
Keys to Accurate Feature Extraction Using Residual Spiking Neural Networks
Nov 12, 2021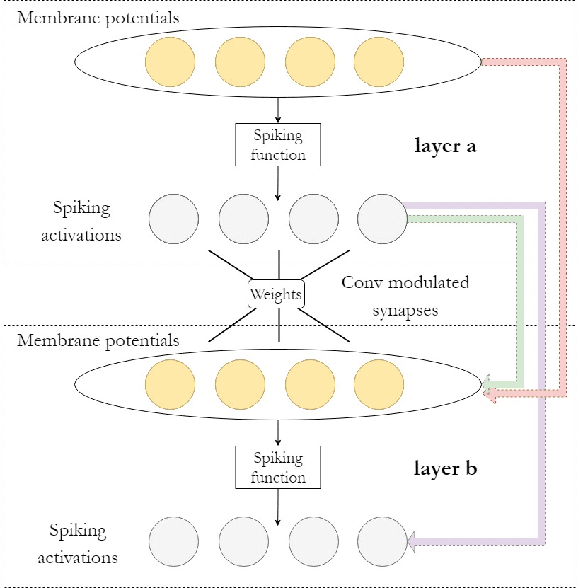
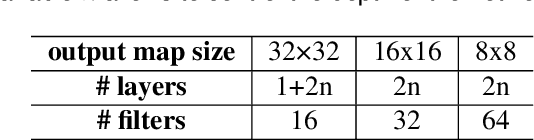
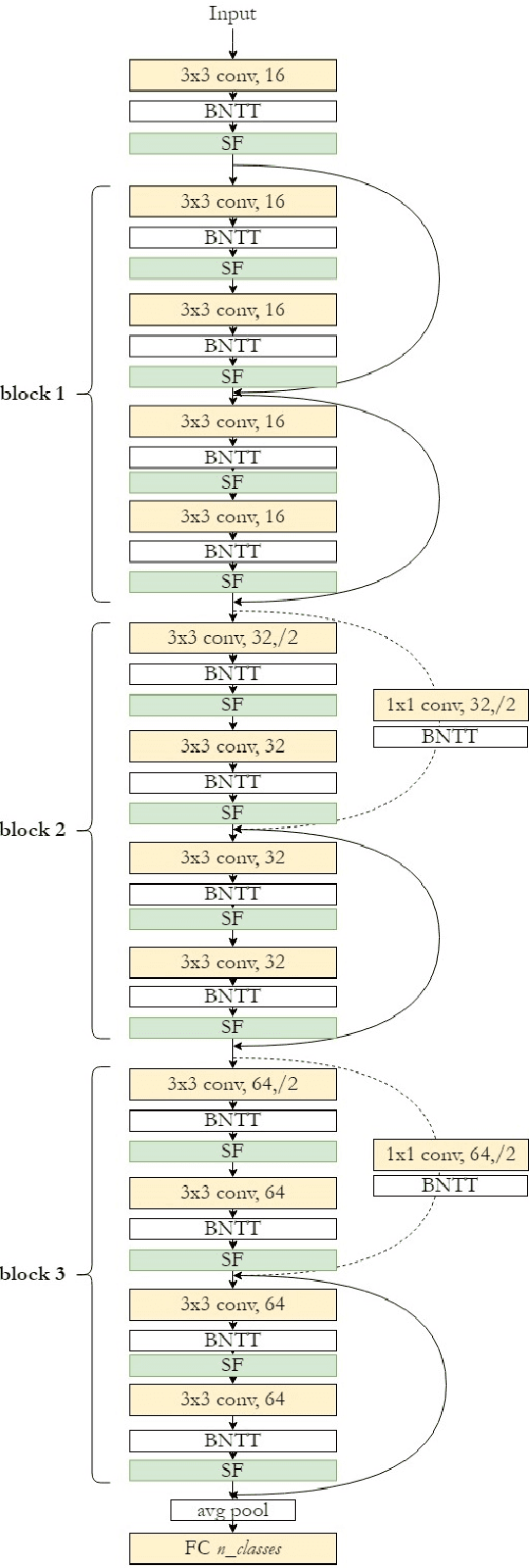

Spiking neural networks (SNNs) have become an interesting alternative to conventional artificial neural networks (ANN) thanks to their temporal processing capabilities and their low-SWaP (Size, Weight, and Power) and energy efficient implementations in neuromorphic hardware. However the challenges involved in training SNNs have limited their performance in terms of accuracy and thus their applications. Improving learning algorithms and neural architectures for a more accurate feature extraction is therefore one of the current priorities in SNN research. In this paper we present a study on the key components of modern spiking architectures. We empirically compare different techniques in image classification datasets taken from the best performing networks. We design a spiking version of the successful residual network (ResNet) architecture and test different components and training strategies on it. Our results provide a state of the art guide to SNN design, which allows to make informed choices when trying to build the optimal visual feature extractor. Finally, our network outperforms previous SNN architectures in CIFAR-10 (94.1%) and CIFAR-100 (74.5%) datasets and matches the state of the art in DVS-CIFAR10 (71.3%), with less parameters than the previous state of the art and without the need for ANN-SNN conversion. Code available at https://github.com/VicenteAlex/Spiking_ResNet.