 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reweighted Meta Learning Framework for Robust Few Shot Learning
Paper and Code
Nov 13, 2020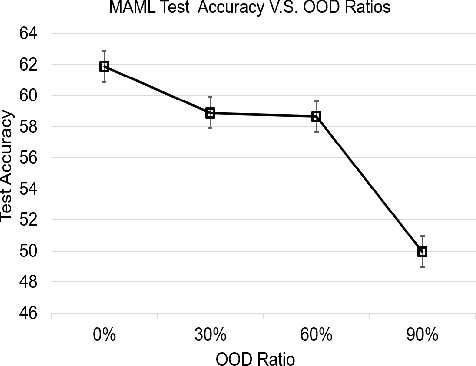
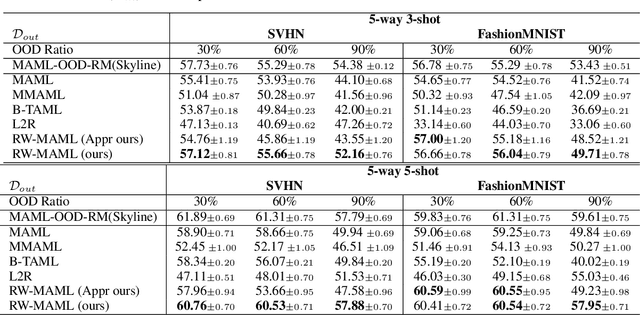
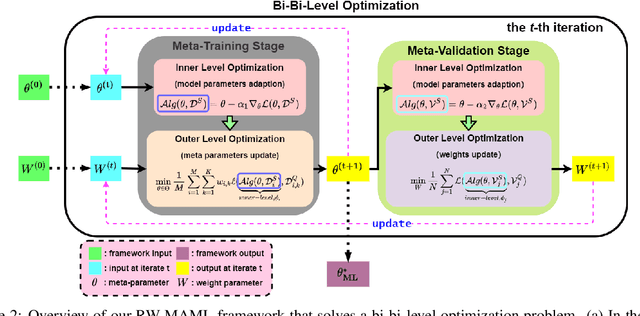

Model-Agnostic Meta-Learning (MAML) is a popular gradient-based meta-learning framework that tries to find an optimal initialization to minimize the expected loss across all tasks during meta-training. However, it inherently assumes that the contribution of each instance/task to the meta-learner is equal. Therefore, it fails to address the problem of domain differences between base and novel classes in few-shot learning. In this work, we propose a novel and robust meta-learning algorithm, called RW-MAML, which learns to assign weights to training instances or tasks. We consider these weights to be hyper-parameters. Hence, we iteratively optimize the weights using a small set of validation tasks and an online approximation in a \emph{bi-bi-level} optimization framework, in contrast to the standard bi-level optimization in MAML. Therefore, we investigate a practical evaluation setting to demonstrate the scalability of our RW-MAML in two scenarios: (1) out-of-distribution tasks and (2) noisy labels in the meta-training stage. Extensive experiments on synthetic and real-world datasets demonstrate that our framework efficiently mitigates the effects of "unwanted" instances, showing that our proposed technique significantly outperforms state-of-the-art robust meta-learning methods.