 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVL-Calibration: Decoupled Confidence Calibration for Large Vision-Language Models Reasoning
Apr 10, 2026Large Vision Language Models (LVLMs) achieve strong multimodal reasoning but frequently exhibit hallucinations and incorrect responses with high certainty, which hinders their usage in high-stakes domains. Existing verbalized confidence calibration methods, largely developed for text-only LLMs, typically optimize a single holistic confidence score using binary answer-level correctness. This design is mismatched to LVLMs: an incorrect prediction may arise from perceptual failures or from reasoning errors given correct perception, and a single confidence conflates these sources while visual uncertainty is often dominated by language priors. To address these issues, we propose VL-Calibration, a reinforcement learning framework that explicitly decouples confidence into visual and reasoning confidence. To supervise visual confidence without ground-truth perception labels, we introduce an intrinsic visual certainty estimation that combines (i) visual grounding measured by KL-divergence under image perturbations and (ii) internal certainty measured by token entropy. We further propose token-level advantage reweighting to focus optimization on tokens based on visual certainty, suppressing ungrounded hallucinations while preserving valid perception. Experiments on thirteen benchmarks show that VL-Calibration effectively improves calibration while boosting visual reasoning accuracy, and it generalizes to out-of-distribution benchmarks across model scales and architectures.
REVEALER: Reinforcement-Guided Visual Reasoning for Element-Level Text-Image Alignment Evaluation
Dec 29, 2025Evaluating the alignment between textual prompts and generated images is critical for ensuring the reliability and usability of text-to-image (T2I) models. However, most existing evaluation methods rely on coarse-grained metrics or static QA pipelines, which lack fine-grained interpretability and struggle to reflect human preferences. To address this, we propose REVEALER, a unified framework for element-level alignment evaluation based on reinforcement-guided visual reasoning. Adopting a structured "grounding-reasoning-conclusion" paradigm, our method enables Multimodal Large Language Models (MLLMs) to explicitly localize semantic elements and derive interpretable alignment judgments. We optimize the model via Group Relative Policy Optimization(GRPO) using a composite reward function that incorporates structural format, grounding accuracy, and alignment fidelity. Extensive experiments across four benchmarks-EvalMuse-40K, RichHF, MHaluBench, and GenAI-Bench-demonstrate that REVEALER achieves state-of-the-art performance. Our approach consistently outperforms both strong proprietary models and supervised baselines while demonstrating superior inference efficiency compared to existing iterative visual reasoning methods.
Fast-Slow Thinking for Large Vision-Language Model Reasoning
Apr 25, 2025Recent advances in large vision-language models (LVLMs) have revealed an \textit{overthinking} phenomenon, where models generate verbose reasoning across all tasks regardless of questions. To address this issue, we present \textbf{FAST}, a novel \textbf{Fa}st-\textbf{S}low \textbf{T}hinking framework that dynamically adapts reasoning depth based on question characteristics. Through empirical analysis, we establish the feasibility of fast-slow thinking in LVLMs by investigating how response length and data distribution affect performance. We develop FAST-GRPO with three components: model-based metrics for question characterization, an adaptive thinking reward mechanism, and difficulty-aware KL regularization. Experiments across seven reasoning benchmarks demonstrate that FAST achieves state-of-the-art accuracy with over 10\% relative improvement compared to the base model, while reducing token usage by 32.7-67.3\% compared to previous slow-thinking approaches, effectively balancing reasoning length and accuracy.
A Comprehensive Survey of Datasets, Theories, Variants, and Applications in Direct Preference Optimization
Oct 21, 2024With the rapid advancement of large language models (LLMs), aligning policy models with human preferences has become increasingly critical. Direct Preference Optimization (DPO) has emerged as a promising approach for alignment, acting as an RL-free alternative to Reinforcement Learning from Human Feedback (RLHF). Despite DPO's various advancements and inherent limitations, an in-depth review of these aspects is currently lacking in the literature. In this work, we present a comprehensive review of the challenges and opportunities in DPO, covering theoretical analyses, variants, relevant preference datasets, and applications. Specifically, we categorize recent studies on DPO based on key research questions to provide a thorough understanding of DPO's current landscape. Additionally, we propose several future research directions to offer insights on model alignment for the research community.
