 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-POSER: Reflective RL for Multi-Expert Image Generation and Editing
Nov 15, 2025
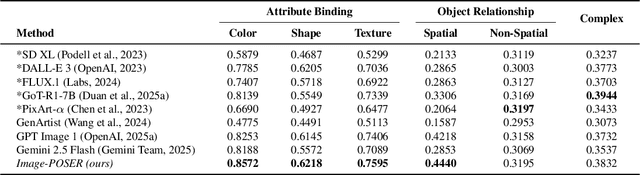
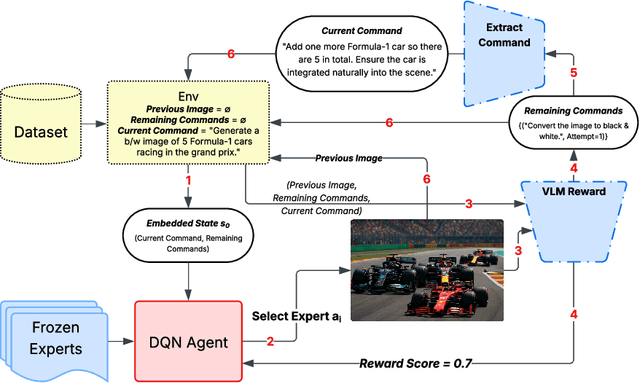
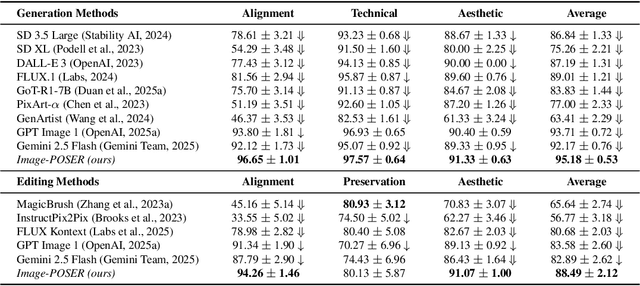
Recent advances in text-to-image generation have produced strong single-shot models, yet no individual system reliably executes the long, compositional prompts typical of creative workflows. We introduce Image-POSER, a reflective reinforcement learning framework that (i) orchestrates a diverse registry of pretrained text-to-image and image-to-image experts, (ii) handles long-form prompts end-to-end through dynamic task decomposition, and (iii) supervises alignment at each step via structured feedback from a vision-language model critic. By casting image synthesis and editing as a Markov Decision Process, we learn non-trivial expert pipelines that adaptively combine strengths across models. Experiments show that Image-POSER outperforms baselines, including frontier models, across industry-standard and custom benchmarks in alignment, fidelity, and aesthetics, and is consistently preferred in human evaluations. These results highlight that reinforcement learning can endow AI systems with the capacity to autonomously decompose, reorder, and combine visual models, moving towards general-purpose visual assistants.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Layered Diffusion Model for One-Shot High Resolution Text-to-Image Synthesis
Jul 08, 2024
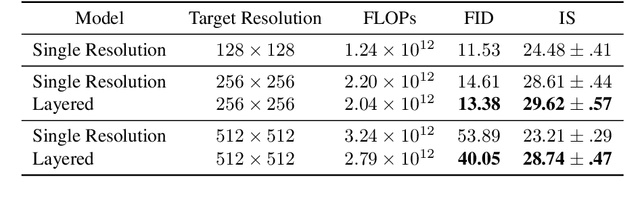


We present a one-shot text-to-image diffusion model that can generate high-resolution images from natural language descriptions. Our model employs a layered U-Net architecture that simultaneously synthesizes images at multiple resolution scales. We show that this method outperforms the baseline of synthesizing images only at the target resolution, while reducing the computational cost per step. We demonstrate that higher resolution synthesis can be achieved by layering convolutions at additional resolution scales, in contrast to other methods which require additional models for super-resolution synthesis.
Source-Free Domain Adaptation with Diffusion-Guided Source Data Generation
Feb 07, 2024



