 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-aware Classification via Uncertainty Quantification
Dec 04, 2024



Autonomous and semi-autonomous systems are using deep learning models to improve decision-making. However, deep classifiers can be overly confident in their incorrect predictions, a major issue especially in safety-critical domains. The present study introduces three foundational desiderata for developing real-world risk-aware classification systems. Expanding upon the previously proposed Evidential Deep Learning (EDL), we demonstrate the unity between these principles and EDL's operational attributes. We then augment EDL empowering autonomous agents to exercise discretion during structured decision-making when uncertainty and risks are inherent. We rigorously examine empirical scenarios to substantiate these theoretical innovations. In contrast to existing risk-aware classifiers, our proposed methodologies consistently exhibit superior performance, underscoring their transformative potential in risk-conscious classification strategies.
Neuro-Symbolic Fusion of Wi-Fi Sensing Data for Passive Radar with Inter-Modal Knowledge Transfer
Jul 01, 2024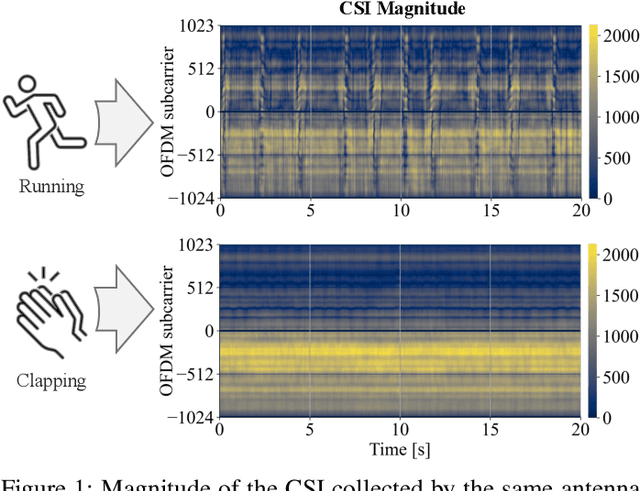
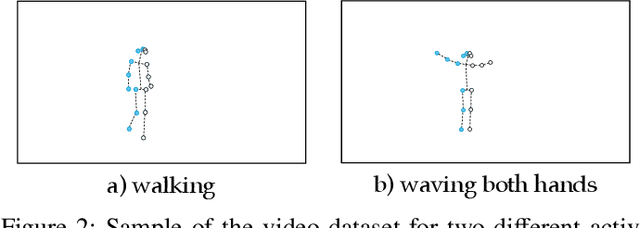
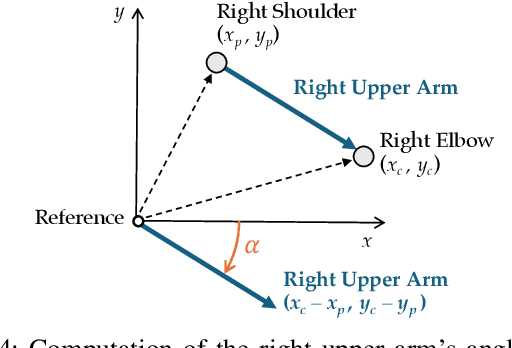
Wi-Fi devices, akin to passive radars, can discern human activities within indoor settings due to the human body's interaction with electromagnetic signals. Current Wi-Fi sensing applications predominantly employ data-driven learning techniques to associate the fluctuations in the physical properties of the communication channel with the human activity causing them. However, these techniques often lack the desired flexibility and transparency. This paper introduces DeepProbHAR, a neuro-symbolic architecture for Wi-Fi sensing, providing initial evidence that Wi-Fi signals can differentiate between simple movements, such as leg or arm movements, which are integral to human activities like running or walking. The neuro-symbolic approach affords gathering such evidence without needing additional specialised data collection or labelling. The training of DeepProbHAR is facilitated by declarative domain knowledge obtained from a camera feed and by fusing signals from various antennas of the Wi-Fi receivers. DeepProbHAR achieves results comparable to the state-of-the-art in human activity recognition. Moreover, as a by-product of the learning process, DeepProbHAR generates specialised classifiers for simple movements that match the accuracy of models trained on finely labelled datasets, which would be particularly costly.