MARS: Mixture of Auto-Regressive Models for Fine-grained Text-to-image Synthesis
Jul 11, 2024



Auto-regressive models have made significant progress in the realm of language generation, yet they do not perform on par with diffusion models in the domain of image synthesis. In this work, we introduce MARS, a novel framework for T2I generation that incorporates a specially designed Semantic Vision-Language Integration Expert (SemVIE). This innovative component integrates pre-trained LLMs by independently processing linguistic and visual information, freezing the textual component while fine-tuning the visual component. This methodology preserves the NLP capabilities of LLMs while imbuing them with exceptional visual understanding. Building upon the powerful base of the pre-trained Qwen-7B, MARS stands out with its bilingual generative capabilities corresponding to both English and Chinese language prompts and the capacity for joint image and text generation. The flexibility of this framework lends itself to migration towards any-to-any task adaptability. Furthermore, MARS employs a multi-stage training strategy that first establishes robust image-text alignment through complementary bidirectional tasks and subsequently concentrates on refining the T2I generation process, significantly augmenting text-image synchrony and the granularity of image details. Notably, MARS requires only 9% of the GPU days needed by SD1.5, yet it achieves remarkable results across a variety of benchmarks, illustrating the training efficiency and the potential for swift deployment in various applications.
GraSS: Combining Graph Neural Networks with Expert Knowledge for SAT Solver Selection
May 17, 2024

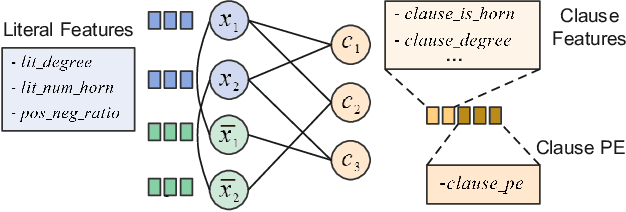

Boolean satisfiability (SAT) problems are routinely solved by SAT solvers in real-life applications, yet solving time can vary drastically between solvers for the same instance. This has motivated research into machine learning models that can predict, for a given SAT instance, which solver to select among several options. Existing SAT solver selection methods all rely on some hand-picked instance features, which are costly to compute and ignore the structural information in SAT graphs. In this paper we present GraSS, a novel approach for automatic SAT solver selection based on tripartite graph representations of instances and a heterogeneous graph neural network (GNN) model. While GNNs have been previously adopted in other SAT-related tasks, they do not incorporate any domain-specific knowledge and ignore the runtime variation introduced by different clause orders. We enrich the graph representation with domain-specific decisions, such as novel node feature design, positional encodings for clauses in the graph, a GNN architecture tailored to our tripartite graphs and a runtime-sensitive loss function. Through extensive experiments, we demonstrate that this combination of raw representations and domain-specific choices leads to improvements in runtime for a pool of seven state-of-the-art solvers on both an industrial circuit design benchmark, and on instances from the 20-year Anniversary Track of the 2022 SAT Competition.
