 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Layered Diffusion Model for One-Shot High Resolution Text-to-Image Synthesis
Jul 08, 2024
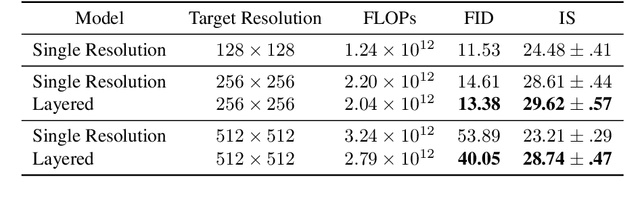


We present a one-shot text-to-image diffusion model that can generate high-resolution images from natural language descriptions. Our model employs a layered U-Net architecture that simultaneously synthesizes images at multiple resolution scales. We show that this method outperforms the baseline of synthesizing images only at the target resolution, while reducing the computational cost per step. We demonstrate that higher resolution synthesis can be achieved by layering convolutions at additional resolution scales, in contrast to other methods which require additional models for super-resolution synthesis.
MaskConver: Revisiting Pure Convolution Model for Panoptic Segmentation
Dec 11, 2023In recent years, transformer-based models have dominated panoptic segmentation, thanks to their strong modeling capabilities and their unified representation for both semantic and instance classes as global binary masks. In this paper, we revisit pure convolution model and propose a novel panoptic architecture named MaskConver. MaskConver proposes to fully unify things and stuff representation by predicting their centers. To that extent, it creates a lightweight class embedding module that can break the ties when multiple centers co-exist in the same location. Furthermore, our study shows that the decoder design is critical in ensuring that the model has sufficient context for accurate detection and segmentation. We introduce a powerful ConvNeXt-UNet decoder that closes the performance gap between convolution- and transformerbased models. With ResNet50 backbone, our MaskConver achieves 53.6% PQ on the COCO panoptic val set, outperforming the modern convolution-based model, Panoptic FCN, by 9.3% as well as transformer-based models such as Mask2Former (+1.7% PQ) and kMaX-DeepLab (+0.6% PQ). Additionally, MaskConver with a MobileNet backbone reaches 37.2% PQ, improving over Panoptic-DeepLab by +6.4% under the same FLOPs/latency constraints. A further optimized version of MaskConver achieves 29.7% PQ, while running in real-time on mobile devices. The code and model weights will be publicly available
Two-Step Active Learning for Instance Segmentation with Uncertainty and Diversity Sampling
Sep 28, 2023


Training high-quality instance segmentation models requires an abundance of labeled images with instance masks and classifications, which is often expensive to procure. Active learning addresses this challenge by striving for optimum performance with minimal labeling cost by selecting the most informative and representative images for labeling. Despite its potential, active learning has been less explored in instance segmentation compared to other tasks like image classification, which require less labeling. In this study, we propose a post-hoc active learning algorithm that integrates uncertainty-based sampling with diversity-based sampling. Our proposed algorithm is not only simple and easy to implement, but it also delivers superior performance on various datasets. Its practical application is demonstrated on a real-world overhead imagery dataset, where it increases the labeling efficiency fivefold.