This paper introduces a novel approach to leverage the generalizability capability of Diffusion Models for Source-Free Domain Adaptation (DM-SFDA). Our proposed DM-SFDA method involves fine-tuning a pre-trained text-to-image diffusion model to generate source domain images using features from the target images to guide the diffusion process. Specifically, the pre-trained diffusion model is fine-tuned to generate source samples that minimize entropy and maximize confidence for the pre-trained source model. We then apply established unsupervised domain adaptation techniques to align the generated source images with target domain data. We validate our approach through comprehensive experiments across a range of datasets, including Office-31, Office-Home, and VisDA. The results highlight significant improvements in SFDA performance, showcasing the potential of diffusion models in generating contextually relevant, domain-specific images.
Transcending Domains through Text-to-Image Diffusion: A Source-Free Approach to Domain Adaptation
Oct 14, 2023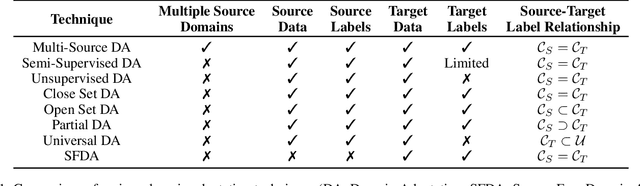
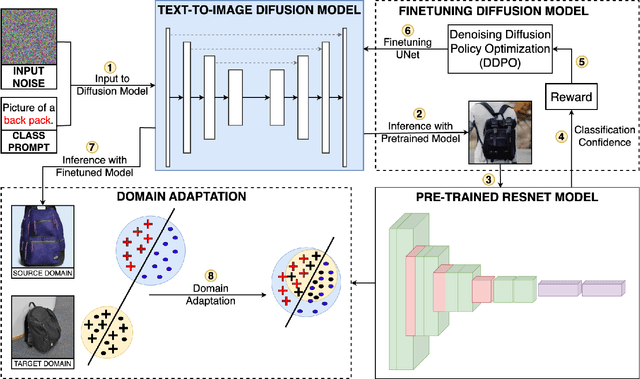

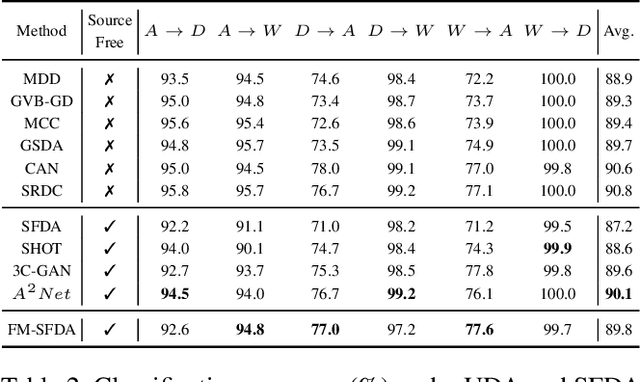
Domain Adaptation (DA) is a method for enhancing a model's performance on a target domain with inadequate annotated data by applying the information the model has acquired from a related source domain with sufficient labeled data. The escalating enforcement of data-privacy regulations like HIPAA, COPPA, FERPA, etc. have sparked a heightened interest in adapting models to novel domains while circumventing the need for direct access to the source data, a problem known as Source-Free Domain Adaptation (SFDA). In this paper, we propose a novel framework for SFDA that generates source data using a text-to-image diffusion model trained on the target domain samples. Our method starts by training a text-to-image diffusion model on the labeled target domain samples, which is then fine-tuned using the pre-trained source model to generate samples close to the source data. Finally, we use Domain Adaptation techniques to align the artificially generated source data with the target domain data, resulting in significant performance improvements of the model on the target domain. Through extensive comparison against several baselines on the standard Office-31, Office-Home, and VisDA benchmarks, we demonstrate the effectiveness of our approach for the SFDA task.
SCoRe: Submodular Combinatorial Representation Learning for Real-World Class-Imbalanced Settings
Sep 29, 2023



Representation Learning in real-world class-imbalanced settings has emerged as a challenging task in the evolution of deep learning. Lack of diversity in visual and structural features for rare classes restricts modern neural networks to learn discriminative feature clusters. This manifests in the form of large inter-class bias between rare object classes and elevated intra-class variance among abundant classes in the dataset. Although deep metric learning approaches have shown promise in this domain, significant improvements need to be made to overcome the challenges associated with class-imbalance in mission critical tasks like autonomous navigation and medical diagnostics. Set-based combinatorial functions like Submodular Information Measures exhibit properties that allow them to simultaneously model diversity and cooperation among feature clusters. In this paper, we introduce the SCoRe (Submodular Combinatorial Representation Learning) framework and propose a family of Submodular Combinatorial Loss functions to overcome these pitfalls in contrastive learning. We also show that existing contrastive learning approaches are either submodular or can be re-formulated to create their submodular counterparts. We conduct experiments on the newly introduced family of combinatorial objectives on two image classification benchmarks - pathologically imbalanced CIFAR-10, subsets of MedMNIST and a real-world road object detection benchmark - India Driving Dataset (IDD). Our experiments clearly show that the newly introduced objectives like Facility Location, Graph-Cut and Log Determinant outperform state-of-the-art metric learners by up to 7.6% for the imbalanced classification tasks and up to 19.4% for object detection tasks.
Two-Step Active Learning for Instance Segmentation with Uncertainty and Diversity Sampling
Sep 28, 2023


