 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan We Trust the Performance Evaluation of Uncertainty Estimation Methods in Text Summarization?
Jun 25, 2024Text summarization, a key natural language generation (NLG) task, is vital in various domains. However, the high cost of inaccurate summaries in risk-critical applications, particularly those involving human-in-the-loop decision-making, raises concerns about the reliability of uncertainty estimation on text summarization (UE-TS) evaluation methods. This concern stems from the dependency of uncertainty model metrics on diverse and potentially conflicting NLG metrics. To address this issue, we introduce a comprehensive UE-TS benchmark incorporating 31 NLG metrics across four dimensions. The benchmark evaluates the uncertainty estimation capabilities of two large language models and one pre-trained language model on three datasets, with human-annotation analysis incorporated where applicable. We also assess the performance of 14 common uncertainty estimation methods within this benchmark. Our findings emphasize the importance of considering multiple uncorrelated NLG metrics and diverse uncertainty estimation methods to ensure reliable and efficient evaluation of UE-TS techniques.
Hyper Evidential Deep Learning to Quantify Composite Classification Uncertainty
Apr 17, 2024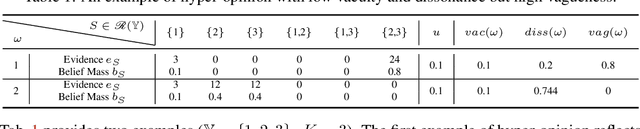
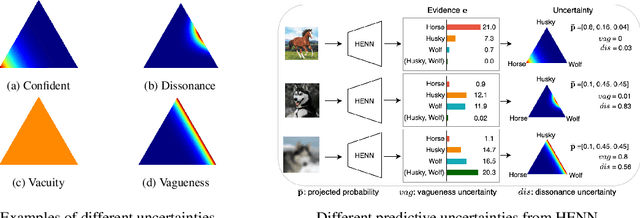
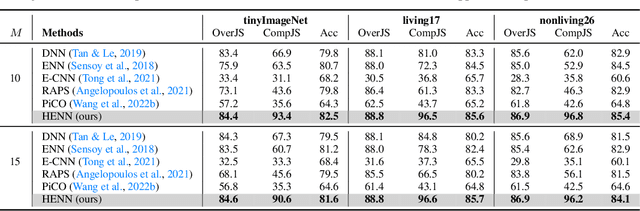
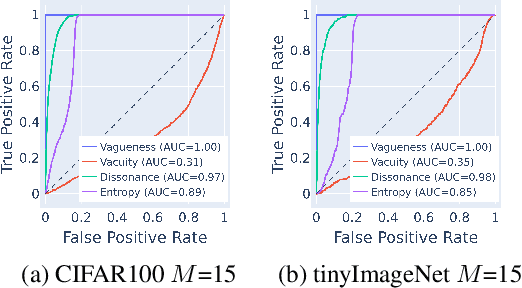
Deep neural networks (DNNs) have been shown to perform well on exclusive, multi-class classification tasks. However, when different classes have similar visual features, it becomes challenging for human annotators to differentiate them. This scenario necessitates the use of composite class labels. In this paper, we propose a novel framework called Hyper-Evidential Neural Network (HENN) that explicitly models predictive uncertainty due to composite class labels in training data in the context of the belief theory called Subjective Logic (SL). By placing a grouped Dirichlet distribution on the class probabilities, we treat predictions of a neural network as parameters of hyper-subjective opinions and learn the network that collects both single and composite evidence leading to these hyper-opinions by a deterministic DNN from data. We introduce a new uncertainty type called vagueness originally designed for hyper-opinions in SL to quantify composite classification uncertainty for DNNs. Our results demonstrate that HENN outperforms its state-of-the-art counterparts based on four image datasets. The code and datasets are available at: https://github.com/Hugo101/HyperEvidentialNN.