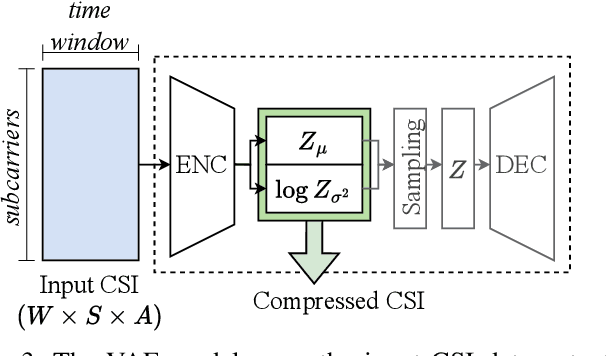
Accurate Passive Radar via an Uncertainty-Aware Fusion of Wi-Fi Sensing Data
Jul 01, 2024Wi-Fi devices can effectively be used as passive radar systems that sense what happens in the surroundings and can even discern human activity. We propose, for the first time, a principled architecture which employs Variational Auto-Encoders for estimating a latent distribution responsible for generating the data, and Evidential Deep Learning for its ability to sense out-of-distribution activities. We verify that the fused data processed by different antennas of the same Wi-Fi receiver results in increased accuracy of human activity recognition compared with the most recent benchmarks, while still being informative when facing out-of-distribution samples and enabling semantic interpretation of latent variables in terms of physical phenomena. The results of this paper are a first contribution toward the ultimate goal of providing a flexible, semantic characterisation of black-swan events, i.e., events for which we have limited to no training data.
Hyper Evidential Deep Learning to Quantify Composite Classification Uncertainty
Apr 17, 2024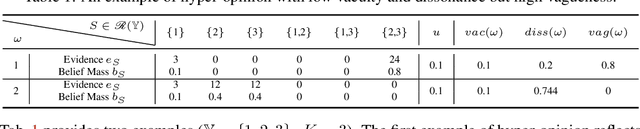
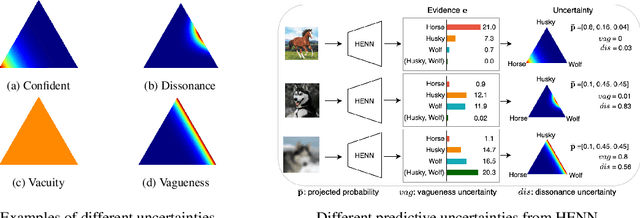
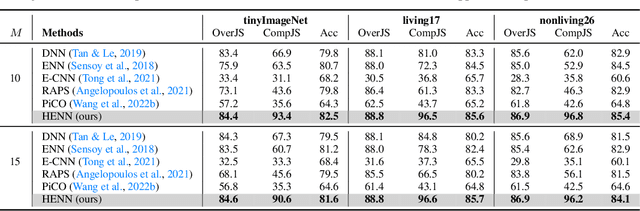
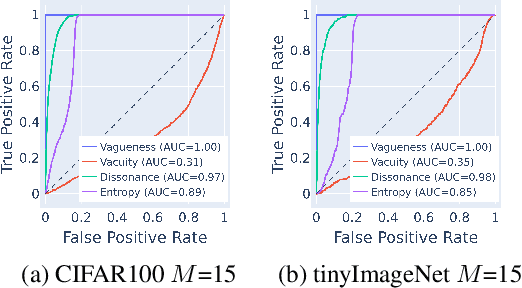
Deep neural networks (DNNs) have been shown to perform well on exclusive, multi-class classification tasks. However, when different classes have similar visual features, it becomes challenging for human annotators to differentiate them. This scenario necessitates the use of composite class labels. In this paper, we propose a novel framework called Hyper-Evidential Neural Network (HENN) that explicitly models predictive uncertainty due to composite class labels in training data in the context of the belief theory called Subjective Logic (SL). By placing a grouped Dirichlet distribution on the class probabilities, we treat predictions of a neural network as parameters of hyper-subjective opinions and learn the network that collects both single and composite evidence leading to these hyper-opinions by a deterministic DNN from data. We introduce a new uncertainty type called vagueness originally designed for hyper-opinions in SL to quantify composite classification uncertainty for DNNs. Our results demonstrate that HENN outperforms its state-of-the-art counterparts based on four image datasets. The code and datasets are available at: https://github.com/Hugo101/HyperEvidentialNN.
