 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidential Uncertainty Probes for Graph Neural Networks
Mar 11, 2025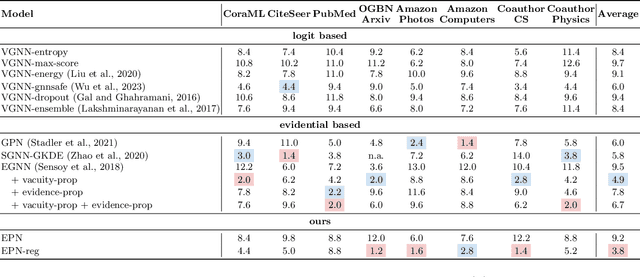
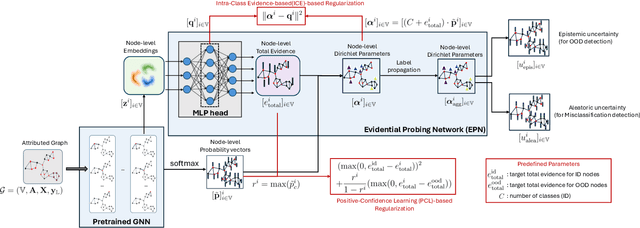
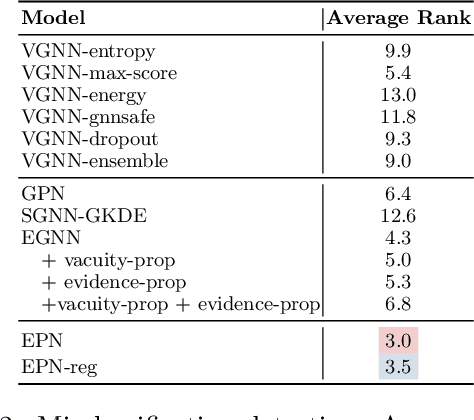
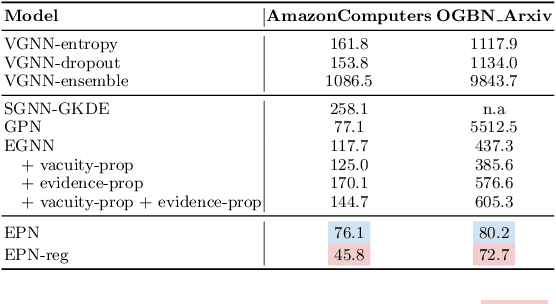
Accurate quantification of both aleatoric and epistemic uncertainties is essential when deploying Graph Neural Networks (GNNs) in high-stakes applications such as drug discovery and financial fraud detection, where reliable predictions are critical. Although Evidential Deep Learning (EDL) efficiently quantifies uncertainty using a Dirichlet distribution over predictive probabilities, existing EDL-based GNN (EGNN) models require modifications to the network architecture and retraining, failing to take advantage of pre-trained models. We propose a plug-and-play framework for uncertainty quantification in GNNs that works with pre-trained models without the need for retraining. Our Evidential Probing Network (EPN) uses a lightweight Multi-Layer-Perceptron (MLP) head to extract evidence from learned representations, allowing efficient integration with various GNN architectures. We further introduce evidence-based regularization techniques, referred to as EPN-reg, to enhance the estimation of epistemic uncertainty with theoretical justifications. Extensive experiments demonstrate that the proposed EPN-reg achieves state-of-the-art performance in accurate and efficient uncertainty quantification, making it suitable for real-world deployment.
Federated In-Context LLM Agent Learning
Dec 11, 2024



Large Language Models (LLMs) have revolutionized intelligent services by enabling logical reasoning, tool use, and interaction with external systems as agents. The advancement of LLMs is frequently hindered by the scarcity of high-quality data, much of which is inherently sensitive. Federated learning (FL) offers a potential solution by facilitating the collaborative training of distributed LLMs while safeguarding private data. However, FL frameworks face significant bandwidth and computational demands, along with challenges from heterogeneous data distributions. The emerging in-context learning capability of LLMs offers a promising approach by aggregating natural language rather than bulky model parameters. Yet, this method risks privacy leakage, as it necessitates the collection and presentation of data samples from various clients during aggregation. In this paper, we propose a novel privacy-preserving Federated In-Context LLM Agent Learning (FICAL) algorithm, which to our best knowledge for the first work unleashes the power of in-context learning to train diverse LLM agents through FL. In our design, knowledge compendiums generated by a novel LLM-enhanced Knowledge Compendiums Generation (KCG) module are transmitted between clients and the server instead of model parameters in previous FL methods. Apart from that, an incredible Retrieval Augmented Generation (RAG) based Tool Learning and Utilizing (TLU) module is designed and we incorporate the aggregated global knowledge compendium as a teacher to teach LLM agents the usage of tools. We conducted extensive experiments and the results show that FICAL has competitive performance compared to other SOTA baselines with a significant communication cost decrease of $\mathbf{3.33\times10^5}$ times.