Detecting and Mitigating Hallucination in Large Vision Language Models via Fine-Grained AI Feedback
Apr 22, 2024



The rapidly developing Large Vision Language Models (LVLMs) have shown notable capabilities on a range of multi-modal tasks, but still face the hallucination phenomena where the generated texts do not align with the given contexts, significantly restricting the usages of LVLMs. Most previous work detects and mitigates hallucination at the coarse-grained level or requires expensive annotation (e.g., labeling by proprietary models or human experts). To address these issues, we propose detecting and mitigating hallucinations in LVLMs via fine-grained AI feedback. The basic idea is that we generate a small-size sentence-level hallucination annotation dataset by proprietary models, whereby we train a hallucination detection model which can perform sentence-level hallucination detection, covering primary hallucination types (i.e., object, attribute, and relationship). Then, we propose a detect-then-rewrite pipeline to automatically construct preference dataset for training hallucination mitigating model. Furthermore, we propose differentiating the severity of hallucinations, and introducing a Hallucination Severity-Aware Direct Preference Optimization (HSA-DPO) for mitigating hallucination in LVLMs by incorporating the severity of hallucinations into preference learning. Extensive experiments demonstrate the effectiveness of our method.
HDLdebugger: Streamlining HDL debugging with Large Language Models
Mar 18, 2024In the domain of chip design, Hardware Description Languages (HDLs) play a pivotal role. However, due to the complex syntax of HDLs and the limited availability of online resources, debugging HDL codes remains a difficult and time-intensive task, even for seasoned engineers. Consequently, there is a pressing need to develop automated HDL code debugging models, which can alleviate the burden on hardware engineers. Despite the strong capabilities of Large Language Models (LLMs) in generating, completing, and debugging software code, their utilization in the specialized field of HDL debugging has been limited and, to date, has not yielded satisfactory results. In this paper, we propose an LLM-assisted HDL debugging framework, namely HDLdebugger, which consists of HDL debugging data generation via a reverse engineering approach, a search engine for retrieval-augmented generation, and a retrieval-augmented LLM fine-tuning approach. Through the integration of these components, HDLdebugger can automate and streamline HDL debugging for chip design. Our comprehensive experiments, conducted on an HDL code dataset sourced from Huawei, reveal that HDLdebugger outperforms 13 cutting-edge LLM baselines, displaying exceptional effectiveness in HDL code debugging.