DaTaSeg: Taming a Universal Multi-Dataset Multi-Task Segmentation Model
Jun 02, 2023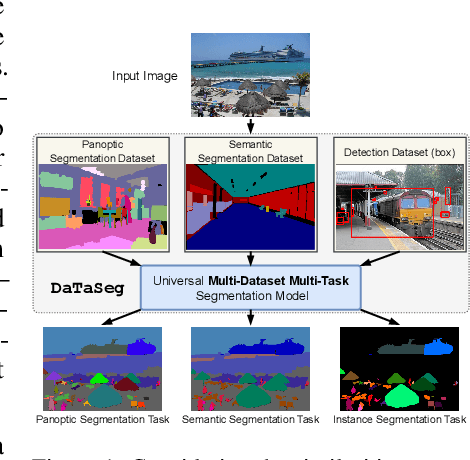
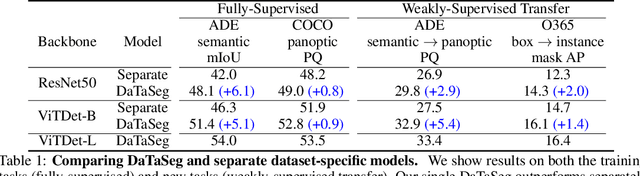
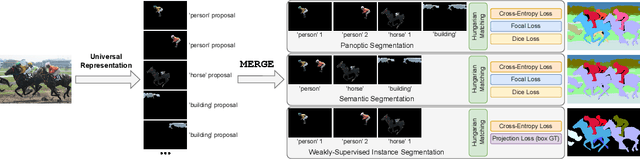
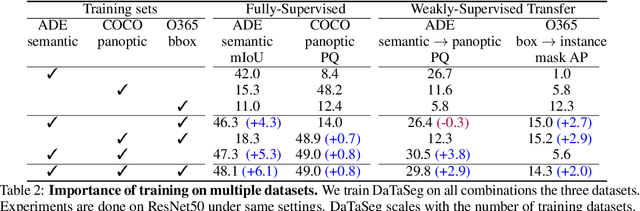
Observing the close relationship among panoptic, semantic and instance segmentation tasks, we propose to train a universal multi-dataset multi-task segmentation model: DaTaSeg.We use a shared representation (mask proposals with class predictions) for all tasks. To tackle task discrepancy, we adopt different merge operations and post-processing for different tasks. We also leverage weak-supervision, allowing our segmentation model to benefit from cheaper bounding box annotations. To share knowledge across datasets, we use text embeddings from the same semantic embedding space as classifiers and share all network parameters among datasets. We train DaTaSeg on ADE semantic, COCO panoptic, and Objects365 detection datasets. DaTaSeg improves performance on all datasets, especially small-scale datasets, achieving 54.0 mIoU on ADE semantic and 53.5 PQ on COCO panoptic. DaTaSeg also enables weakly-supervised knowledge transfer on ADE panoptic and Objects365 instance segmentation. Experiments show DaTaSeg scales with the number of training datasets and enables open-vocabulary segmentation through direct transfer. In addition, we annotate an Objects365 instance segmentation set of 1,000 images and will release it as a public benchmark.
Dilated SpineNet for Semantic Segmentation
Mar 23, 2021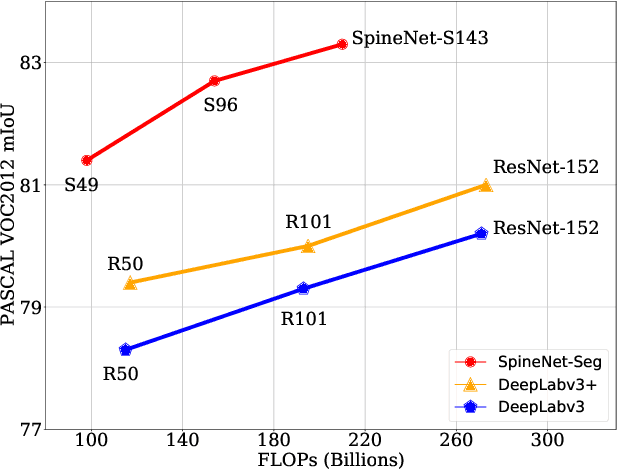
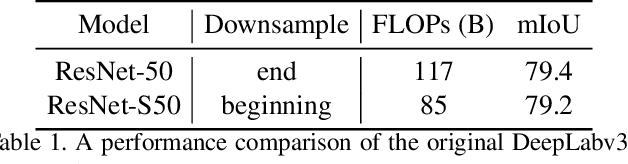

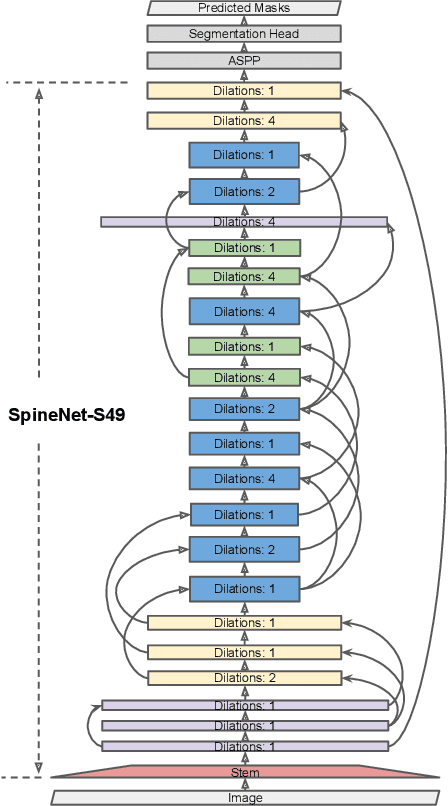
Scale-permuted networks have shown promising results on object bounding box detection and instance segmentation. Scale permutation and cross-scale fusion of features enable the network to capture multi-scale semantics while preserving spatial resolution. In this work, we evaluate this meta-architecture design on semantic segmentation - another vision task that benefits from high spatial resolution and multi-scale feature fusion at different network stages. By further leveraging dilated convolution operations, we propose SpineNet-Seg, a network discovered by NAS that is searched from the DeepLabv3 system. SpineNet-Seg is designed with a better scale-permuted network topology with customized dilation ratios per block on a semantic segmentation task. SpineNet-Seg models outperform the DeepLabv3/v3+ baselines at all model scales on multiple popular benchmarks in speed and accuracy. In particular, our SpineNet-S143+ model achieves the new state-of-the-art on the popular Cityscapes benchmark at 83.04% mIoU and attained strong performance on the PASCAL VOC2012 benchmark at 85.56% mIoU. SpineNet-Seg models also show promising results on a challenging Street View segmentation dataset. Code and checkpoints will be open-sourced.