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024



Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.
Knowledge from Uncertainty in Evidential Deep Learning
Oct 19, 2023This work reveals an evidential signal that emerges from the uncertainty value in Evidential Deep Learning (EDL). EDL is one example of a class of uncertainty-aware deep learning approaches designed to provide confidence (or epistemic uncertainty) about the current test sample. In particular for computer vision and bidirectional encoder large language models, the `evidential signal' arising from the Dirichlet strength in EDL can, in some cases, discriminate between classes, which is particularly strong when using large language models. We hypothesise that the KL regularisation term causes EDL to couple aleatoric and epistemic uncertainty. In this paper, we empirically investigate the correlations between misclassification and evaluated uncertainty, and show that EDL's `evidential signal' is due to misclassification bias. We critically evaluate EDL with other Dirichlet-based approaches, namely Generative Evidential Neural Networks (EDL-GEN) and Prior Networks, and show theoretically and empirically the differences between these loss functions. We conclude that EDL's coupling of uncertainty arises from these differences due to the use (or lack) of out-of-distribution samples during training.
Uncertainty-Aware Reward-based Deep Reinforcement Learning for Intent Analysis of Social Media Information
Feb 19, 2023Due to various and serious adverse impacts of spreading fake news, it is often known that only people with malicious intent would propagate fake news. However, it is not necessarily true based on social science studies. Distinguishing the types of fake news spreaders based on their intent is critical because it will effectively guide how to intervene to mitigate the spread of fake news with different approaches. To this end, we propose an intent classification framework that can best identify the correct intent of fake news. We will leverage deep reinforcement learning (DRL) that can optimize the structural representation of each tweet by removing noisy words from the input sequence when appending an actor to the long short-term memory (LSTM) intent classifier. Policy gradient DRL model (e.g., REINFORCE) can lead the actor to a higher delayed reward. We also devise a new uncertainty-aware immediate reward using a subjective opinion that can explicitly deal with multidimensional uncertainty for effective decision-making. Via 600K training episodes from a fake news tweets dataset with an annotated intent class, we evaluate the performance of uncertainty-aware reward in DRL. Evaluation results demonstrate that our proposed framework efficiently reduces the number of selected words to maintain a high 95\% multi-class accuracy.
PPO-UE: Proximal Policy Optimization via Uncertainty-Aware Exploration
Dec 13, 2022Proximal Policy Optimization (PPO) is a highly popular policy-based deep reinforcement learning (DRL) approach. However, we observe that the homogeneous exploration process in PPO could cause an unexpected stability issue in the training phase. To address this issue, we propose PPO-UE, a PPO variant equipped with self-adaptive uncertainty-aware explorations (UEs) based on a ratio uncertainty level. The proposed PPO-UE is designed to improve convergence speed and performance with an optimized ratio uncertainty level. Through extensive sensitivity analysis by varying the ratio uncertainty level, our proposed PPO-UE considerably outperforms the baseline PPO in Roboschool continuous control tasks.