Uncertainty Quantification for Bird's Eye View Semantic Segmentation: Methods and Benchmarks
May 31, 2024



The fusion of raw features from multiple sensors on an autonomous vehicle to create a Bird's Eye View (BEV) representation is crucial for planning and control systems. There is growing interest in using deep learning models for BEV semantic segmentation. Anticipating segmentation errors and improving the explainability of DNNs is essential for autonomous driving, yet it is under-studied. This paper introduces a benchmark for predictive uncertainty quantification in BEV segmentation. The benchmark assesses various approaches across three popular datasets using two representative backbones and focuses on the effectiveness of predicted uncertainty in identifying misclassified and out-of-distribution (OOD) pixels, as well as calibration. Empirical findings highlight the challenges in uncertainty quantification. Our results find that evidential deep learning based approaches show the most promise by efficiently quantifying aleatoric and epistemic uncertainty. We propose the Uncertainty-Focal-Cross-Entropy (UFCE) loss, designed for highly imbalanced data, which consistently improves the segmentation quality and calibration. Additionally, we introduce a vacuity-scaled regularization term that enhances the model's focus on high uncertainty pixels, improving epistemic uncertainty quantification.
Hyper Evidential Deep Learning to Quantify Composite Classification Uncertainty
Apr 17, 2024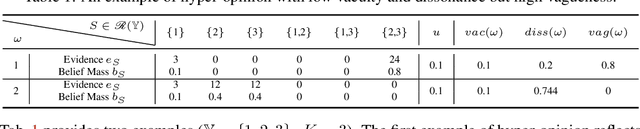
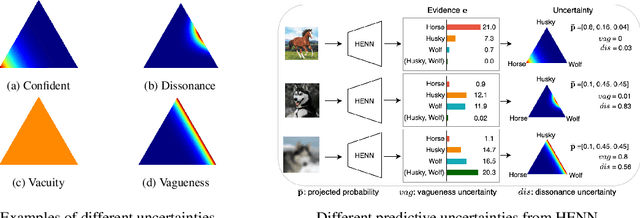
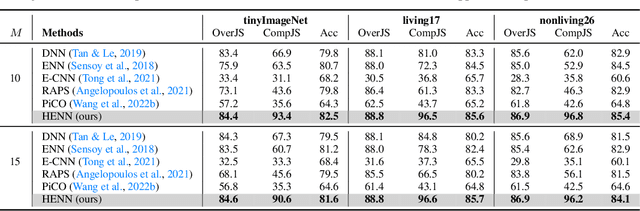
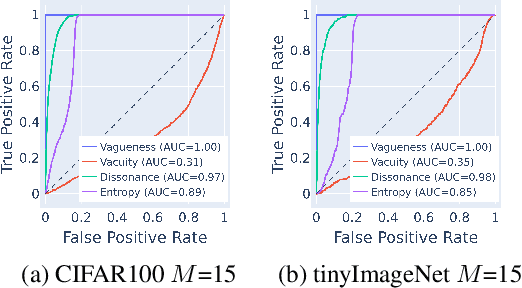
Deep neural networks (DNNs) have been shown to perform well on exclusive, multi-class classification tasks. However, when different classes have similar visual features, it becomes challenging for human annotators to differentiate them. This scenario necessitates the use of composite class labels. In this paper, we propose a novel framework called Hyper-Evidential Neural Network (HENN) that explicitly models predictive uncertainty due to composite class labels in training data in the context of the belief theory called Subjective Logic (SL). By placing a grouped Dirichlet distribution on the class probabilities, we treat predictions of a neural network as parameters of hyper-subjective opinions and learn the network that collects both single and composite evidence leading to these hyper-opinions by a deterministic DNN from data. We introduce a new uncertainty type called vagueness originally designed for hyper-opinions in SL to quantify composite classification uncertainty for DNNs. Our results demonstrate that HENN outperforms its state-of-the-art counterparts based on four image datasets. The code and datasets are available at: https://github.com/Hugo101/HyperEvidentialNN.
FedMS: Federated Learning with Mixture of Sparsely Activated Foundations Models
Dec 26, 2023Foundation models have shown great success in natural language processing, computer vision, and multimodal tasks. FMs have a large number of model parameters, thus requiring a substantial amount of data to help optimize the model during the training. Federated learning has revolutionized machine learning by enabling collaborative learning from decentralized data while still preserving the data privacy of clients. Despite the great benefits foundation models can have empowered by federated learning, they face severe computation, communication, and statistical challenges. In this paper, we propose a novel two-stage federated learning algorithm called FedMS. A global expert is trained in the first stage and a local expert is trained in the second stage to provide better personalization. We construct a Mixture of Foundation Models (MoFM) with these two experts and design a gate neural network with an inserted gate adapter that joins the aggregation every communication round in the second stage. To further adapt to edge computing scenarios with limited computational resources, we design a novel Sparsely Activated LoRA (SAL) algorithm that freezes the pre-trained foundation model parameters inserts low-rank adaptation matrices into transformer blocks and activates them progressively during the training. We employ extensive experiments to verify the effectiveness of FedMS, results show that FedMS outperforms other SOTA baselines by up to 55.25% in default settings.