Training high-quality instance segmentation models requires an abundance of labeled images with instance masks and classifications, which is often expensive to procure. Active learning addresses this challenge by striving for optimum performance with minimal labeling cost by selecting the most informative and representative images for labeling. Despite its potential, active learning has been less explored in instance segmentation compared to other tasks like image classification, which require less labeling. In this study, we propose a post-hoc active learning algorithm that integrates uncertainty-based sampling with diversity-based sampling. Our proposed algorithm is not only simple and easy to implement, but it also delivers superior performance on various datasets. Its practical application is demonstrated on a real-world overhead imagery dataset, where it increases the labeling efficiency fivefold.
Beyond Active Learning: Leveraging the Full Potential of Human Interaction via Auto-Labeling, Human Correction, and Human Verification
Jun 02, 2023



Active Learning (AL) is a human-in-the-loop framework to interactively and adaptively label data instances, thereby enabling significant gains in model performance compared to random sampling. AL approaches function by selecting the hardest instances to label, often relying on notions of diversity and uncertainty. However, we believe that these current paradigms of AL do not leverage the full potential of human interaction granted by automated label suggestions. Indeed, we show that for many classification tasks and datasets, most people verifying if an automatically suggested label is correct take $3\times$ to $4\times$ less time than they do changing an incorrect suggestion to the correct label (or labeling from scratch without any suggestion). Utilizing this result, we propose CLARIFIER (aCtive LeARnIng From tIEred haRdness), an Interactive Learning framework that admits more effective use of human interaction by leveraging the reduced cost of verification. By targeting the hard (uncertain) instances with existing AL methods, the intermediate instances with a novel label suggestion scheme using submodular mutual information functions on a per-class basis, and the easy (confident) instances with highest-confidence auto-labeling, CLARIFIER can improve over the performance of existing AL approaches on multiple datasets -- particularly on those that have a large number of classes -- by almost 1.5$\times$ to 2$\times$ in terms of relative labeling cost.
STREAMLINE: Streaming Active Learning for Realistic Multi-Distributional Settings
May 18, 2023



Deep neural networks have consistently shown great performance in several real-world use cases like autonomous vehicles, satellite imaging, etc., effectively leveraging large corpora of labeled training data. However, learning unbiased models depends on building a dataset that is representative of a diverse range of realistic scenarios for a given task. This is challenging in many settings where data comes from high-volume streams, with each scenario occurring in random interleaved episodes at varying frequencies. We study realistic streaming settings where data instances arrive in and are sampled from an episodic multi-distributional data stream. Using submodular information measures, we propose STREAMLINE, a novel streaming active learning framework that mitigates scenario-driven slice imbalance in the working labeled data via a three-step procedure of slice identification, slice-aware budgeting, and data selection. We extensively evaluate STREAMLINE on real-world streaming scenarios for image classification and object detection tasks. We observe that STREAMLINE improves the performance on infrequent yet critical slices of the data over current baselines by up to $5\%$ in terms of accuracy on our image classification tasks and by up to $8\%$ in terms of mAP on our object detection tasks.
CLINICAL: Targeted Active Learning for Imbalanced Medical Image Classification
Oct 04, 2022Training deep learning models on medical datasets that perform well for all classes is a challenging task. It is often the case that a suboptimal performance is obtained on some classes due to the natural class imbalance issue that comes with medical data. An effective way to tackle this problem is by using targeted active learning, where we iteratively add data points to the training data that belong to the rare classes. However, existing active learning methods are ineffective in targeting rare classes in medical datasets. In this work, we propose Clinical (targeted aCtive Learning for ImbalaNced medICal imAge cLassification) a framework that uses submodular mutual information functions as acquisition functions to mine critical data points from rare classes. We apply our framework to a wide-array of medical imaging datasets on a variety of real-world class imbalance scenarios - namely, binary imbalance and long-tail imbalance. We show that Clinical outperforms the state-of-the-art active learning methods by acquiring a diverse set of data points that belong to the rare classes.