Research Note on Uncertain Probabilities and Abstract Argumentation
Aug 23, 2022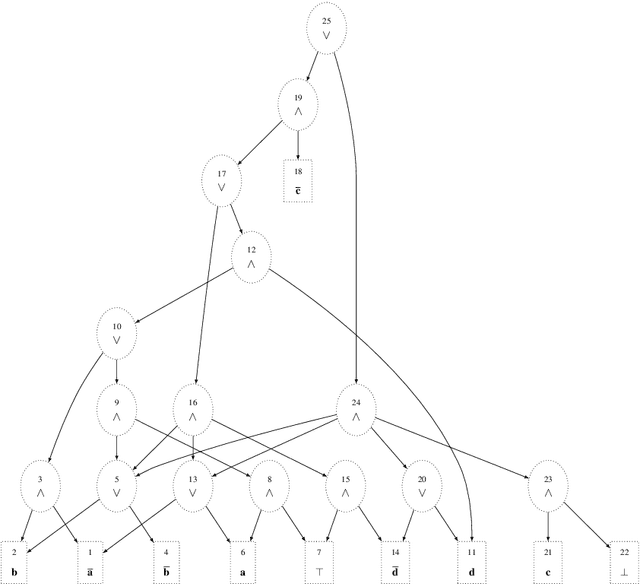
The sixth assessment of the international panel on climate change (IPCC) states that "cumulative net CO2 emissions over the last decade (2010-2019) are about the same size as the 11 remaining carbon budget likely to limit warming to 1.5C (medium confidence)." Such reports directly feed the public discourse, but nuances such as the degree of belief and of confidence are often lost. In this paper, we propose a formal account for allowing such degrees of belief and the associated confidence to be used to label arguments in abstract argumentation settings. Differently from other proposals in probabilistic argumentation, we focus on the task of probabilistic inference over a chosen query building upon Sato's distribution semantics which has been already shown to encompass a variety of cases including the semantics of Bayesian networks. Borrowing from the vast literature on such semantics, we examine how such tasks can be dealt with in practice when considering uncertain probabilities, and discuss the connections with existing proposals for probabilistic argumentation.
SOLBP: Second-Order Loopy Belief Propagation for Inference in Uncertain Bayesian Networks
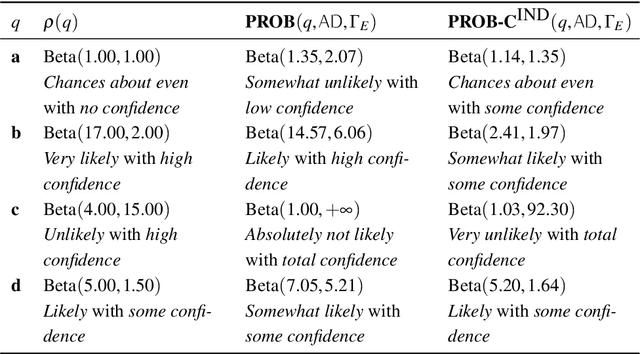
Aug 16, 2022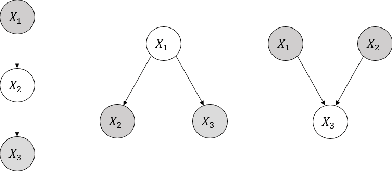
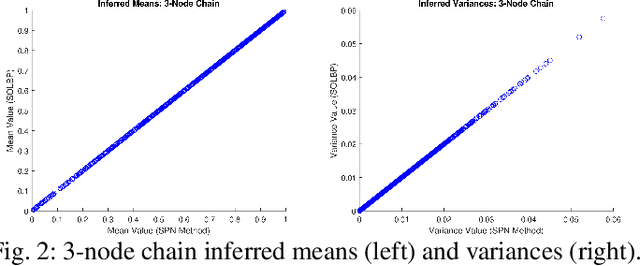
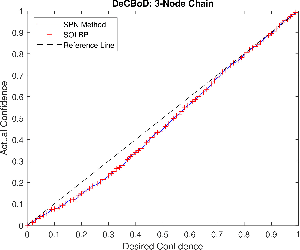
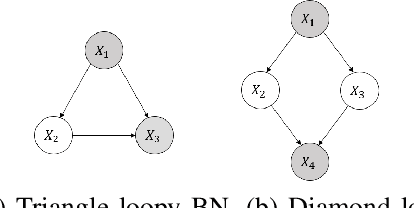
In second-order uncertain Bayesian networks, the conditional probabilities are only known within distributions, i.e., probabilities over probabilities. The delta-method has been applied to extend exact first-order inference methods to propagate both means and variances through sum-product networks derived from Bayesian networks, thereby characterizing epistemic uncertainty, or the uncertainty in the model itself. Alternatively, second-order belief propagation has been demonstrated for polytrees but not for general directed acyclic graph structures. In this work, we extend Loopy Belief Propagation to the setting of second-order Bayesian networks, giving rise to Second-Order Loopy Belief Propagation (SOLBP). For second-order Bayesian networks, SOLBP generates inferences consistent with those generated by sum-product networks, while being more computationally efficient and scalable.