 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated QoR improvement in OpenROAD with coding agents
Jan 09, 2026EDA development and innovation has been constrained by scarcity of expert engineering resources. While leading LLMs have demonstrated excellent performance in coding and scientific reasoning tasks, their capacity to advance EDA technology itself has been largely untested. We present AuDoPEDA, an autonomous, repository-grounded coding system built atop OpenAI models and a Codex-class agent that reads OpenROAD, proposes research directions, expands them into implementation steps, and submits executable diffs. Our contributions include (i) a closed-loop LLM framework for EDA code changes; (ii) a task suite and evaluation protocol on OpenROAD for PPA-oriented improvements; and (iii) end-to-end demonstrations with minimal human oversight. Experiments in OpenROAD achieve routed wirelength reductions of up to 5.9%, and effective clock period reductions of up to 10.0%.
ORFS-agent: Tool-Using Agents for Chip Design Optimization
Jun 10, 2025Machine learning has been widely used to optimize complex engineering workflows across numerous domains. In the context of integrated circuit design, modern flows (e.g., going from a register-transfer level netlist to physical layouts) involve extensive configuration via thousands of parameters, and small changes to these parameters can have large downstream impacts on desired outcomes - namely design performance, power, and area. Recent advances in Large Language Models (LLMs) offer new opportunities for learning and reasoning within such high-dimensional optimization tasks. In this work, we introduce ORFS-agent, an LLM-based iterative optimization agent that automates parameter tuning in an open-source hardware design flow. ORFS-agent adaptively explores parameter configurations, demonstrating clear improvements over standard Bayesian optimization approaches in terms of resource efficiency and final design metrics. Our empirical evaluations on two different technology nodes and a range of circuit benchmarks indicate that ORFS-agent can improve both routed wirelength and effective clock period by over 13%, all while using 40% fewer optimization iterations. Moreover, by following natural language objectives to trade off certain metrics for others, ORFS-agent demonstrates a flexible and interpretable framework for multi-objective optimization. Crucially, RFS-agent is modular and model-agnostic, and can be plugged in to any frontier LLM without any further fine-tuning.
GraSS: Combining Graph Neural Networks with Expert Knowledge for SAT Solver Selection
May 17, 2024

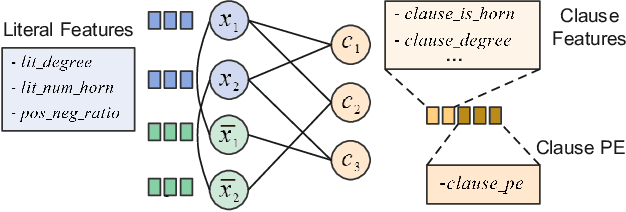

Boolean satisfiability (SAT) problems are routinely solved by SAT solvers in real-life applications, yet solving time can vary drastically between solvers for the same instance. This has motivated research into machine learning models that can predict, for a given SAT instance, which solver to select among several options. Existing SAT solver selection methods all rely on some hand-picked instance features, which are costly to compute and ignore the structural information in SAT graphs. In this paper we present GraSS, a novel approach for automatic SAT solver selection based on tripartite graph representations of instances and a heterogeneous graph neural network (GNN) model. While GNNs have been previously adopted in other SAT-related tasks, they do not incorporate any domain-specific knowledge and ignore the runtime variation introduced by different clause orders. We enrich the graph representation with domain-specific decisions, such as novel node feature design, positional encodings for clauses in the graph, a GNN architecture tailored to our tripartite graphs and a runtime-sensitive loss function. Through extensive experiments, we demonstrate that this combination of raw representations and domain-specific choices leads to improvements in runtime for a pool of seven state-of-the-art solvers on both an industrial circuit design benchmark, and on instances from the 20-year Anniversary Track of the 2022 SAT Competition.
Spectral Augmentations for Graph Contrastive Learning
Feb 06, 2023



