 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding the Design Principles of Link Prediction in Directed Settings
Feb 20, 2025



Link prediction is a widely studied task in Graph Representation Learning (GRL) for modeling relational data. The early theories in GRL were based on the assumption of a symmetric adjacency matrix, reflecting an undirected setting. As a result, much of the following state-of-the-art research has continued to operate under this symmetry assumption, even though real-world data often involve crucial information conveyed through the direction of relationships. This oversight limits the ability of these models to fully capture the complexity of directed interactions. In this paper, we focus on the challenge of directed link prediction by evaluating key heuristics that have been successful in undirected settings. We propose simple but effective adaptations of these heuristics to the directed link prediction task and demonstrate that these modifications produce competitive performance compared to the leading Graph Neural Networks (GNNs) originally designed for undirected graphs. Through an extensive set of experiments, we derive insights that inform the development of a novel framework for directed link prediction, which not only surpasses baseline methods but also outperforms state-of-the-art GNNs on multiple benchmarks.
Substituting Data Annotation with Balanced Updates and Collective Loss in Multi-label Text Classification
Sep 24, 2023Multi-label text classification (MLTC) is the task of assigning multiple labels to a given text, and has a wide range of application domains. Most existing approaches require an enormous amount of annotated data to learn a classifier and/or a set of well-defined constraints on the label space structure, such as hierarchical relations which may be complicated to provide as the number of labels increases. In this paper, we study the MLTC problem in annotation-free and scarce-annotation settings in which the magnitude of available supervision signals is linear to the number of labels. Our method follows three steps, (1) mapping input text into a set of preliminary label likelihoods by natural language inference using a pre-trained language model, (2) calculating a signed label dependency graph by label descriptions, and (3) updating the preliminary label likelihoods with message passing along the label dependency graph, driven with a collective loss function that injects the information of expected label frequency and average multi-label cardinality of predictions. The experiments show that the proposed framework achieves effective performance under low supervision settings with almost imperceptible computational and memory overheads added to the usage of pre-trained language model outperforming its initial performance by 70\% in terms of example-based F1 score.
Multi-relation Message Passing for Multi-label Text Classification
Feb 10, 2022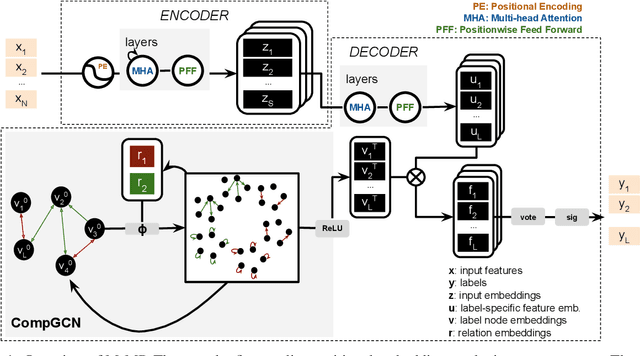

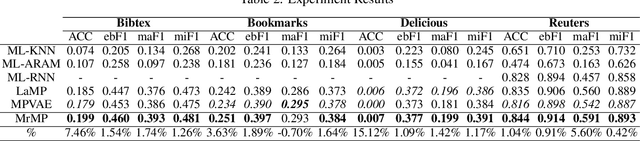
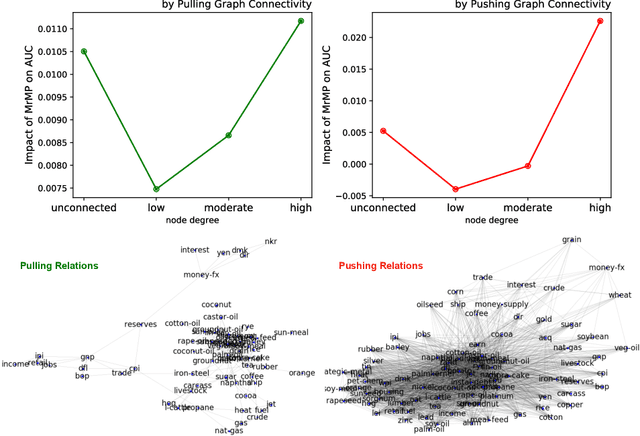
A well-known challenge associated with the multi-label classification problem is modelling dependencies between labels. Most attempts at modelling label dependencies focus on co-occurrences, ignoring the valuable information that can be extracted by detecting label subsets that rarely occur together. For example, consider customer product reviews; a product probably would not simultaneously be tagged by both "recommended" (i.e., reviewer is happy and recommends the product) and "urgent" (i.e., the review suggests immediate action to remedy an unsatisfactory experience). Aside from the consideration of positive and negative dependencies, the direction of a relationship should also be considered. For a multi-label image classification problem, the "ship" and "sea" labels have an obvious dependency, but the presence of the former implies the latter much more strongly than the other way around. These examples motivate the modelling of multiple types of bi-directional relationships between labels. In this paper, we propose a novel method, entitled Multi-relation Message Passing (MrMP), for the multi-label classification problem. Experiments on benchmark multi-label text classification datasets show that the MrMP module yields similar or superior performance compared to state-of-the-art methods. The approach imposes only minor additional computational and memory overheads.