PLATINUM: Semi-Supervised Model Agnostic Meta-Learning using Submodular Mutual Information
Jan 30, 2022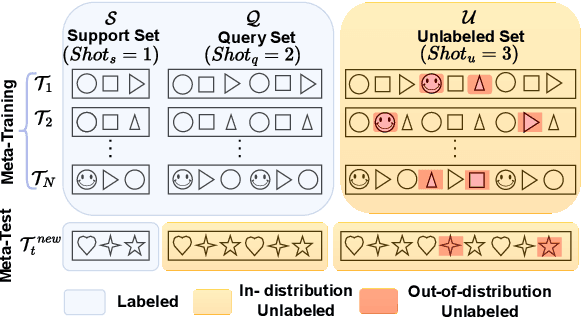

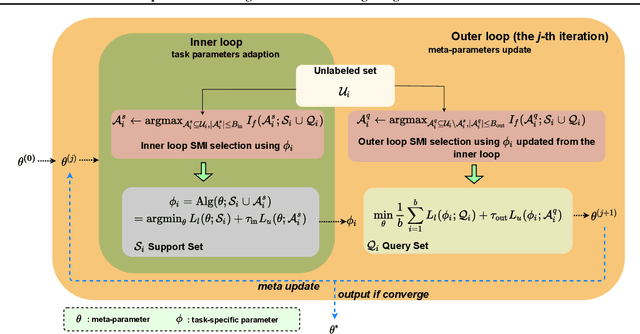
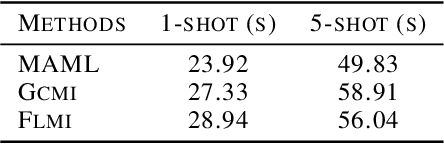
Few-shot classification (FSC) requires training models using a few (typically one to five) data points per class. Meta learning has proven to be able to learn a parametrized model for FSC by training on various other classification tasks. In this work, we propose PLATINUM (semi-suPervised modeL Agnostic meTa-learnIng usiNg sUbmodular Mutual information), a novel semi-supervised model agnostic meta-learning framework that uses the submodular mutual information (SMI) functions to boost the performance of FSC. PLATINUM leverages unlabeled data in the inner and outer loop using SMI functions during meta-training and obtains richer meta-learned parameterizations for meta-test. We study the performance of PLATINUM in two scenarios - 1) where the unlabeled data points belong to the same set of classes as the labeled set of a certain episode, and 2) where there exist out-of-distribution classes that do not belong to the labeled set. We evaluate our method on various settings on the miniImageNet, tieredImageNet and Fewshot-CIFAR100 datasets. Our experiments show that PLATINUM outperforms MAML and semi-supervised approaches like pseduo-labeling for semi-supervised FSC, especially for small ratio of labeled examples per class.
A Reweighted Meta Learning Framework for Robust Few Shot Learning
Nov 13, 2020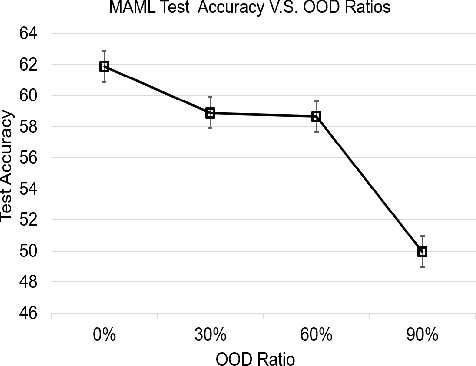
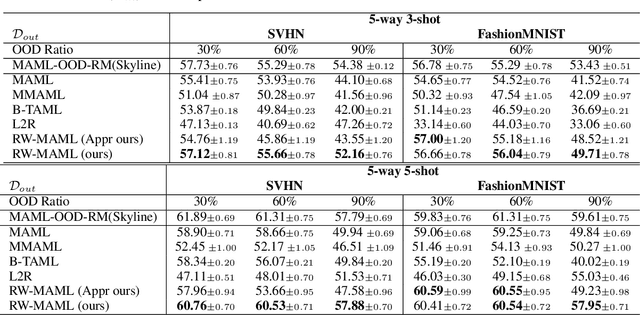
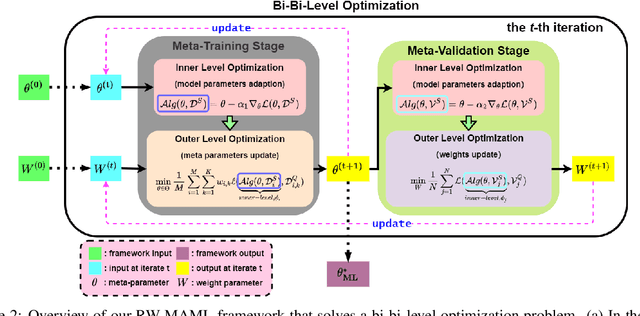

Model-Agnostic Meta-Learning (MAML) is a popular gradient-based meta-learning framework that tries to find an optimal initialization to minimize the expected loss across all tasks during meta-training. However, it inherently assumes that the contribution of each instance/task to the meta-learner is equal. Therefore, it fails to address the problem of domain differences between base and novel classes in few-shot learning. In this work, we propose a novel and robust meta-learning