Contrastive learning has emerged as a premier method for learning representations with or without supervision. Recent studies have shown its utility in graph representation learning for pre-training. Despite successes, the understanding of how to design effective graph augmentations that can capture structural properties common to many different types of downstream graphs remains incomplete. We propose a set of well-motivated graph transformation operations derived via graph spectral analysis to provide a bank of candidates when constructing augmentations for a graph contrastive objective, enabling contrastive learning to capture useful structural representation from pre-training graph datasets. We first present a spectral graph cropping augmentation that involves filtering nodes by applying thresholds to the eigenvalues of the leading Laplacian eigenvectors. Our second novel augmentation reorders the graph frequency components in a structural Laplacian-derived position graph embedding. Further, we introduce a method that leads to improved views of local subgraphs by performing alignment via global random walk embeddings. Our experimental results indicate consistent improvements in out-of-domain graph data transfer compared to state-of-the-art graph contrastive learning methods, shedding light on how to design a graph learner that is able to learn structural properties common to diverse graph types.
Generalizable Cross-Graph Embedding for GNN-based Congestion Prediction
Nov 10, 2021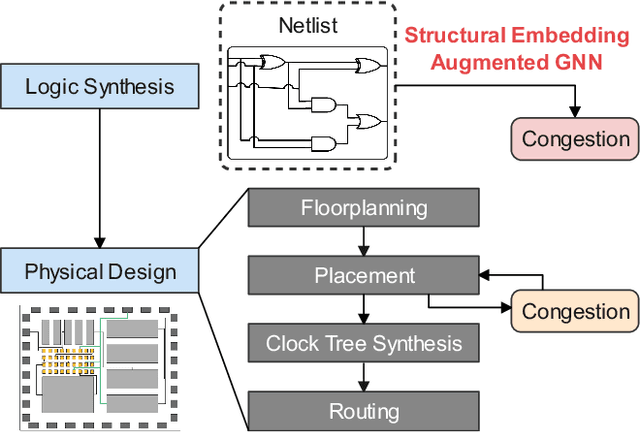
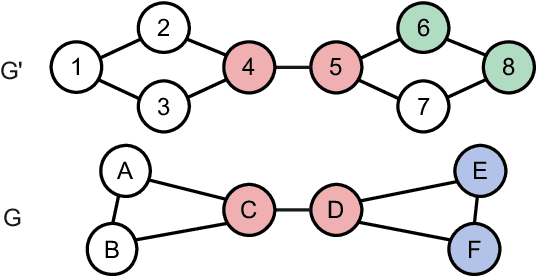
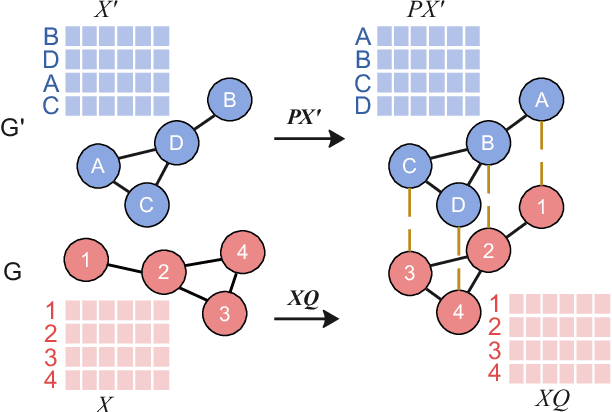
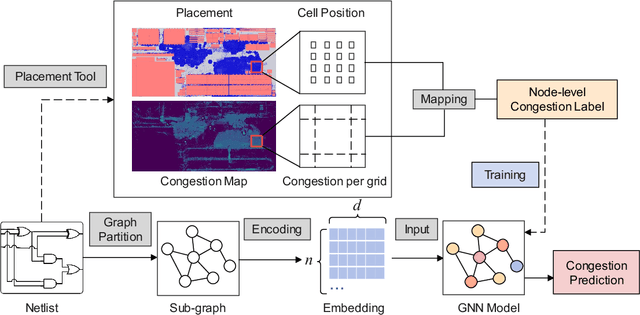
Presently with technology node scaling, an accurate prediction model at early design stages can significantly reduce the design cycle. Especially during logic synthesis, predicting cell congestion due to improper logic combination can reduce the burden of subsequent physical implementations. There have been attempts using Graph Neural Network (GNN) techniques to tackle congestion prediction during the logic synthesis stage. However, they require informative cell features to achieve reasonable performance since the core idea of GNNs is built on the message passing framework, which would be impractical at the early logic synthesis stage. To address this limitation, we propose a framework that can directly learn embeddings for the given netlist to enhance the quality of our node features. Popular random-walk based embedding methods such as Node2vec, LINE, and DeepWalk suffer from the issue of cross-graph alignment and poor generalization to unseen netlist graphs, yielding inferior performance and costing significant runtime. In our framework, we introduce a superior alternative to obtain node embeddings that can generalize across netlist graphs using matrix factorization methods. We propose an efficient mini-batch training method at the sub-graph level that can guarantee parallel training and satisfy the memory restriction for large-scale netlists. We present results utilizing open-source EDA tools such as DREAMPLACE and OPENROAD frameworks on a variety of openly available circuits. By combining the learned embedding on top of the netlist with the GNNs, our method improves prediction performance, generalizes to new circuit lines, and is efficient in training, potentially saving over $90 \%$ of runtime.
Batch norm with entropic regularization turns deterministic autoencoders into generative models
Feb 25, 2020
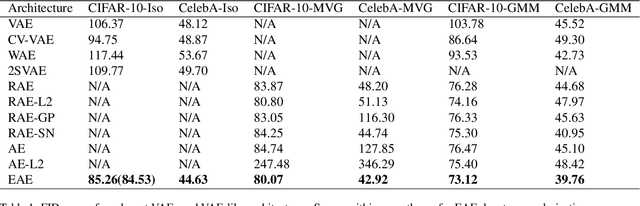


The variational autoencoder is a well defined deep generative model that utilizes an encoder-decoder framework where an encoding neural network outputs a non-deterministic code for reconstructing an input. The encoder achieves this by sampling from a distribution for every input, instead of outputting a deterministic code per input. The great advantage of this process is that it allows the use of the network as a generative model for sampling from the data distribution beyond provided samples for training. We show in this work that utilizing batch normalization as a source for non-determinism suffices to turn deterministic autoencoders into generative models on par with variational ones, so long as we add a suitable entropic regularization to the training objective.