 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Balanced Neuro-Symbolic Approach for Commonsense Abductive Logic
Jan 26, 2026Although Large Language Models (LLMs) have demonstrated impressive formal reasoning abilities, they often break down when problems require complex proof planning. One promising approach for improving LLM reasoning abilities involves translating problems into formal logic and using a logic solver. Although off-the-shelf logic solvers are in principle substantially more efficient than LLMs at logical reasoning, they assume that all relevant facts are provided in a question and are unable to deal with missing commonsense relations. In this work, we propose a novel method that uses feedback from the logic solver to augment a logic problem with commonsense relations provided by the LLM, in an iterative manner. This involves a search procedure through potential commonsense assumptions to maximize the chance of finding useful facts while keeping cost tractable. On a collection of pure-logical reasoning datasets, from which some commonsense information has been removed, our method consistently achieves considerable improvements over existing techniques, demonstrating the value in balancing neural and symbolic elements when working in human contexts.
InnerThoughts: Disentangling Representations and Predictions in Large Language Models
Jan 29, 2025



Large language models (LLMs) contain substantial factual knowledge which is commonly elicited by multiple-choice question-answering prompts. Internally, such models process the prompt through multiple transformer layers, building varying representations of the problem within its hidden states. Ultimately, however, only the hidden state corresponding to the final layer and token position are used to predict the answer label. In this work, we propose instead to learn a small separate neural network predictor module on a collection of training questions, that take the hidden states from all the layers at the last temporal position as input and outputs predictions. In effect, such a framework disentangles the representational abilities of LLMs from their predictive abilities. On a collection of hard benchmarks, our method achieves considerable improvements in performance, sometimes comparable to supervised fine-tuning procedures, but at a fraction of the computational cost.
HardCore Generation: Generating Hard UNSAT Problems for Data Augmentation
Sep 27, 2024Efficiently determining the satisfiability of a boolean equation -- known as the SAT problem for brevity -- is crucial in various industrial problems. Recently, the advent of deep learning methods has introduced significant potential for enhancing SAT solving. However, a major barrier to the advancement of this field has been the scarcity of large, realistic datasets. The majority of current public datasets are either randomly generated or extremely limited, containing only a few examples from unrelated problem families. These datasets are inadequate for meaningful training of deep learning methods. In light of this, researchers have started exploring generative techniques to create data that more accurately reflect SAT problems encountered in practical situations. These methods have so far suffered from either the inability to produce challenging SAT problems or time-scalability obstacles. In this paper we address both by identifying and manipulating the key contributors to a problem's ``hardness'', known as cores. Although some previous work has addressed cores, the time costs are unacceptably high due to the expense of traditional heuristic core detection techniques. We introduce a fast core detection procedure that uses a graph neural network. Our empirical results demonstrate that we can efficiently generate problems that remain hard to solve and retain key attributes of the original example problems. We show via experiment that the generated synthetic SAT problems can be used in a data augmentation setting to provide improved prediction of solver runtimes.
GraSS: Combining Graph Neural Networks with Expert Knowledge for SAT Solver Selection
May 17, 2024

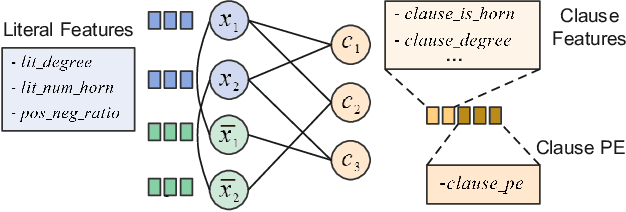

Boolean satisfiability (SAT) problems are routinely solved by SAT solvers in real-life applications, yet solving time can vary drastically between solvers for the same instance. This has motivated research into machine learning models that can predict, for a given SAT instance, which solver to select among several options. Existing SAT solver selection methods all rely on some hand-picked instance features, which are costly to compute and ignore the structural information in SAT graphs. In this paper we present GraSS, a novel approach for automatic SAT solver selection based on tripartite graph representations of instances and a heterogeneous graph neural network (GNN) model. While GNNs have been previously adopted in other SAT-related tasks, they do not incorporate any domain-specific knowledge and ignore the runtime variation introduced by different clause orders. We enrich the graph representation with domain-specific decisions, such as novel node feature design, positional encodings for clauses in the graph, a GNN architecture tailored to our tripartite graphs and a runtime-sensitive loss function. Through extensive experiments, we demonstrate that this combination of raw representations and domain-specific choices leads to improvements in runtime for a pool of seven state-of-the-art solvers on both an industrial circuit design benchmark, and on instances from the 20-year Anniversary Track of the 2022 SAT Competition.
Substituting Data Annotation with Balanced Updates and Collective Loss in Multi-label Text Classification
Sep 24, 2023Multi-label text classification (MLTC) is the task of assigning multiple labels to a given text, and has a wide range of application domains. Most existing approaches require an enormous amount of annotated data to learn a classifier and/or a set of well-defined constraints on the label space structure, such as hierarchical relations which may be complicated to provide as the number of labels increases. In this paper, we study the MLTC problem in annotation-free and scarce-annotation settings in which the magnitude of available supervision signals is linear to the number of labels. Our method follows three steps, (1) mapping input text into a set of preliminary label likelihoods by natural language inference using a pre-trained language model, (2) calculating a signed label dependency graph by label descriptions, and (3) updating the preliminary label likelihoods with message passing along the label dependency graph, driven with a collective loss function that injects the information of expected label frequency and average multi-label cardinality of predictions. The experiments show that the proposed framework achieves effective performance under low supervision settings with almost imperceptible computational and memory overheads added to the usage of pre-trained language model outperforming its initial performance by 70\% in terms of example-based F1 score.