Batch norm with entropic regularization turns deterministic autoencoders into generative models
Feb 25, 2020
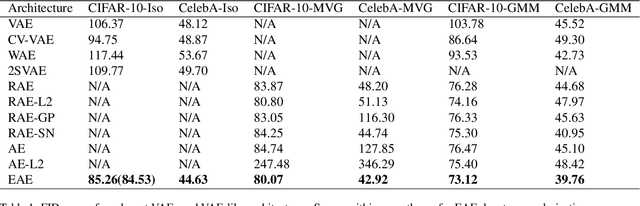


The variational autoencoder is a well defined deep generative model that utilizes an encoder-decoder framework where an encoding neural network outputs a non-deterministic code for reconstructing an input. The encoder achieves this by sampling from a distribution for every input, instead of outputting a deterministic code per input. The great advantage of this process is that it allows the use of the network as a generative model for sampling from the data distribution beyond provided samples for training. We show in this work that utilizing batch normalization as a source for non-determinism suffices to turn deterministic autoencoders into generative models on par with variational ones, so long as we add a suitable entropic regularization to the training objective.
MatrixNets: A New Scale and Aspect Ratio Aware Architecture for Object Detection
Jan 09, 2020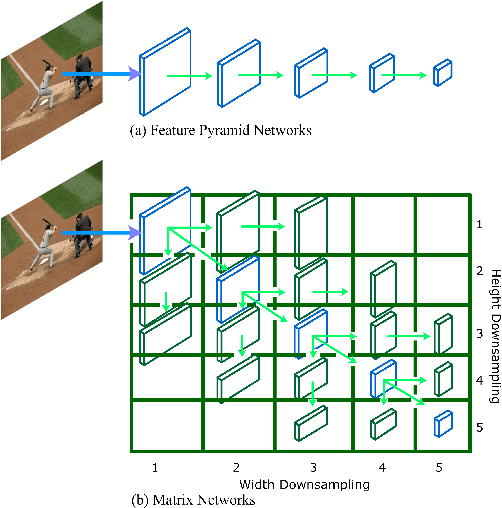
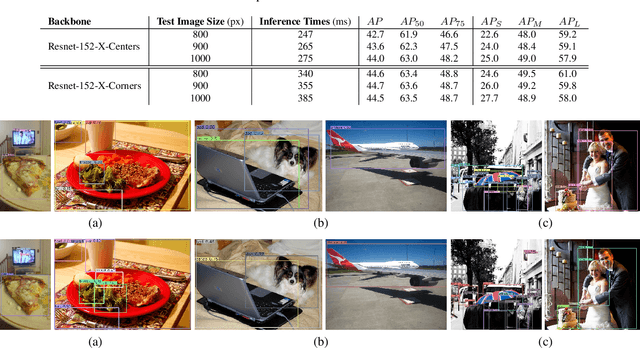
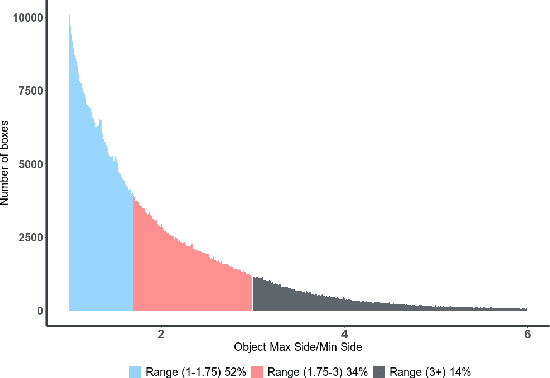
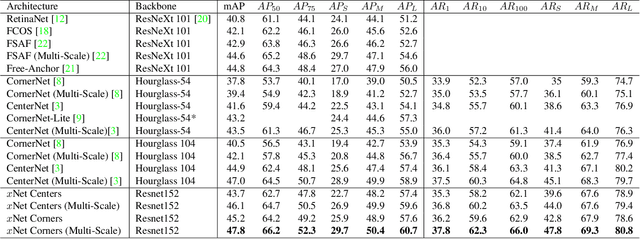
We present MatrixNets (xNets), a new deep architecture for object detection. xNets map objects with similar sizes and aspect ratios into many specialized layers, allowing xNets to provide a scale and aspect ratio aware architecture. We leverage xNets to enhance