IB-Net: Initial Branch Network for Variable Decision in Boolean Satisfiability
Mar 06, 2024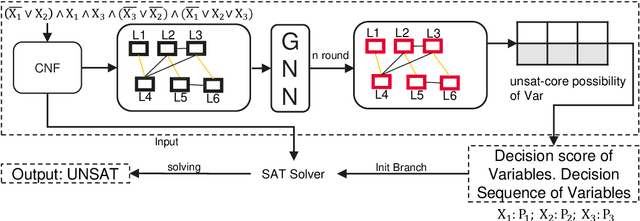
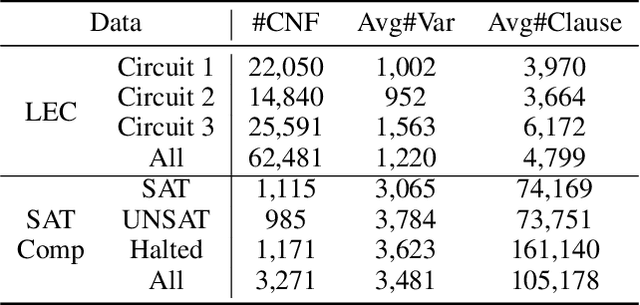
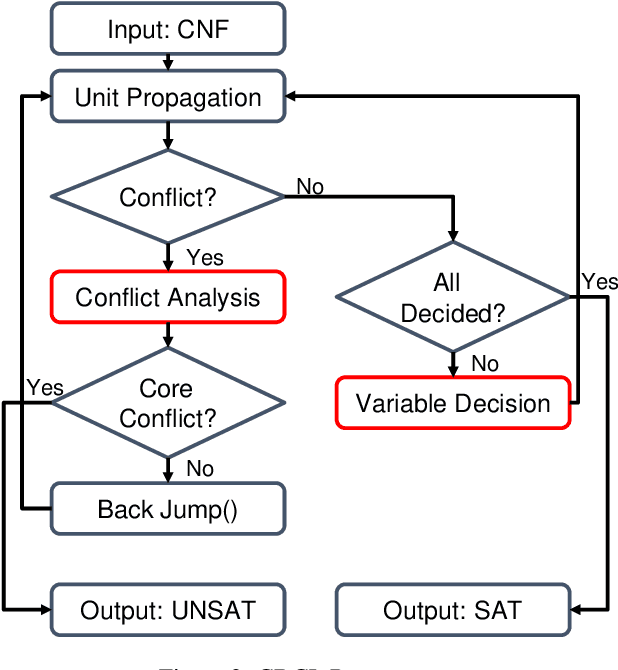
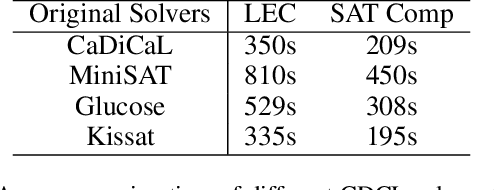
Boolean Satisfiability problems are vital components in Electronic Design Automation, particularly within the Logic Equivalence Checking process. Currently, SAT solvers are employed for these problems and neural network is tried as assistance to solvers. However, as SAT problems in the LEC context are distinctive due to their predominantly unsatisfiability nature and a substantial proportion of UNSAT-core variables, existing neural network assistance has proven unsuccessful in this specialized domain. To tackle this challenge, we propose IB-Net, an innovative framework utilizing graph neural networks and novel graph encoding techniques to model unsatisfiable problems and interact with state-of-the-art solvers. Extensive evaluations across solvers and datasets demonstrate IB-Net's acceleration, achieving an average runtime speedup of 5.0% on industrial data and 8.3% on SAT competition data empirically. This breakthrough advances efficient solving in LEC workflows.
Vertex-reinforced Random Walk for Network Embedding
Feb 11, 2020
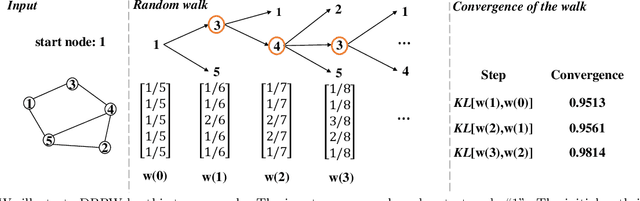
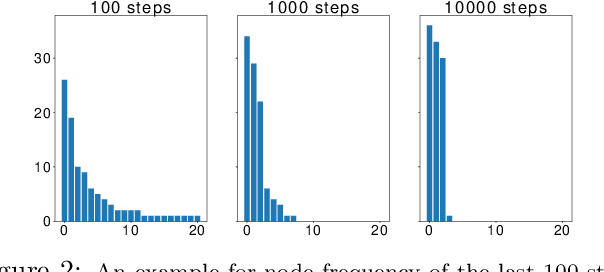
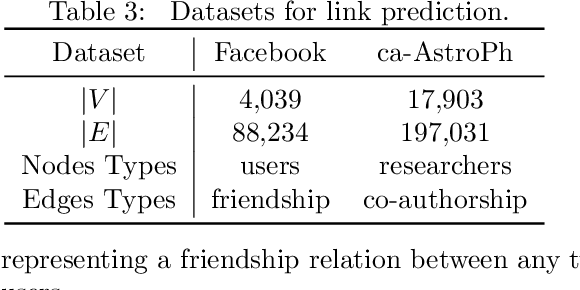
In this paper, we study the fundamental problem of random walk for network embedding. We propose to use non-Markovian random walk, variants of vertex-reinforced random walk (VRRW), to fully use the history of a random walk path. To solve the getting stuck problem of VRRW, we introduce an exploitation-exploration mechanism to help the random walk jump out of the stuck set. The new random walk algorithms share the same convergence property of VRRW and thus can be used to learn stable network embeddings. Experimental results on two link prediction benchmark datasets and three node classification benchmark datasets show that our proposed approach reinforce2vec can outperform state-of-the-art random walk based embedding methods by a large margin.