algorithm, called RW-MAML, which learns to assign weights to training instances or tasks. We consider these weights to be hyper-parameters. Hence, we iteratively optimize the weights using a small set of validation tasks and an online approximation in a \emph{bi-bi-level} optimization framework, in contrast to the standard bi-level optimization in MAML. Therefore, we investigate a practical evaluation setting to demonstrate the scalability of our RW-MAML in two scenarios: (1) out-of-distribution tasks and (2) noisy labels in the meta-training stage. Extensive experiments on synthetic and real-world datasets demonstrate that our framework efficiently mitigates the effects of "unwanted" instances, showing that our proposed technique significantly outperforms state-of-the-art robust meta-learning methods.
Fair Meta-Learning For Few-Shot Classification
Sep 23, 2020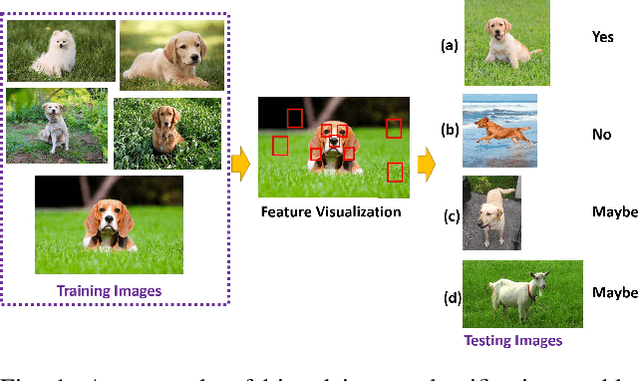
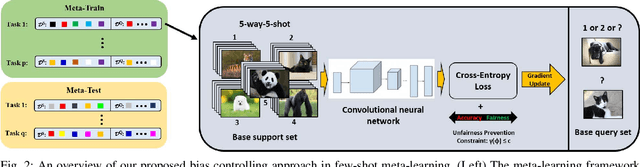
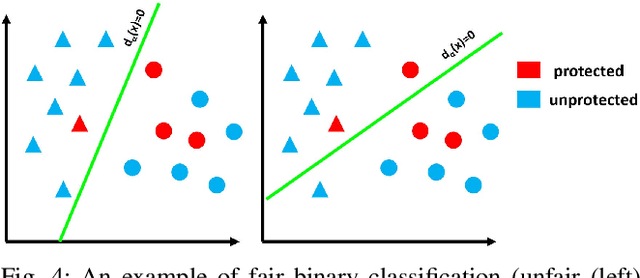
Artificial intelligence nowadays plays an increasingly prominent role in our life since decisions that were once made by humans are now delegated to automated systems. A machine learning algorithm trained based on biased data, however, tends to make unfair predictions. Developing classification algorithms that are fair with respect to protected attributes of the data thus becomes an important problem. Motivated by concerns surrounding the fairness effects of sharing and few-shot machine learning tools, such as the Model Agnostic Meta-Learning framework, we propose a novel fair fast-adapted few-shot meta-learning approach that efficiently mitigates biases during meta-train by ensuring controlling the decision boundary covariance that between the protected variable and the signed distance from the feature vectors to the decision boundary. Through extensive experiments on two real-world image benchmarks over three state-of-the-art meta-learning algorithms, we empirically demonstrate that our proposed approach efficiently mitigates biases on model output and generalizes both accuracy and fairness to unseen tasks with a limited amount of training samples.