single-stage object detection frameworks. First, we apply xNets on anchor-based object detection, for which we predict object centers and regress the top-left and bottom-right corners. Second, we use MatrixNets for corner-based object detection by predicting top-left and bottom-right corners. Each corner predicts the center location of the object. We also enhance corner-based detection by replacing the embedding layer with center regression. Our final architecture achieves mAP of 47.8 on MS COCO, which is higher than its CornerNet counterpart by +5.6 mAP while also closing the gap between single-stage and two-stage detectors. The code is available at https://github.com/arashwan/matrixnet.
Matrix Nets: A New Deep Architecture for Object Detection
Aug 14, 2019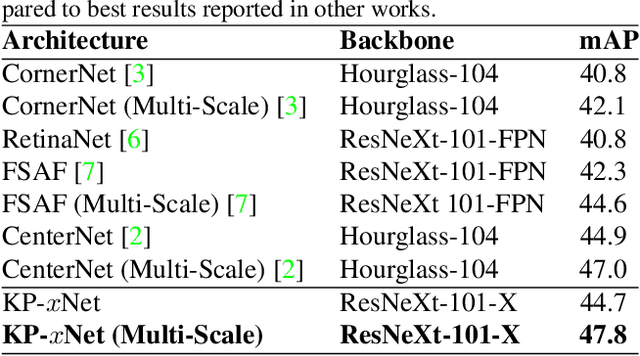
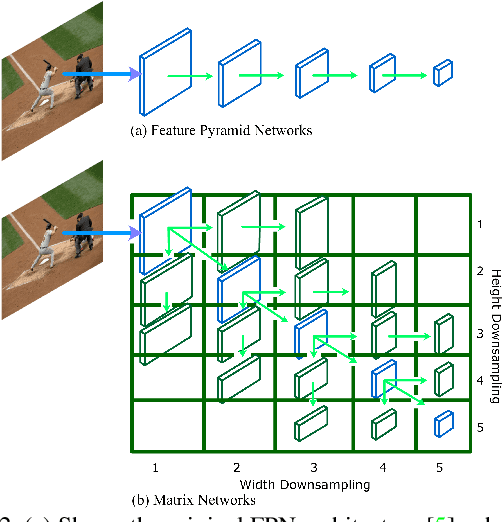
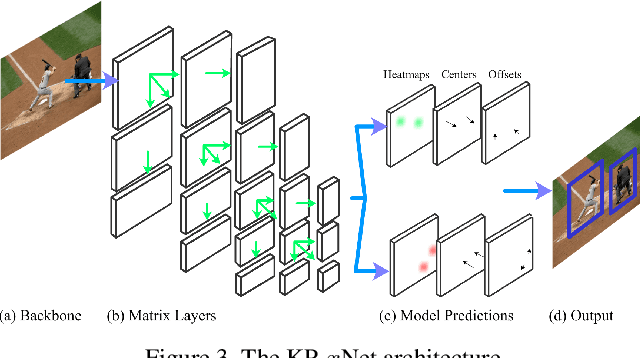
We present Matrix Nets (xNets), a new deep architecture for object detection. xNets map objects with different sizes and aspect ratios into layers where the sizes and the aspect ratios of the objects within their layers are nearly uniform. Hence, xNets provide a scale and aspect ratio aware architecture. We leverage xNets to enhance key-points based object detection. Our architecture achieves mAP of 47.8 on MS COCO, which is higher than any other single-shot detector while using half the number of parameters and training 3x faster than the next best architecture.